图像相关任务大纲

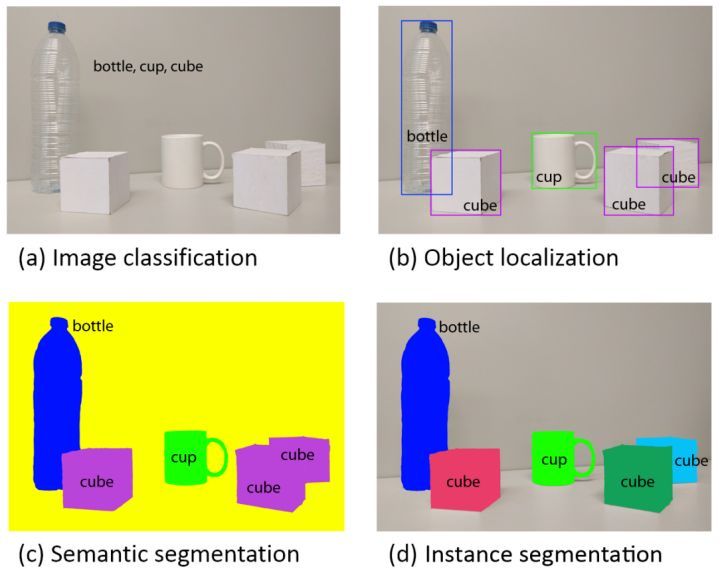
计算机视觉旨在识别和理解图像/视频中的内容,包含四大基本任务:分类(图a)、定位、检测(图b)、语义分割(图c)、和实例分割(图d)。
图像分类
如果你开始了解深度学习的图像处理, 你接触的第一个任务一定是图像分类 :
比如把你的爱猫输入到一个普通的CNN网络里, 看看它是喵咪还是狗狗。


一个最普通的CNN, 比如像这样几层的CNN鼻祖Lenet, 如果你有不错的数据集(比如kaggle猫狗大战)都可以给出一个还差强人意的分类结果(80%多准确率), 虽然不是太高。
当然,如果你再加上对特定问题的一些知识, 也可以顺便识别个人脸啥的。

会玩的, 也可以顺别识别个猪脸什么哒(我觉得长得都一样哦), 这样搞出来每个猪的身份, 对于高质量猪肉的销售, 真是大有裨益的。

或者看看植物都有个什么病害什么的,像这样不同的病斑, 人都懒得看的, 它可以给你看出来。 植物保护的人可以拿着手机下田了。

虽然植物保护真的很好用,分类问题还真是挺无聊的。
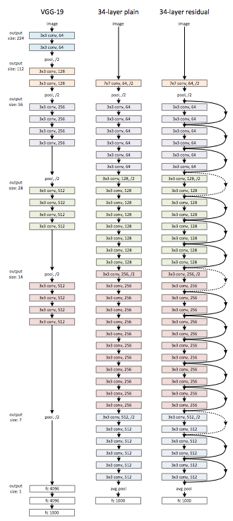
我们进化的方向,也就是用更高级的网络结构取得更好的准确率,比如像下图这样的残差网络(已经可以在猫狗数据集上达到99.5%以上准确率)。分类做好了你会有一种成为深度学习大师,拿着一把斧子眼镜里都是钉子的幻觉。 分类问题之所以简单, 一要归功于大量标记的图像, 二是分类是一个边界非常分明的问题, 即使机器不知道什么是猫什么是狗, 看出点区别还是挺容易的, 如果你给机器几千几万类区分, 机器的能力通过就下降了(再复杂的网络,在imagenet那样分1000个类的问题里,都很难搞到超过80%的准确率)。
总结:图像分类就是输入图片,判定该图片所属的类别。
图像识别
图像识别是对分类的扩展,我认为图像分类输入数据为图片,而识别有可能输入为segment,或者定义的对象(Object),或者图片本身。
图像识别和分类有的时候也可以混为一谈。
总结:图像识别是一个基于分类(Classification)的问题,即是在所有的给定数据中,分类出哪一些sample是目标,哪一些不是。还是拿图片作为数据举例,这个分类的层面往往不是pixel,给定的一些segment,或者定义的对象(Object),或者图片本身。
物体检测
很快你发现,分类的技能在大部分的现实生活里并没有鸟用。因为现实中的任务啊, 往往是这样的:

或者这样的:
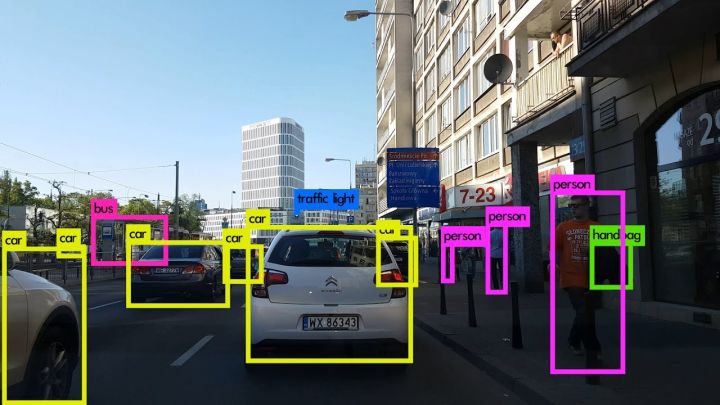
那么多东西在一起,你拿猫狗大头照训练的分类网络一下子就乱了阵脚。即使是你一个图片里有一个猫还有一个狗,甚至给猫加点噪声,都可以使你的分类网络分寸大乱。
现实中,哪有那么多图片,一个图里就是一个猫或者美女的大图,更多的时候,一张图片里的东西, 那是多多的,乱乱的,没有什么章法可言的,你需要自己做一个框,把你所需要看的目标给框出来,然后,看看这些东西是什么 。
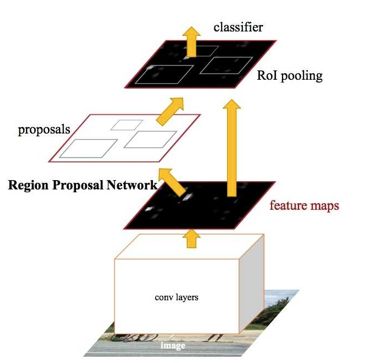
于是你来到机器视觉的下一层挑战-目标检测(从大图中框出目标物体并识别), 随之而来的是一个新的网络架构, 又被称为R-CNN, 图片检测网络,这个网络不仅可以告诉你分类,还可以告诉你目标物体的坐标,即使图片里有很多目标物体, 也一一给你找出来。
万军斩你首级那是杠杠的,在众多路人甲中识别嫌疑犯,也是轻而易举, 安防的人听着要按捺不住了。
今年出现的YOLO算法更是实现了快速实时的物体检测,你一路走过就告诉你视线里都有什么在哪里,要知道这在无人驾驶里是何等的利器。
当然, 到这里你依然最终会觉得无聊, 即使网络可以已经很复杂, 不过是一个CNN网络(推荐区域),在加上一层CNN网络做分类和回归。
总结:不仅可以告诉你分类,还可以告诉你目标物体的坐标。
目标定位
定位是在图像分类的基础上,进一步判断图像中的目标具体在图像的什么位置,通常是以包围盒的(bounding box)形式。在目标定位中,通常只有一个或固定数目的目标,而目标检测更一般化,其图像中出现的目标种类和数目都不定。
总结:find certain object (bounding box)
目标跟踪
应该是Target Tracking。这个任务很重要的第一点是目标定位(Target Locating),而且这个任务设计到的数据一般具有时间序列(Temporal Data)。常见的情况是首先Target被Identify以后,算法或者系统需要在接下来时序的数据中,快速并高效地对给定目标进行再定位。任务需要区别类似目标,需要避免不要的重复计算,充分利用好时序相关性(Temporal Correlation),并且需要对一些简单的变化Robust,必须旋转,遮盖,缩小放大,Motion Blur之类的线性或者非线性变化。下面是一个Target Detection的栗子:

总结:目标跟踪就是从视频流中跟踪特定的目标,要能够得到目标的位置(可以不知道类别)
图像分割
若你不仅需要把图片中边边角角的物体给检测出来,你还要做这么一个猛料的工作,就是把它从图片中扣出来。要知道,刚出生的婴儿分不清物体的边界,比如桌上有苹果这种事,什么是桌子,什么是苹果,为什么苹果不是占在桌子上的? 所以,网络能不能把物体从一个图里抠出来,事关它是否真的像人一样把握了视觉的本质。这也算是对它的某种“图灵测试” 。而把这个问题简化,我们无非是在原先图片上生成出一个原图的“mask”,面具有点像phtoshop里的蒙版的东西。


注意,这个任务里,我们是要从一个图片里得到另一个图片哦! 生成的面具是另一个图片, 这时候,所谓的U型网络粉墨登场,注意这是我们的第一个生成式的模型。 它的组成单元依然是卷积,但是却加入了maxpooling的反过程升维采样。
这个Segmentation任务, 作用不可小瞧哦, 尤其对于科研口的你, 比如现在私人卫星和无人机普及了,要不要去看看自己小区周围的地貌, 看是不是隐藏了个金库? 清清输入, 卫星图片一栏无余。 哪里有树, 哪里有水,哪里有军事基地,不需要人,全都给你抠出来。

另外,还有一些针对其他数据的目标分割,比如hyperspectral data,也需要分割哪些频率或者通道对应的是目标。比如视频流,那段时间对应是目标。
总结:对于图像,Segmentation可以是一个像素级别的分类(classificatio)问题,就是把每一个pixel做labeling,提出感兴趣的那一类label的像素。也可以是clustering的问题,即是不知道label,但需要满足一些optimality,比如要cluster之间的correlation最小之类的。
参考
图像识别中,目标分割、目标识别、目标检测和目标跟踪这几个方面区别是什么? - Bihan Wen的回答 - 知乎
图像识别中,目标分割、目标识别、目标检测和目标跟踪这几个方面区别是什么? - 许铁-巡洋舰科技的回答 - 知乎
图像识别中,目标分割、目标识别、目标检测和目标跟踪这几个方面区别是什么? - wendy的回答 - 知乎
图像识别中,目标分割、目标识别、目标检测和目标跟踪这几个方面区别是什么? - 张皓的回答 - 知乎

