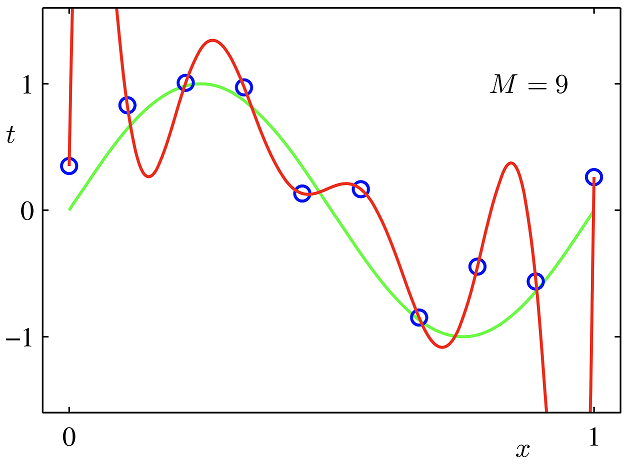
过拟合问题
欠拟合:根本原因是特征维度过少,模型过于简单,导致拟合的函数无法满足训练集,误差较大;
解决方法:增加特征维度,增加训练数据;过拟合:根本原因是特征维度过多,模型假设过于复杂,参数过多,训练数据过少,噪声过多,导致拟合的函数完美的预测训练集,但对新数据的测试集预测结果差。 过度的拟合了训练数据,而没有考虑到泛化能力。
解决方法:(1)减少特征维度;(2)正则化,降低参数值。
减少过拟合总结:
过拟合主要是有两个原因造成的:数据太少+模型太复杂
(1)获取更多数据 :从数据源头获取更多数据;