本文是在centos7的 LAMP环境下搭建的wordpress!
LAMP环境就是Linux+Apache+Mysql+PHP。因此目前Mysql被MariaDB所代替。MariaDB的目的是完全兼容MySQL,包括API和命令行,使之能轻松成为MySQL的代替品
安装Apache Web服务器
1 | sudo yum install httpd |
安装完成之后我们就可以运行以下命令启动Apache服务器了:
1 | sudo systemctl start httpd.service |
在ubuntu 下利用matplotlib 绘图的时候,图像上中文无法显示。以下是我的解决办法:
注意下面复制字体路径与配置文件路径跟Python环境路径有关
1. 下载中文字体simhei.ttf, 网址为http://fontzone.net/download/simhei
或者直接从Windows 拷贝
2. 复制字体
2020年10月8日更新,更新内容如下:
更新boot repair disk
更新再生
更新U盘写入器,采用caocaoff大大的写入器,表示感谢
更新Win10 64内核为FirPE,官方网站在这里https://firpe.cn/page-247
更新grub文件管理器、部分PE软件
百度网盘地址(提取码:mp04 )
注意:下面的一键恢复与一键备份慎用,一键恢复是有风险的!!!!请备份好数据!!!貌似会将所有的是数据删除,然后再恢复!!!详细请看 http://bbs.wuyou.net/forum.php?m … 8040&extra=&page=14 这里的讨论。
Makefile 是和 make 命令一起配合使用的.
很多大型项目的编译都是通过 Makefile 来组织的, 如果没有 Makefile, 那很多项目中各种库和代码之间的依赖关系不知会多复杂.
Makefile的组织流程的能力如此之强, 不仅可以用来编译项目, 还可以用来组织我们平时的一些日常操作. 这个需要大家发挥自己的想象力.
本篇博客是基于 {精华} 跟我一起写 Makefile 而整理的, 有些删减, 追加了一些示例.
Tensorflow支持基于cuda内核与cudnn的GPU加速,Keras出现较晚,为Tensorflow的高层框架,由于Keras使用的方便性与很好的延展性,之后更是作为Tensorflow的官方指定第三方支持开源框架。但两者在使用GPU时都有一个特点,就是默认为全占满模式。在训练的情况下,特别是分步训练时会导致显存溢出,导致程序崩溃。可以使用自适应配置来调整显存的使用情况。
1 | import os |
一般地,CNN的基本结构包括两层,其一为特征提取层,每个神经元的输入与前一层的局部接受域相连,并提取该局部的特征。一旦该局部特征被提取后,它与其它特征间的位置关系也随之确定下来;其二是特征映射层,网络的每个计算层由多个特征映射组成,每个特征映射是一个平面,平面上所有神经元的权值相等。特征映射结构采用影响函数核小的sigmoid函数作为卷积网络的激活函数,使得特征映射具有位移不变性。此外,由于一个映射面上的神经元共享权值,因而减少了网络自由参数的个数。卷积神经网络中的每一个卷积层都紧跟着一个用来求局部平均与二次提取的计算层,这种特有的两次特征提取结构减小了特征分辨率。
CNN主要用来识别位移、缩放及其他形式扭曲不变性的二维图形。由于CNN的特征检测层通过训练数据进行学习,所以在使用CNN时,避免了显式的特征抽取,而隐式地从训练数据中进行学习;再者由于同一特征映射面上的神经元权值相同,所以网络可以并行学习,这也是卷积网络相对于神经元彼此相连网络的一大优势。卷积神经网络以其局部权值共享的特殊结构在语音识别和图像处理方面有着独特的优越性,其布局更接近于实际的生物神经网络,权值共享降低了网络的复杂性,特别是多维输入向量的图像可以直接输入网络这一特点避免了特征提取和分类过程中数据重建的复杂度。
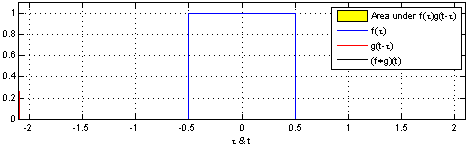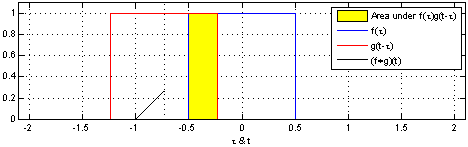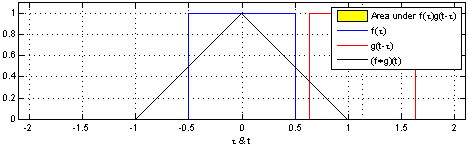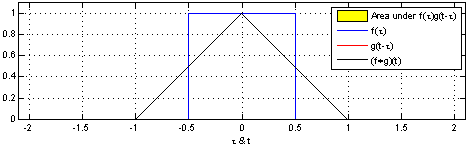
对于1维的卷积,公式(离散)与计算过程(连续)如下,要记住的是其中一个函数(原函数或者卷积函数)在卷积前要翻转180度。