之前在大三的时候,就已经接触这个库了,但是那个时候我是拒绝使用的,因为感觉好复杂。Python命名有更加简单的库去处理excel和csv文件。但是后来发现无法绕过去,因为pandas在数据科学中被广泛使用,其功能特别强大。最近参加kaggele竞赛的时候,提交结果的时候通常是csv文件。想了想,算了系统的学习一下吧。
数据类型
Pandas库有很一些自定义的数据结构,例如DataFrame和Series。下面我们对这些数据结构进行详细的介绍。
Series
它是一维标记数组,可以存储任意数据类型:int/string/float/Python对象,创建Series方法例子:
1 | s = Series(data, index = index) |
DataFrame
它是二维标记数据结构,列可以是不同的数据类型,是最常用的pandas对象,如同Series对象一样接受多种输入:lists/dicts/Series/DataFrame。
属性
DataFrame有很多属性,下面我们介绍一下常用的属性。
index
index属性可以查看哪些值作为了行索引。例如
1 | frame = pd.DataFrame(np.random.rand(4,4),index=list('abcd'),columns=list('ABCD')) |
columns
columns属性可以查看哪些值作为了列索引。例如
1 | frame.columns |
索引
取DataFrame的方式主要有两种,第一种是借助loc方法,第二种方法是借助iloc方法。
loc
使用loc方法索引的时候,主要方法为
1 | DataFrame.loc[行索引,列索引] |
那么如何知道行索引和列索引取什么值呢?这里就用到了我们上面说到的index和columns属性。例如上面index属性值为Index(['a', 'b', 'c', 'd'], dtype='object'),那么我们就可以取'a'、 'b'、'c'、'd'作为行索引。同样的,我们可以取'A'、 'B'、'C'、'D'作为行索引。所以,例如
1 | frame.loc['a','A'] |
这里的索引之所以加上
'',为str类型,是因为在属性index和columns中这些值均为str类型。
另外,我们像在Python中Numpy和list那样采用切片的方式取数据,例如:
1 | # 取前两行对应数据 |
上面的例子取的都是连续的行和列,若取第一行和第四行、第一列和第四列对应的数据,则
1 | frame.loc[['a','d'],['A','D']] |
iloc
使用iloc方法索引更加简单,无需知道我们的行索引和列索引,只需要知道坐标即可,主要方法为:
1 | DataFrame.iloc[行标号,列标号] |
这里的行标号和列标号即为要取的值在数据中的位置(行索引和列索引不占编号)。例如
1 | frame.iloc[0,0] |
同样的,我们像在Python中Numpy和list那样采用切片的方式取数据,例如:
1 | # 取前两行对应数据 |
上面的例子取的都是连续的行和列,若取第一行和第四行、第一列和第四列对应的数据,则
1 | frame.iloc[[0,3],[0,3]] |
多级索引
多级索引(也称层次化索引)是pandas的重要功能,可以在Series、DataFrame对象上拥有2个以及2个以上的索引。
实质上,单级索引对应Index对象,多级索引对应MultiIndex对象。
MultiIndex对象
创建:
1 | se1=pd.Series(np.random.randn(4),index=[list("aabb"),[1,2,1,2]]) |
子集的选取:
1 | se1['a'] |
loc
和单级索引相同的是,我们可以使用loc方法进行取值,那么哪些值可以作为索引值,也是需要index和columns属性得知。如下:
1 | df1=pd.DataFrame(np.arange(12).reshape(4,3),index=[list("AABB"),[1,1,1,2]],columns=[list("XXY"),[10,11,10]]) |
注意到在属性index中,有两个标签分别为levels和labels,其中在levels标签有两个list,在第一个list中存放第一级索引,在第二个list中存放第二级索引。而在labels中也存着两个list,第一个list存放的是DataFrame中各行数据分别属于哪个第一级索引(以下标形式给出),同样的第一个list存放的是DataFrame中各行数据分别属于哪个第二级索引(以下标形式给出)。
另外,在我们生成该数据的时候,使用的index属性第一级索引为"AABB",但是放到levels标签的时候,是经过去重的,所以这也就是需要labels标签的原因。
有了这些准备工具,我们就可以随心所欲的取数据了,例如:
1 | df1.loc[['A',1],['X',10]] |
注意:行索引从行开始取,必须一层层取,取完行索引,才可以取列索引,先取列索引同理。
另外,还有一些高级用法。
例如,每一层都可以赋名
1 | df1.columns.names=['XY','sum'] |
运行结果:
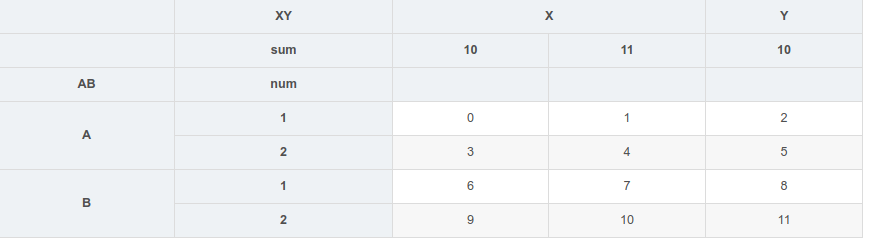
可以创建MultiIndex对象再作为索引
1 | df1.index=pd.MultiIndex.from_arrays([list("AABB"),[3,4,3,4]],names=["AB","num"]) |
运行结果:
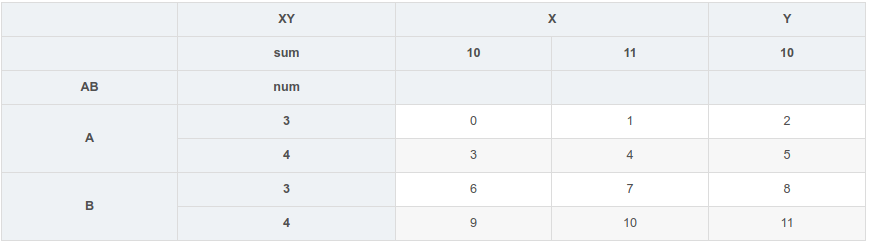
可以对各级索引进行互换
1 | df1.swaplevel('AB','num') |
运行结果:
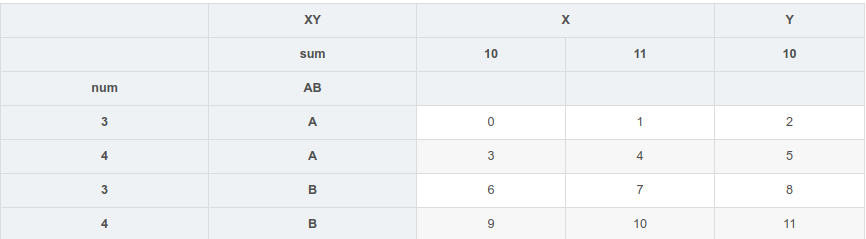
iloc
同样的,我们也可以使用iloc的方法进行索引,这个时候,我们只需要知道数据的坐标即可。无需在乎他们的index和columns属性,例如
1 | df1.iloc[0,0] |
处理csv文件
方法为:
1 | pandas.read_csv(filepath_or_buffer, sep=', ', delimiter=None, header='infer', names=None, index_col=None, usecols=None, squeeze=False, prefix=None, mangle_dupe_cols=True, dtype=None, engine=None, converters=None, true_values=None, false_values=None, skipinitialspace=False, skiprows=None, skipfooter=0, nrows=None, na_values=None, keep_default_na=True, na_filter=True, verbose=False, skip_blank_lines=True, parse_dates=False, infer_datetime_format=False, keep_date_col=False, date_parser=None, dayfirst=False, iterator=False, chunksize=None, compression='infer', thousands=None, decimal=b'.', lineterminator=None, quotechar='"', quoting=0, doublequote=True, escapechar=None, comment=None, encoding=None, dialect=None, tupleize_cols=None, error_bad_lines=True, warn_bad_lines=True, delim_whitespace=False, low_memory=True, memory_map=False, float_precision=None) |
可以看出这个方法的功能特别强大,我们这里只介绍一些常用的属性。
- sep:csv文件中的分隔符,一般都是
','
header
参数可选int, list of int, default ‘infer’。用作列名和数据开头的行号,默认行为是推断列名:如果未传递任何名称,则行为与HEADER=0相同,并且从文件的第一行推断列名;如果显式传递列名,则该行为与HEADER=NONE相同。显式传递Header=0以能够替换现有名称。标头可以是整数列表,这些整数指定列上的多索引的行位置,例如[0,1,3]。将跳过未指定的中间行(例如,跳过本例中的2)。请注意,如果SKIP_BLARE_LINES=True,此参数将忽略注释行和空行,因此HEADER=0表示数据的第一行,而不是文件的第一行。
例如,文件ceshi.csv的内容如下:
| t | c1 | c2 | c3 |
|---|---|---|---|
| a | 0 | 5 | 10 |
| b | 1 | 6 | 11 |
| c | 2 | 7 | 12 |
| d | 3 | 8 | 13 |
| e | 4 | 9 | 14 |
默认
默认情况下,读取该csv文件的代码为:
1 | obj_4=pd.read_csv('ceshi.csv') |
也就是在默认参数情况下,该函数会自动的添加行索引,并将第一行作为列索引。
0
当指定该参数为0的时候,其表现与默认情况下一致:
1 | obj_3=pd.read_csv('ceshi.csv',header=0) |
None
当指定该参数为None的时候,读取数据的时候,不会将第一行作为列索引,而是会作为其数据的一部分。而行索引还是自动分配的。其代码如下:
1 | obj=pd.read_csv('ceshi.csv', header=None) |
int
当指定该参数为一个int值的时候,会将改行作为列索引,并忽略之前行。而行索引还是自动分配的。例如:
1 | obj_5=pd.read_csv('ceshi.csv',header=2) |
list
当header为list的时候,情况为将list中的值对应的行作为列的多级索引。当list中的整数从小到大排列,忽略掉list中没有出现的数字,例如当header=[0,2]的时候,会忽略第2行。其余情况情况并不会忽略,只是会将list中对应的行作为列的多重索引。代码如下:
1 | obj_6=pd.read_csv('ceshi.csv',header=[0,2]) |
参数list不是从小到大排列的时候,可以看到比较混乱,因为b 1 6 11不仅出现在了索引行,还出现在了数据中,不建议这么使用,可能会出现意想不到的情况。如下:
1 | obj_6=pd.read_csv('ceshi.csv',header=[2,0]) |
index_col
可选参数:int, sequence or bool, optional,列用作DataFrame的行标签。如果给定序列,则使用多级索引。如果您有一个在每行末尾都有分隔符的格式错误的文件,您可能会考虑INDEX_COL=FALSE,以强制熊猫不使用第一列作为索引(行名)。
从上面可以看到控制header参数,我们可以控制属性columns,即使用那些行作为列的索引。当未指定index_col属性的时候,会自动添加索引。那么如何自定义属性index呢?答案是使用index_col属性。下面的介绍还是以ceshi.csv文件为例。
默认
默认情况下,读取该csv文件的代码为:
1 | obj_4=pd.read_csv('ceshi.csv') |
也就是在默认参数情况下,该函数会自动的添加行索引,并将第一行作为列索引。
False
当该参数取值为True的时候,会报错,所以只能为False。代码如下,可以看到这种情况下,其结果与默认情况一致。自动的添加行索引,并将第一行作为列索引。
1 | obj=pd.read_csv('ceshi.csv', index_col=False) |
int
当该参数为int的时候,会将该参数对应的列作为索引行,并且该列在数据中并不会在出现。并且index属性有可能有name标签。
1 | obj_5=pd.read_csv('ceshi.csv',index_col=2) |
list
当该参数为list的时候,会将list中对应的列作为行的多级索引,并且这些列不会出现在数据中。
1 | obj_2=pd.read_csv('ceshi.csv',index_col=[0,2]) |
总结
在read_csv函数中,我们使用header参数控制那些行的值作为列索引,默认为第一行作的列索引。而可以使用index_col参数控制哪些列作为行索引,默认为生成编号作为行索引。
完整打印
pandas的长数据在打印的时候,往往为了方便阅读会进行省略操作,但这会对我们查看数据带来不便。要想完整print,可以设置如下:
1 | import pandas as pd |
参考
pandas.read_csv
python pandas 中 loc & iloc 用法区别
python:pandas——read_csv方法
Pandas详解十三之多级索引MultiIndex(层次化索引)
python-长数据完整打印方法

