CNN和RNN的不同
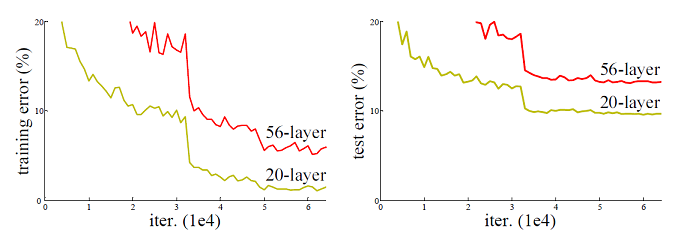
在前面我们讲到了DNN,以及DNN的特例CNN的模型和前向反向传播算法,这些算法都是前向反馈的,模型的输出和模型本身没有关联关系。循环神经网络(Recurrent Neural Networks ,以下简称RNN)的输出和模型间有反馈,它广泛的用于自然语言处理中的语音识别,手写书别以及机器翻译等领域。
在前面讲到的DNN和CNN中,训练样本的输入和输出是比较的确定的。但是有一类问题DNN和CNN不好解决,就是训练样本输入是连续的序列,且序列的长短不一,比如基于时间的序列:一段段连续的语音,一段段连续的手写文字。这些序列比较长,且长度不一,比较难直接的拆分成一个个独立的样本来通过DNN/CNN进行训练。
而对于这类问题,RNN则比较的擅长。那么RNN是怎么做到的呢?RNN假设我们的样本是基于序列的。比如是从序列索引1到序列索引$\tau$的。对于这其中的任意序列索引号$t$,它对应的输入是对应的样本序列中的$x^{(t)}$。而模型在序列索引号$t$位置的隐藏状态$h^{(t)}$,则由$x^{(t)}$和在$t-1$位置的隐藏状态$h^{(t-1)}$共同决定。在任意序列索引号$t$,我们也有对应的模型预测输出$o^{(t)}$。通过预测输出$o^{(t)}$和训练序列真实输出$y^{(t)}$,以及损失函数$L^{(t)}$,我们就可以用DNN类似的方法来训练模型,接着用来预测测试序列中的一些位置的输出。