基本概念
mAP: mean Average Precision,即各类别AP的平均值
AP: PR曲线下面积,后文会详细讲解
PR曲线: Precision-Recall曲线
Precision: TP / (TP + FP)
本篇文章主要参考了TensorRT(5)-INT8校准原理,并添加了一些自己的见解。
现有的深度学习框架,如Pytorch、Tensorflow在训练一个深度神经网络时,往往都会使用 float 32(Full Precise ,简称FP32)的数据精度来表示,权值、偏置、激活值等。若一个网络很深的话,比如像VGG,ResNet这种,网络参数是极其多的,计算量就更多了(比如VGG 19.6 billion FLOPS, ResNet-152 11.3 billion FLOPS)。如果多的计算量,如果都采用FP32进行推理,对于嵌入式设备来说计算量是不能接受的。解决此问题主要有两种方案:
下面从经验上分析低精度推理的可行性。
狭义上的face localisation的定义是传统意义上的face detection。广义上的face localisation包括了face detection、face alignment、pixel-wise face parsing、3D dense correspondence regression。
对于C/C++程序,编译主要分为三个步骤:
*.i文件*.s的汇编文件;通常情况下,对函数库的链接是放在编译时期(compile time)完成的。所有相关的对象文件 (object file)与牵涉到的函数库(library)被链接合成一个可执行文件 (executable file)。 静态链接和动态链接两者最大的区别就在于链接的时机不一样,静态链接是在形成可执行程序前,而动态链接的进行则是在程序执行时。下面来详细介绍这两种链接方式。
DALI库是一个用于数据预处理以及数据读取的第三方加速库。最近因为调用这个库的时候会出问题,所以重新编译了一下,这里记录下编译的过程。
首先,DALI库的官方地址,官方文档地址,因为我这里使用的是旧版本的DALI库——0.11版本,其编译文档可以在这里找到,一般来说,直接按照流程编译是没有问题的,但是对于没有Root权限情况下的编译,就有点麻烦了。下面介绍一下:
首先,下面的编译条件要满足,尤其是对于GCC版本,我编译的使用使用了GCC4.9.2。
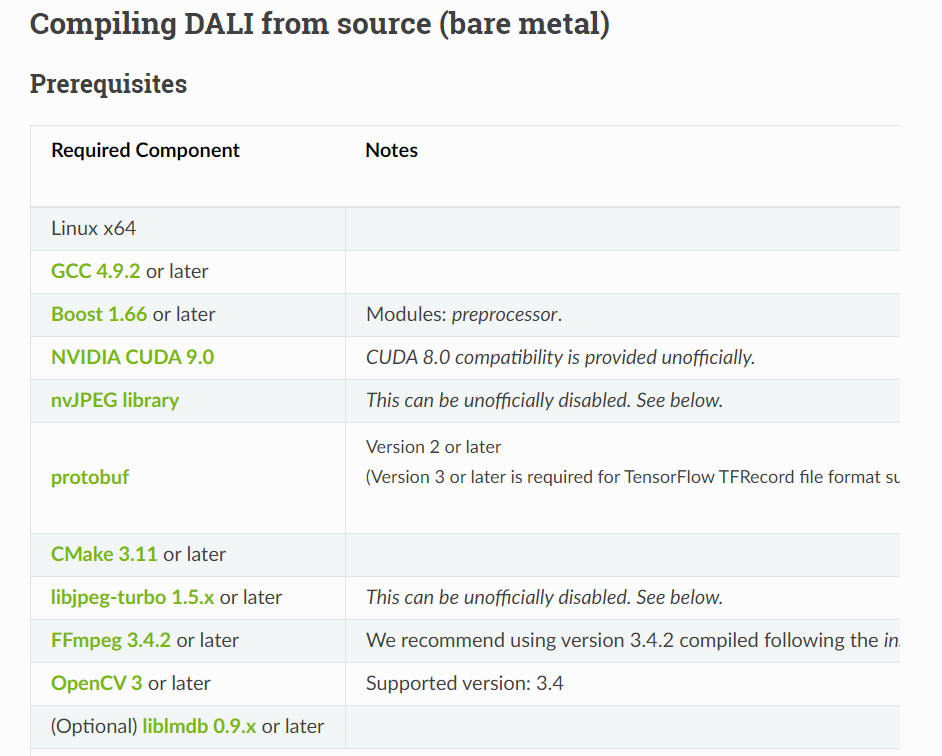
值得注意的是,对于上面的编译条件,有一个通常不满足,那就是FFmpeg库,按照官方文档里面的指示,可以从这里下载FFmpeg安装包,我这里将安装包放到了/data2/zhaodali/software下,然后执行下面操作:
本篇文章主要参考了TensorRT(1)-介绍-使用-安装,并加上了一些自己的理解。
TensorRT是一个高性能的深度学习推理(Inference)优化器,可以为深度学习应用提供低延迟、高吞吐率的部署推理。TensorRT 之前称为GIE。
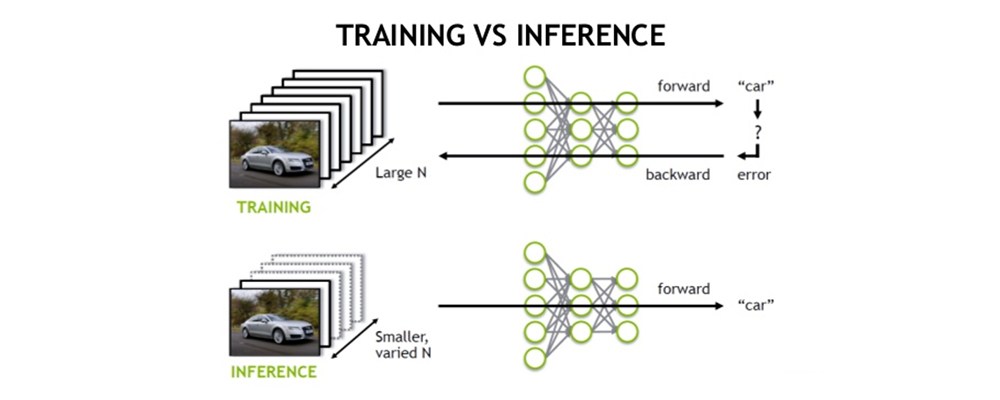
由上图可以很清楚的看出,训练(training)和 推理(inference)的区别:
最近稍微学习了一下TensorRT,这里参考这很多博客,主要参考了如何使用TensorRT对训练好的PyTorch模型进行加速?。然后加上自己的一些注释。
现在训练深度学习模型主流的框架有TensorFlow,Pytorch,mxnet,caffe等。这个贴子只涉及Pytorch,对于TensorFlow的话,可以参考TensorRT部署深度学习模型,这个帖子是C++如何部署TensorRT。其实原理都是一样的,对于TensorFlow模型,需要把pb模型转化为uff模型;对于Pytorch模型,需要把pth模型转化为onnx模型;对于caffe模型,则不需要转化,因为tensorRT是可以直接读取caffe模型的;mxnet模型也是需要转化为onnx的。
对于TensorRT的安装,这里就不赘述了,之前我的博客有介绍过。
Python环境下Pytorch模型转化为TensorRT有两种路径,一种是先把Pytorch的pt模型转化为onnx,然后再转化为TensorRT;另一种是直接把pytorch的pt模型转成TensorRT。
最近踩了一下从onnx导出到TensorRT的坑,在这记录一下。
从官方地址下载合适版本的TensorRT,例如我这里下载的就是TensorRT-7.0.0.11.CentOS-7.6.x86_64-gnu.cuda-10.2.cudnn7.6.tar.gz。
1 | # 解压缩 |
详细的导出流程其实看官方文档就可以了。这里我主要是说明的是我感兴趣的几个参数以及我自己的一些疑惑。
export_params:该参数默认为True,也就是会导出训练好的权重;若设置为False,则导出的是没有训练过的模型。
verbose:默认为False,若设置为True,则会打印导出onnx时的一些日志,便于分析网络结构。
opset_version:对于1.5.0的Pytorch,默认仍然是9,也就是对应当前onnx的最稳定的版本。
以下大部分内容来源于Pytorch源码编译简明指南,并加上自己踩得一些坑。
编译首先是要获取源代码。
从官方获取源代码是最好的方式,从Pytorch的github官网可以下载最新的代码。
记住,从官方克隆最新的代码的时候要加入recursive这个参数,因为Pytorch本身需要很多的第三方库参与编译: