最近,学完字符编码之后,准备一鼓作气,看一下数字编码。
整数编码
在C语音中,整数编码可以分为有符号整数和无符号整数。当用关键字 char short long等指定,默认的是前面有signed,如果声明为有符号类型,需要在关键字前加unsigned,如unsigned short ,unsigned long等等。
那么这些数据是如何存储的呢?
无符号整数
首先我们来看最简单的无符号整数。假设该二进制数有$w$位,那么它能表示的数据范围为$[0,2^w−1]$。
以int8为例(也就是用8个bit来表示数字),那么取值范围为0000 0000到1111 1111,也就是0到255。这本身没有什么好讲的。
下面是在C\C++中无符号基本数据类型的最小值跟最大值(64位机器):
| 数据类型 | 最小值 | 最大值 |
|---|---|---|
| unsigned char | 0 | 255 |
| unsigned short | 0 | 65 535 |
| unsigned int | 0 | 4 294 967 295 |
| unsigned long | 0 | 18 446 744 073 709 551 615 |
有符号整数
无符号整数看起来很简单,但是无法处理负数。这时候有符号整数就派上用上了。
原码、反码、补码
我们首先介绍几个关键概念。
原码:原码表示是最简单的,第一位为符号位,其余位为相应的数值。
例如short a = 6,a 的原码就是0000 0000 0000 0110。更改 a 的值a = -18,此时 a 的原码就是1000 0000 0001 0010。
反码:正数的反码与其原码相同;负数的反码是将原码中除符号位以外的所有位取反。
例如short a = 6,a 的原码和反码都是0000 0000 0000 0110。更改 a 的值a = -6,此时 a 的反码是1111 1111 1111 1001。
补码:对于正数,它的补码就是其原码(原码、反码、补码都相同);对于负数,补码等于反码加1。例如short a = 6,a 的原码、反码、补码都是0000 0000 0000 0110。更改 a 的值a = -6;,此时 a 的补码是1111 1111 1111 1010。
用公式表示该过程如下:
其中$\vec{x}$为二进制为$w$位的向量形式,其中的分量只能是0和1。上式可以看到最高位$x_{w-1}$为符号位,最高位$x_{w-1}$为1则为负数,为0则代表正数,此时只剩下了$\sum_{i=0}^{w-2}x_i2^i$。
下面我们来考虑$w$位补码所能表示的范围,上面的式子所能表示的最小值是最高位为 1,其他位均为零的时候即$D_{min}=-2^{w-1}$。而最大值是最高位(符号位)为 0,其他位均为 1 时,即$D_{max}=\sum_{i=0}^{w-2}2^i=2^{w-1}-1$。所以一个$w$位的二进制数可以表示的有符号数值范围是$[-2^{w-1},2^{w-1}-1]$。
下面是在C\C++中无符号基本数据类型的最小值跟最大值(64位机器)。
| 数据类型 | 最小值 | 最大值 |
|---|---|---|
| char | -128 | 127 |
| short | -32 768 | 32 767 |
| int | -2 147 483 648 | 2 147 483 647 |
| long | -9 223 372 036 854 775 808 | 9 223 372 036 854 775 807 |
那么为什么补码表示的表示范围是不对称的,正数比负数要少一个?是因为有一半的位要表示负数(符号位为 1),另一半的位要表示正数(符号位为 0)。以int8为例,那么1000 0000和0000 0000分别表示正负0,但是我们并不需要负0,所以把1000 0000编码为了负数。
产生原因
那么有了原码,计算机为什么还要用补码呢?这就需要看它们的运算情况。
假设字长为 8 位 ,那么原码的运算方式为:1 - 1 = 1 + ( -1 ) =(00000001) + (10000001) = (10000010) = -2,这显然不正确。出现的原因是这种形式下,符号位无法参与运算。当两个正数相加时是没有问题的,但是负数无法参与运算。
我们接下来看一下反码的运算:1 - 1 = 1 + ( -1 )= (00000001) + (11111110) = (11111111) = ( -0 ) 有问题。1 – 2 = 1 + ( -2 ) = (00000001) + (11111101) = (11111110) = ( -1 ) 正确。反码的问题出 现在(+0)和(-0)上,因为在人们的计算概念中零是没有正负之分的。
再来看补码的加减运算 如下:1 - 1 = 1 + (-1) = (00000001) + (11111111) = (00000000) = 0 正确。1 – 2 = 1 + (-2)= (00000001) + (11111110) = (11111111) = ( -1 ) 正确。
浮点数编码
根据国际标准IEEE 754,任意一个二进制浮点数V可以表示成下面的形式:
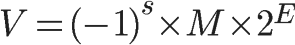
1、(-1)^s表示符号标志位,当s=0,V为正数;当s=1,V为负数。
2、M表示有效数字,大于等于1,小于2。称作尾数(significand)。
3、2为基数。
4、E则是指数部分称作阶码(exponent)。
举例来说,十进制的5.0,写成二进制是101.0,相当于1.01×2^2。那么,按照上面V的格式,可以得出s=0,M=1.01,E=2。
十进制的-5.0,写成二进制是-101.0,相当于-1.01×2^2。那么,s=1,M=1.01,E=2。
IEEE 754规定,对于32位的浮点数,最高的1位是符号位s,接着的8位是指数E,剩下的23位为有效数字M。

对于64位的浮点数,最高的1位是符号位S,接着的11位是指数E,剩下的52位为有效数字M。
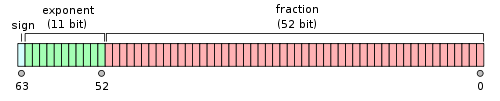
IEEE 754对有效数字M和指数E,还有一些特别规定。
前面说过,1≤M<2,也就是说,M可以写成1.xxxxxx的形式,其中xxxxxx表示小数部分。IEEE 754规定,在计算机内部保存M时,默认这个数的第一位总是1,因此可以被舍去,只保存后面的xxxxxx部分。比如保存1.01的时候,只保存01,等到读取的时候,再把第一位的1加上去。这样做的目的,是节省1位有效数字。以32位浮点数为例,留给M只有23位,将第一位的1舍去以后,等于可以保存24位有效数字。
至于指数E,情况就比较复杂。
首先,E为一个无符号整数(unsigned int)。这意味着,如果E为8位,它的取值范围为0~255;如果E为11位,它的取值范围为0~2047。但是,我们知道,科学计数法中的E是可以出现负数的,所以IEEE 754规定,E的值必须再减去一个中间数,得到真实值,这个中间数称为偏置量Bias。它的数值跟存储阶码的位长有关,当阶码位长为k的时候偏置量的值为2 ^ k - 1。对于8位的E,这个中间数是127;对于11位的E,这个中间数是1023。
比如,2^10的E是10,所以保存成32位浮点数时,必须加上中间数,保存成10+127=137,即10001001。
规格化浮点数
E不全为0或不全为1。这时,浮点数就采用上面的规则表示,即指数E的计算值减去127(或1023),得到真实值,再将有效数字M前加上第一位的1。
可以推断出它所能够表示的无符号数取值范围是1~254。因此,阶码值的取值范围是-126 ~ 127。
非规格化浮点数
非规格化浮点数的特点就是用于存储阶码的所有位全为0E全为0,存储尾数的位可以随意定制。非规格化浮点数主要用于表示那些非常接近于0的数。这时,浮点数的指数E等于1-127(或者1-1023),有效数字M不再加上第一位的1,而是还原为0.xxxxxx的小数。这样做是为了表示±0,以及接近于0的很小的数字。
为啥这个地方是1-127呢?这是为了平滑过度。具体可看详谈IEEE浮点数编码机制。
特殊值
E全为1。这时如果有效数字M全为0,表示±无穷大(正负取决于符号位s);如果有效数字M不全为0,表示这个数不是一个数(NaN)。

