首先声明,这篇文章的主要内容大部分来自小伙伴的总结,具体地址在这里,欢迎访问~~~我这里在小伙伴总结的基础上再加上一些自己的理解。
Python中与内存相关的基本概念
变量、对象及引用
在Python中有一个基础概念:Python中的所有东西都是对象。与C++等编译语言不同(把值赋给变量,强类型语言),Python中的变量本身是不具有数据类型的(弱类型语言),其数据类型由其所指向的对象的类型决定,如下:
1 | a = 1 |
其中a被称为变量,而1则是对象,a的数据类型由1决定,即整型int,当我们将变量a指向另一个数据类型的对象时,a的类型也将随着其所指向的对象类型而发生改变。
在 Python 中 a = something 应该理解为给 something 贴上了一个标签 a。当再赋值给 a 的时候,就好像把a 这个标签从原来的 something上拿下来,贴到其他对象上,建立新的引用。
1 | a = [1, 2, 3] |
在Python中,对象拥有真正的内存资源与相应的取值,变量只是对象的一个引用。一个变量引用一个对象,而一个对象可以被多个变量引用。正是因为一个对象可以被多个变量引用,所以只有在某个对象的引用个数为0时,Python才会对该对象的内存进行回收,有点类似于C++中的智能指针的内存回收机制。
我们再看另外一个例子:
1 | def fun(x): |
运行结果为:
1 | Out: 139769510511880 |
分析:当进入子函数fun()时,内存布局如下图所示:

可以看到,x和a指向的是同一块地址,当执行x[1] = -2时:

可以看到,虽然fun()函数并没有返回值,但是实参a中的值仍然改变了,这是因为Python在传参时,传入的是引用,所以变量a和变量x的id()函数的输出相同。那么,在fun()函数内部改变了引用的所指向的内存,则外部的实参a所指向的内存也发生了改变。
其实,这和C语言类似,在C语言中,当传入的实参是数组时,实际上传入的是数组的首地址,在函数内部通过形参改变其数组的内容,那么函数外部数组的内容也就发生了变化。不同点在于,在C语言传参时,会将变量的值复制一份到形参(例如传入数组时,会将数组的首地址复制一份给形参,所以当在函数内部改变形参所指向的内容时,实参并没有发生任何变化)。而Python中,只是实参所引用的对象的引用数加1。
再看另外一个例子:
1 | def fun2(x): |
运行结果为:
1 | Out: 94188549293120 |
分析:当进入fun2()函数的时候,内存布局如下:

当执行完x=1时,内存布局如下:
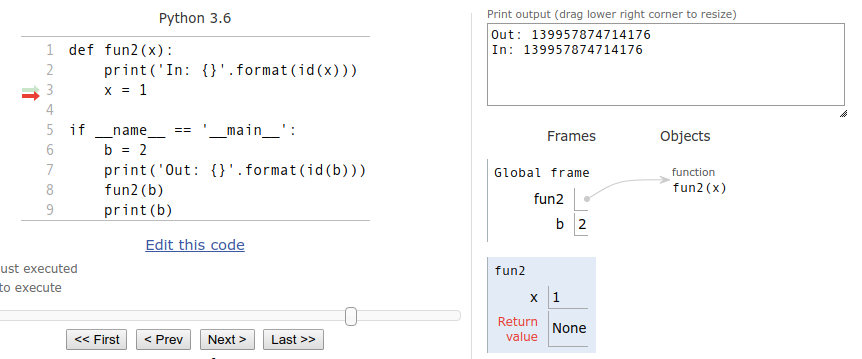
在Python中,id()函数用于获取对象的内存地址。而上面的x和b是变量,并不是对象,所以内部和外部的id()返回值相同。而在fun2()函数内部,执行x = 1只是将x绑定到了新的对象上,并没有改变原对象的内容,所以外部b变量的值并没有发生变换。
存储机制
总的来说,python在存储对象时存在三个存储区域:
- 事先分配的静态内存,这一部分内存的大小以及对应的取值固定,需要某个对象时在相应位置取值即可。
- 事先分配的可重复利用内存,这一部分内存的大小固定,但在需要的时候才对这一部分内存进行赋值,这一部分的内存可以重复利用。
- 使用
malloc和free管理的自由内存,这一部分的内存是动态申请和释放的。
在介绍例子之前,我们先说明一下比较两个整数时==和is的区别:
is比较的是两个整数对象的id值是否相等,也就是比较两个引用是否代表了内存中同一个地址。==比较的是两个整数对象的内容是否相等,使用==时其实是调用了对象的__eq__()方法。
首先来看整型对象的存储,该类型的存储区域可分为两部分:对小整数[-5, 256]事先分配静态内存、对大整数(其他部分)事先分配可重复利用的内存。比如如下的代码:
1 | def main(): |
部分运行结果为:
1 | 253 is 253 |
出现这一现象的原因便是Python的静态内存机制,当整数的大小位于[-5,256]范围内时,在任何需要引用这些对象的地方,都不再重新创建新的对象,而是直接引用缓存中的对象。而当整数的大小不在这一范围内时,便会新建新的对象,这时即使值是一样的,也属于不同的对象(对应不同的内存地址)。
还有另外一个例子,代码如下:
1 | a = 257 |
程序的执行结果已经用注释写在代码上了。够坑吧!看上去a、b和c的值都是一样的,但是is运算的结果却不一样。为什么会出现这样的结果,首先我们来说说Python程序中的代码块。所谓代码块是程序的一个最小的基本执行单位,一个模块文件、一个函数体、一个类、交互式命令中的单行代码都叫做一个代码块。上面的代码由两个代码块构成,a = 257是一个代码块,main函数是另外一个代码块。Python内部为了进一步提高性能,凡是在一个代码块中创建的整数对象,如果值不在small_ints缓存范围之内,但在同一个代码块中已经存在一个值与其相同的整数对象了,那么就直接引用该对象,否则创建一个新的对象出来,这条规则对不在small_ints范围的负数并不适用,对负数值浮点数也不适用,但对非负浮点数和字符串都是适用的,这一点读者可以自行证明。所以 b is c返回了True,而a和b不在同一个代码块中,虽然值都是257,但却是两个不同的对象,is运算的结果自然是False了。
为了验证刚刚的结论,我们可以借用dis模块(听名字就知道是进行反汇编的模块)从字节码的角度来看看这段代码。如果不理解什么是字节码,可以先看看《谈谈 Python 程序的运行原理》)这篇文章。可以先用import dis导入dis模块并按照如下所示的方式修改代码。
1 | import dis |
代码的执行结果如下图所示。可以看出代码第6行和第7行,也就是main函数中的257是从同一个位置加载的,因此是同一个对象;而代码第9行的a明显是从不同的地方加载的,因此引用的是不同的对象。

如果还想对这个问题进行进一步深挖,推荐大家阅读《Python整数对象实现原理》这篇文章。
而对于string类型,同样也划分为静态内存和可重复利用内存。
Python的内存管理机制
在C++语言中,允许我们直接对内存进行管理,这样做的好处在于我们可以很灵活地对内存进行申请释放,缺点在于内存管理较为复杂、容易出错。在Python中,其本质上也是使用malloc和free等进行内存的管理,但区别在于Python本身完成了对内存的自动管理,有一套完整的内存管理机制,只向程序员提供了少量的接口。
Python的内存管理机制总体上可以划分为两个部分:
引用计数机制
引用计数机制的主要作用为:依据对象的被引用次数决定该对象是否应该被释放。
针对可以重复利用的内存缓冲区和内存,Python使用了一种引用计数的方式来控制和判断某块内存是否已经没有再被使用。即每个对象都有一个计数器count,记住了有多少个变量指向这个对象,当这个对象的引用计数器为0时,假如这个对象在缓冲区内,那么它地址空间不会被释放,而是等待下一次被使用,而非缓冲区的该释放就释放。
这里通过sys包中的getrefcount()来获取当前对象有多少个引用。例如下面代码,返回的引用个数分别是2和3,比预计的1和2多了一个,这是因为传递参数给getrefcount的时候产生了一个临时引用。
1 | a = [] |
总结:当出现以下情况时,某一对象的引用个数将增加:
对象被创建
p = Person(),增加1;对象被引用
p1 = p,增加1;- 对象被当作参数传入函数
func(object),增加2,原因是函数中有两个属性在引用该对象; - 对象存储到容器对象中
l = [p],增加1
当出现以下情况时,某一对象的引用个数将减少:
- 对象的别名被销毁
del p,减少1; - 对象的别名被赋予其他对象,减少1;
- 对象离开自己的作用域,如
getrefcount(object)方法,每次用完后,其对对象的那个引用就会被销毁,减少1; - 对象从容器对象中删除,或者容器对象被销毁,减少1。
Demo:代码如下:
1 | import sys |
运行结果:
1 | init 303 |
可以看到,在传入函数中后计数增加为2,而非设想的1,这是为什么?在知乎上有人提到:一个是函数func的参数arg对obj的引用,再一个是函数栈保存了入参对arg的引用。关于这个的详细分析,还可以看这篇文章。
垃圾回收机制
垃圾回收机制的主要作用为:用于解决引用计数机制无法释放的循环引用问题,同时提供了手动释放内存的接口。
python提供了del方法来删除某个变量,它的作用是让某个对象引用数减少1。当某个对象引用数变为0时并不是直接将它从内存空间中清除掉,而是采用垃圾回收机制gc模块,当这些引用数为0的变量规模达到一定规模,就自动启动垃圾回收,将那些引用数为0的对象所占的内存空间释放。
gc模块采用了分代回收方法,将对象根据存活的时间分为三代:
- 所有新建的对象都是0代,当0代对象经过一次自动垃圾回收,没有被释放的对象会被归入1代,同理1代归入2代。
- 每次当0代对象中引用数为0的对象超过700个时,启动一次0代对象扫描垃圾回收;
- 经过10次的0代回收,就进行一次0代和1代回收;
- 1代回收次数超过10次,就会进行一次0代、1代和2代回收。
而这里的几个值是通过查询get_threshold()返回(700,10,10)得到的。此外,gc模块还提供了手动回收的函数,即gc.collect()。
而垃圾回收还有一个重要功能是,解决循环引用的问题,通常发生在某个变量a引用了自己或者变量a与b互相引用。考虑引用自己的情况,可以从下面的例子中看到,a所指向的内存对象有3个引用,但是实际上只有2个变量,假如把这两个变量都del掉,对象引用个数还是1,没有变成0,这种情况下,如果只有引用计数的机制,那么这块没有用的内存会一直无法释放掉。
1 | from sys import getrefcount |
因此python的gc模块利用了“标记-清除”法,即认为有效的对象之间能通过有向图连接起来,其中图的节点是对象,而边是引用,下图中obj代表对象,ref代表引用,从一些不能被释放的对象节点出发(称为root object,一些全局引用或者函数栈中的引用,例如下图的obj_1,箭头表示obj_1引用了obj_2)遍历各代引用数不为0的对象。在Python源码中,每个变量不仅有一个引用计数,还有一个有效引用计数gc_ref,后者一开始等于前者,但是启动标记清除法开始遍历对象时,从root object出发(初始图中的gc_ref为(1,1,1,1,1,1,1)),当对象 i 引用了对象 j 时,将对象 j 的有效引用个数减去1,这样下图中各个对象有效引用个数变为了(1, 0, 0, 0, 0, 0, 0),接着将所有对象分配到两个表中,一个是reachable对象表,一个是unreachable对象表,root object和在图中能够直接或者间接与它们相连的对象就放入reachable,而不能通过root object访问到且有效引用个数变为0的对象作为放入unreachable,从而通过这种方式来消去循环引用的影响。
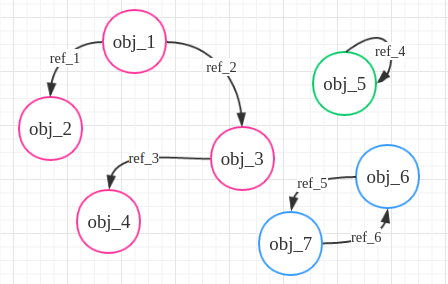
在人工调用gc.collect()的时候会有一个返回值,这个返回值就是这一次扫描unreachable的对象个数。在上面谈到的每一代的回收过程中,都会启用“标记-清除”法。
上述内容参考自内存管理,关于“标记-清除”法暂时还没看懂,这里先记录下来。
Python中的拷贝
拷贝与深拷贝
在Python中,如果直接使用a=b的方式,其实是新增了对象的引用,变量a和b指向同一个对象,因而对两个变量中的任何一个进行修改都会导致原始对象的修改。
为了使用拷贝,我们需要使用copy模块,在Python中将拷贝分为浅拷贝(copy)和深拷贝(deepcopy),对于一般的对象来说,浅拷贝和深拷贝不存在区别。但对于一些较为复杂的对象,例如嵌套的list将会产生区别。
当对嵌套list使用浅拷贝时,实际上拷贝的时list里各个对象的引用,将list中各个对象的引用存放到了新的内存地址,浅拷贝示意如下:
1 | import copy |
对于b = a: 赋值引用,a 和 b 都指向同一个对象。
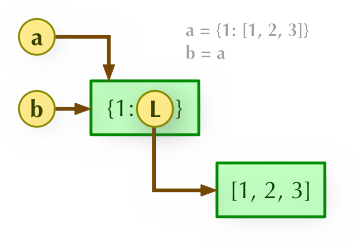
copy对于一个复杂对象的子对象并不会完全复制,什么是复杂对象的子对象呢?就比如序列里的嵌套序列,字典里的嵌套序列等都是复杂对象的子对象。对于子对象,Python会把它当作一个公共镜像存储起来,所有对他的复制都被当成一个引用,所以说当其中一个引用将镜像改变了之后另一个引用使用镜像的时候镜像已经被改变了,如下图所示,b = a.copy() 浅拷贝,a 和 b 是一个独立的对象,但他们的子对象还是指向统一对象(是引用)。

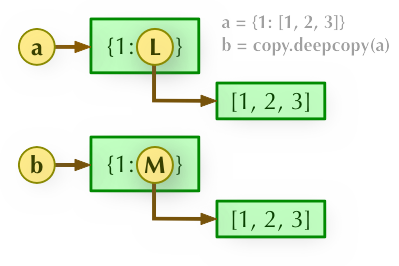
而对于深拷贝deepcopy而言,会将对象中的每一个子对象复制为一个单独的个体,因而复制之后得到的对象和原始对象互不影响,如下图所示,b = copy.deepcopy(a)深度拷贝, a 和 b 完全拷贝了父对象及其子对象,两者是完全独立的。
嵌套list的坑
Python中有一种内置的数据类型叫列表,它是一种容器,可以用来承载其他的对象(准确的说是其他对象的引用),列表中的对象可以称为列表的元素,很明显我们可以把列表作为列表中的元素,这就是所谓的嵌套列表。嵌套列表可以模拟出现实中的表格、矩阵、2D游戏的地图(如植物大战僵尸的花园)、棋盘(如国际象棋、黑白棋)等。但是在使用嵌套的列表时要小心,否则很可能遭遇非常尴尬的情况,下面是一个小例子。
1 | names = ['关羽', '张飞', '赵云', '马超', '黄忠'] |
我们希望录入5个学生3门课程的成绩,于是定义了一个有5个元素的列表,而列表中的每个元素又是一个由3个元素构成的列表,这样一个列表的列表刚好跟一个表格是一致的,相当于有5行3列,接下来我们通过嵌套的for-in循环输入每个学生3门课程的成绩。程序执行完成后我们发现,每个学生3门课程的成绩是一模一样的,而且就是最后录入的那个学生的成绩。
要想把这个坑填平,我们首先要区分对象和对象的引用这两个概念,而要区分这两个概念,还得先说说内存中的栈和堆。我们经常会听人说起“堆栈”这个词,但实际上“堆”和“栈”是两个不同的概念。众所周知,一个程序运行时需要占用一些内存空间来存储数据和代码,那么这些内存从逻辑上又可以做进一步的划分。对底层语言(如C语言)有所了解的程序员大都知道,程序中可以使用的内存从逻辑上可以为五个部分,按照地址从高到低依次是:栈(stack)、堆(heap)、数据段(data segment)、只读数据段(static area)和代码段(code segment)。其中,栈用来存储局部、临时变量,以及函数调用时保存现场和恢复现场需要用到的数据,这部分内存在代码块开始执行时自动分配,代码块执行结束时自动释放,通常由编译器自动管理;堆的大小不固定,可以动态的分配和回收,因此如果程序中有大量的数据需要处理,这些数据通常都放在堆上,如果堆空间没有正确的被释放会引发内存泄露的问题,而像Python、Java等编程语言都使用了垃圾回收机制来实现自动化的内存管理(自动回收不再使用的堆空间)。所以下面的代码中,变量a并不是真正的对象,它是对象的引用,相当于记录了对象在堆空间的地址,通过这个地址我们可以访问到对应的对象;同理,变量b是列表容器的引用,它引用了堆空间上的列表容器,而列表容器中并没有保存真正的对象,它保存的也仅仅是对象的引用。
1 | a = object() |
知道了这一点,我们可以回过头看看刚才的程序,我们对列表进行[[0] * 3] * 5操作时,仅仅是将[0, 0, 0]这个列表的地址进行了复制,并没有创建新的列表对象,所以容器中虽然有5个元素,但是这5个元素引用了同一个列表对象,这一点可以通过id函数检查scores[0]和scores[1]的地址得到证实。这句代码所创建的内存的分布如下图所示:

所以正确的代码应该按照如下的方式进行修改。
1 | names = ['关羽', '张飞', '赵云', '马超', '黄忠'] |
或者
1 | names = ['关羽', '张飞', '赵云', '马超', '黄忠'] |
内存分布方式如下:
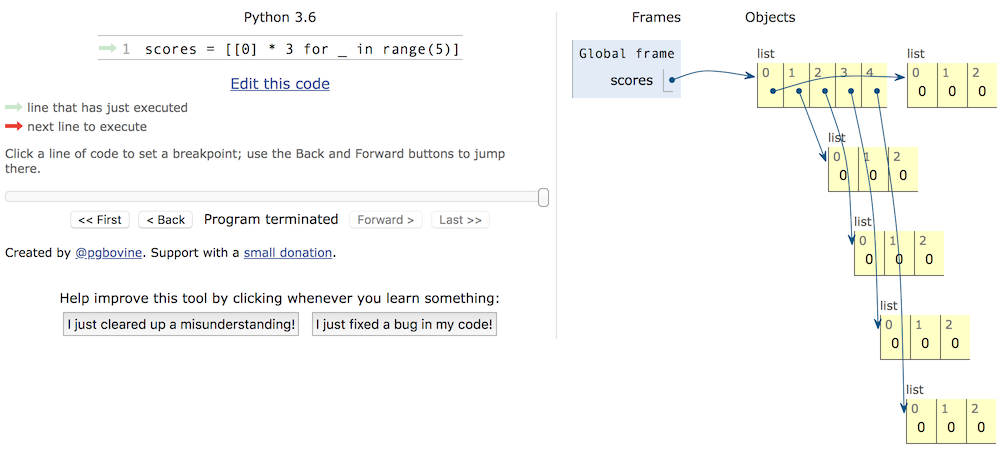
如果对内存的使用不是很理解,可以看看PythonTutor网站上提供的代码可视化执行功能,通过可视化执行,我们可以看到内存是如何分配的,从而避免在使用嵌套列表或者复制对象时可能遇到的坑。
参考
Python的内存管理机制
那些年我们踩过的那些坑)
[Python]内存管理
Python垃圾回收机制详解
python为什么调用函数会令参数对象引用计数+2? - Prodesire的回答 - 知乎
Python深入06 Python的内存管理
Python 直接赋值、浅拷贝和深度拷贝解析

