之前一直想学Docker,但是一拖再拖,最近看到一个大佬写的关于Docker的博客不错。特来学(ban)习(yun)一下。
特此声明,下面大部分内容来自于这位大佬,除此之外,还添加了一些自己的理解。
简介
Docker的官方地址在这里
Docker 是一种容器技术,它可以将应用和环境等进行打包,形成一个独立的,类似于手机APP形式的「应用」,这个应用可以直接被分发到任意一个支持 Docker 的环境中,通过简单的命令即可启动运行。Docker 是一种最流行的容器化实现方案。和虚拟化技术类似,它极大的方便了应用服务的部署;又与虚拟化技术不同,它以一种更轻量的方式实现了应用服务的打包。使用 Docker 可以让每个应用彼此相互隔离,在同一台机器上同时运行多个应用,不过他们彼此之间共享同一个操作系统。Docker 的优势在于,它可以在更细的粒度上进行资源的管理,也比虚拟化技术更加节约资源。
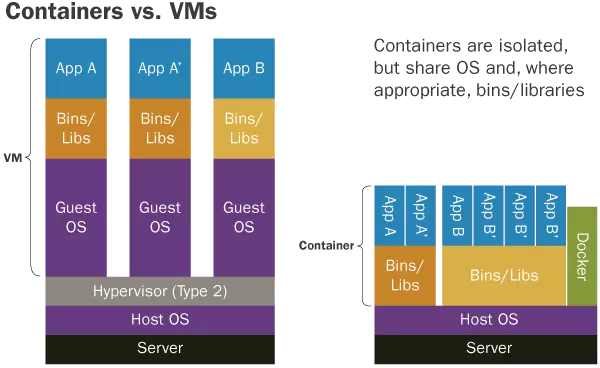
看到这个概念,立马想到了 虚拟机,两者有点像,下面给出官网的对比图,直观感受下二者的区别 ( 参考 )
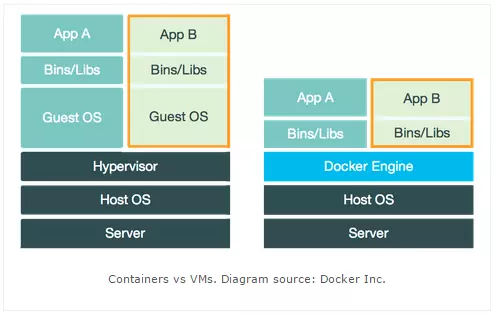
简单的说,Docker 可以共享物理机的硬件和系统资源,而 虚拟机 要对硬件进行虚拟化并且需要额外的资源开销用于运行虚拟的操作系统导致资源利用率低、性能差。在一台物理机上同时启动多个 Docker 容器或多个 虚拟机 就能有鲜明的对比了。
目前国内有好几家提供 Docker 云服务平台:道客云、时速云、灵雀云、希云 等,本人使用过道客云和时速云,界面类似于阿里云的控制台 ( 阿里云 上也有 容器服务 ),功能上包含了 镜像仓库、云服务器管理,持续集成 等等。虽然这几个平台的功能都是围绕 Docker 展开的,但业务侧重点也都有所不同,大家自己把玩吧。一般 个人版 是免费的,对于个人小项目的管理绰绰有余了,至于收费的 企业版 没用过就不发表意见了。
Docker 的特点和优势
结合前段时间的使用体验,主要归纳为以下几点:
可移植性,一次配置,随处移植
开发环境搭建绝对是开发过程中最令人头痛的环节,费时费劲费脑不说,开发到一半环境突然坏了,简直是灾难啊。
- 比如说有这样的场景,工具1 只能运行在 系统A 上,工具2 只能运行在 系统B上,然而残酷的需求是 工具1 和 工具2 都必须得用…
- 再比如说,来了一个新同事,准备大展身手帮忙配环境,结果出现各种神奇的问题,各种 运行不了,内心也是崩溃得不要不要的…
使用 Docker 可以将每个工具和相关的配置打包成镜像,这样就可以方便的 共享、备份、还原 了。当然,这种方法更适合长期在 Linux 环境下开发的同学,本人作为 Windows 重度用户想想就行了。还记得以前上学那会儿,很多开发工具都是指名道姓要运行在 xxx系统 上,想到装 虚拟机,各种乱七八糟的配置,对硬件的要求也比较奇葩等等,还没开始就想放弃了,最重要的是还不一定能成功!!!现在用了 Docker 之后,这些都不是事儿!
标准化应用发布和使用
Linux 各种五花八门的发行版本还是比较多的,开发好的应用可能不能如愿的兼容各个发行版本,更何况每个发行版本基本有一套专属的指令体系和软件包管理体系,对于小白来说真是心塞。使用了 Docker 之后,容器将应用与 物理机 操作系统隔离,内部使用独立的操作系统 ( 内核 还是共享的 ),所以不管移植到哪个平台上始终可以运行在内部的操作系统之上,开发过程中也就可以专门针对一个最熟悉的操作系统进行配置和性能优化,大大减小学习成本和运维成本。另外,将应用和环境作为一个整体 ( 镜像 ),还有一个好处就是,通过统一的 Docker 命令实现对不同应用的 标准化 管理,镜像仓库 中每一个 镜像 就是一个应用 ( 好比在 应用商店 下载手机 APP ),获取 镜像 之后你不需要特别了解环境怎么配置,通过什么脚本或指令来启动,怎么管理开机启动的等等,这些问题都交给 Docker ,你只需了解相关的 Docker 命令就可以快乐地玩耍了。
资源利用率高,启动迅速
启动 Docker 容器运行应用相当于是运行本地进程,相比 虚拟机 既可充分利用硬件性能,又节约启动时间,操作也简便。
持续集成
配合 持续集成 工具如 Jenkins,版本控制 工具如 Git、SVN,项目构建 工具如 Maven 可以实现 一键发布 或者 自动化构建,结束人肉运维的惨淡人生。就拿 Tomcat 来说,没有彻底重启的功能,只能靠自己写 脚本 杀进程,有时又会莫名其妙关闭 ( 大部分原因还是代码没写好 ),这又需要写脚本定时监控重启 Tomcat。针对这两个痛点,这时 Docker 就派上了用场,对于 Docker 来说,重启容器即等价于重启应用,而且 Docker 自身可以很方便地设置开机启动容器和自动重启容器保证服务不中断。
隔离性
作为一枚小白,对于 Linux 平台上应用的安装真心看不懂,有的可以通过平台的包管理工具安装,有的只能通过源码安装,安装后目录难找就算了,有时候一些配置文件要么遍地开花要么根本找不到,而且貌似也没有纯净卸载的选项,残留各种碎片。Docker 的思想就类似于 集装箱,整合零碎的东西于一个整体之内,简化操作步骤,同时可以隔离内外环境,内部应用不入侵外部操作系统环境,外部操作系统不干扰内部应用运行,而这个隔离也可以有效解决应用之间的冲突。当然,这个隔离性还是取决于实际的使用情况, 错误地使用 数据卷 和其他 特殊配置 都会破坏 容器 和 宿主机 之间的和谐。
子服务器搭建
可能手头有一台高性能的服务器,自己一个人使用且用途也不大的话显得太浪费,这时就可以构建几个容器限制 内存、CPU、磁盘 等配置后分享给其他人使用,这相当于多开了几台虚拟的服务器,容器内性能并没有打多少折扣而且容器与容器之间,容器与物理机之间都是相互独立不干扰的。写到这里忽然想到,我买的阿里云 ECS 会不会也只是一个 Docker 容器呢?就算不是也应该是类似的存在吧。
Docker 涉及到的一些关键概念
镜像
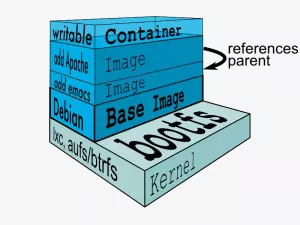
有装过 操作系统 的朋友可能想到了系统镜像( ISO文件 ),个人觉得就是一回事,就是程序的安装包,是一个包含了应用程序和其运行时环境的只读文件。镜像需要以一个 Linux 发行版作为基础运行环境,在此之上构建自己的应用。镜像的结构为一层一层的文件系统,每一层包含了所做的修改内容,所有层次的修改合并就构成了最终的镜像内容,因此,镜像是可以继承的,子镜像是在父镜像的基础上做一定的修改得到的。有一点要注意的是,即使在后面的层次中删除了某些文件,但它们仍然存在于之前的层次之中而并不会减小镜像大小,理论上层次增加就会导致镜像占用大小增加。因此,自己构建的镜像应尽可能减少层次,每一层的修改只保留必要的文件,删除临时文件。另外,由于这种层次结构,镜像文件的拉取是一个增量的过程,每次只下载不存在的层级数据,而不必每次下载完整的镜像文件,大大减少了迁移过程中网络传输的数据量。
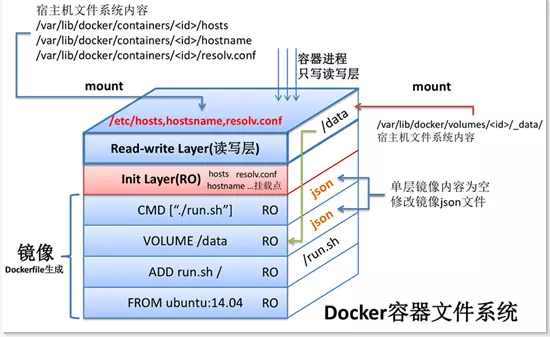
容器
既然说 镜像 是安装包,那么 容器 就是运行中的程序,这才是等价于 虚拟机 的存在。之前说 镜像 是由一层层文件系统构成的,不过它们都是只读的,启动 容器 之后会在它们之上构建一层 读写层,容器 运行过程中的一切修改都会保存在当中,将 读写层 保存起来就构建出了新的 镜像 ( docker commit )。
镜像仓库
相当于就是手机 APP 的应用商店,在这里我们可以下载前人构建的 镜像,即可直接使用应用,也可以基于这些镜像构建针对自有业务的个性化镜像。镜像仓库 的作用体现在 版本控制、资源共享、权限管理。
Docker安装与配置
安装
采用如下安装方式:
1 | #使用 apt-get 进行安装 |
输入以下命令验证是否安装成功:
1 | sudo docker run hello-world |
镜像加速:sudo vim /etc/docker/daemon.json,添加"registry-mirrors"字段。
1 | { |
然后执行:
1 | sudo systemctl daemon-reload |
注意如果更改完镜像地址后,若遇到一些奇怪的问题,例如Docker无法启动等,可以尝试将/etc/docker/daemon.json配置文件删除,然后执行sudo systemctl restart docker.service。
普通用户权限配置
docker的操作需要sudo,如果你自己的服务器账号没有sudo权限,可以把创建一个docker组,把没有sudo权限的账号加进去,这样就可以在没有sudo权限的账号下操作docker了,具体详见 官方文档。具体过程如下:
首先新建一个组:
1 | $ sudo groupadd docker |
然后加入没有sudo权限的账户:
1 | $ sudo usermod -aG docker zdaiot |
zdaiot 是我的账户名,这里什么修饰也不要加。
然后查看下group里面有没有刚刚添加的账户:
1 | $ sudo cat /etc/group | grep docker |
发现有自己的账户,然后更新一下,在windows和mac系统上需要重启机器,但是linux端可以不用重启,执行下面命令即可
1 | $ newgrp docker |
然后登录刚刚添加的账户,执行
1 | $ docker run hello-world |
没有报错即可。
NVIDIA Docker
简介
因为GPU属于特定的厂商产品,需要特定的driver,Docker本身并不支持GPU。以前如果要在Docker中使用GPU,就需要在container中安装主机上使用GPU的driver,然后把主机上的GPU设备(例如:/dev/nvidia0)映射到container中。所以这样的Docker image并不具备可移植性。
Nvidia-docker项目就是为了解决这个问题,它让Docker image不需要知道底层GPU的相关信息,而是通过启动container时mount设备和驱动文件来实现的。
在你使用 Nvidia-docker 的时候,你需要做的有如下几件事
- 安装你电脑中
GPU的driver(必备的) - 安装
docker 19.03(安装包通用) - 安装
nvidia-docker2(安装包通用) - 下拉附带
CUDA的镜像(镜像文件是通用的,可以打包后拷贝到另外一台电脑上)
最开始,nvidia-docker 需要运行一个独立的 daemon,与 Docker 的生态不能很好地兼容。 比如,docker-compose、docker swarm 与 Kubernetes,都不能很好的和 nvidia-docker 一起工作。所以,第一代的 nvidia-docker 被弃用。
官方,研发出 nvidia-docker2。nvidia-docker 一代是一个 Volume Plugin,而 nvidia-docker2 则是一个 Docker Runtime,机制的差异,带来了巨大的改进。
后来,docker 19.03 发布后,NVIDIA GPU 本身作为 Docker 运行时中的设备受支持,所以 nvidia-docker2 又被弃用。现在的 nvidia-docker 是建立在 docker 19.03 上的。
官方提供了,nvidia-docker2 升级步骤:Upgrading with nvidia-docker2
安装
官方地址nvidia-docker 安装流程。官网明确说过,如果你有 nvidia-docker1.0 要么升级,要么卸载后安装 nvidia-docker2。
我们是通过 apt-get 安装。但是,apt-get 的下载通道中没有这个下载通道,所以,我们要添加一下。
1 | distribution=$(. /etc/os-release;echo $ID$VERSION_ID) |
然后安装 nvidia-docker2。
1 | sudo apt-get update |
重新打开
1 | sudo systemctl restart docker |
然后官网会给你一个命令检测你安装成功了吗。
1 | sudo docker run --rm --gpus all nvidia/cuda:11.0-base nvidia-smi |
这个命令不一定可以,因为,你的驱动可能太低了,不能运行 cuda11.0。所以,你可以自己进行降版本运行。
1 | sudo docker run --rm --gpus all nvidia/cuda:10.0-base nvidia-smi |
这个时候因为会自动下载image,例如'nvidia/cuda:10.2-base'。也就是可以这样理解,首先要安装Docker,然后安装NVIDIA Docker。NVIDIA Docker可以看做是一种特殊的Docker,若想使用这种Docker,需要安装对应的镜像。上面检测安装是否成功的命令就可以自动下载镜像。
Docker-Compose、Docker Swarm与Kubernetes
Docker-Compose 是用来管理你的容器的,有点像一个容器的管家,想象一下当你的Docker中有成百上千的容器需要启动,如果一个一个的启动那得多费时间。有了Docker-Compose你只需要编写一个文件,在这个文件里面声明好要启动的容器,配置一些参数,执行一下这个文件,Docker就会按照你声明的配置去把所有的容器启动起来,只需docker-compose up即可启动所有的容器,但是Docker-Compose只能管理当前主机上的Docker,也就是说不能去启动其他主机上的Docker容器。
Docker Swarm 是一款用来管理多主机上的Docker容器的工具,可以负责帮你启动容器,监控容器状态,如果容器的状态不正常它会帮你重新帮你启动一个新的容器,来提供服务,同时也提供服务之间的负载均衡,而这些东西Docker-Compose 是做不到的。
Kubernetes它本身的角色定位是和Docker Swarm 是一样的,也就是说他们负责的工作在容器领域来说是相同的部分,都是一个跨主机的容器管理平台,当然也有自己一些不一样的特点,k8s是谷歌公司根据自身的多年的运维经验研发的一款容器管理平台。而Docker Swarm则是由Docker 公司研发的。目前比Docker Swarm用的人多。
常见错误
unknown flag: —gpus
如果遇到错误unknown flag: --gpus,则执行sudo apt-get install docker-ce-cli。
unknown or invalid runtime name: nvidia.
当启动一个容器时,运行以下命令:
1 | docker run --runtime=nvidia ... |
报错:
1 | docker: Error response from daemon: unknown or invalid runtime name: nvidia. |
报错的信息显示nvidia无法识别,这说明我得daemon.json配置文件出错。
修改/etc/docker/daemon.json(需要管理员权限),添加如下的内容:
1 | "runtimes": { |
修改后的文件整体信息如下:
1 | { |
然后重启docker就好了:
1 | sudo systemctl daemon-reload |
参考
Docker 学习总结
Ubuntu20.04成功安装Docker
docker 和 nvidia-docker 的离线安装和基本使用
docker笔记(13)——nvidia-docker简介
nvidia-docker | 简介和扫盲
NVidia Docker介绍
【Docker】daemon.json的作用(八)
nvidia-docker镜像加速
unknown flag: —gpus #1165
docker启动容器报错 Unknown runtime specified nvidia.
【服务器端实现推理加速】一、安装FasterTransformer加速库
docker、docker-compose、docker swarm和k8s的区别

