Ubuntu16.04配置
更改Ubuntu源
所谓源,可以理解为Ubuntu从何处下载软件。默认的源是server for china,个人测试这是从美国的服务器下载软件进行安装的,为了加快下载安装软件的速度,我们通常把软件源更改为国内的服务器。
打开软件中心,找到Software&Updates:

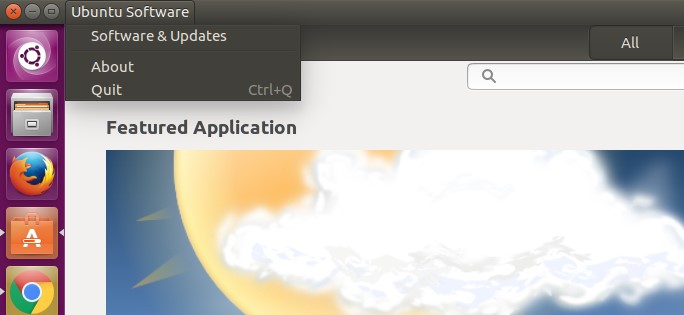
选择updates那个选项,出现
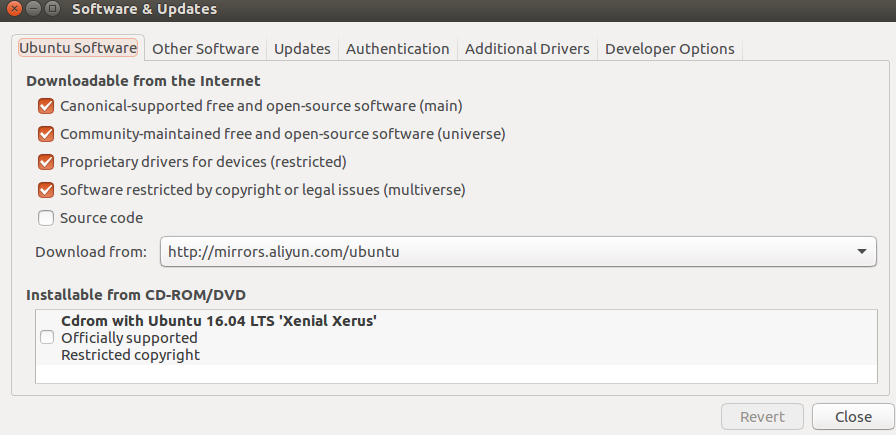
从Download from那个选项里面选择就行,比如我是用的阿里云的。然后关闭,reload即可。
安装一些依赖项目,这里安装的依赖项是为后面的安装做准备的,反正是要安装的(当然后面还有一些要安装),这里一行一行复制到你的命令行执行就行。
1 | sudo apt-get install libprotobuf-dev libleveldb-dev libsnappy-dev libopencv-dev libhdf5-serial-dev protobuf-compiler |
要是上面的安装出现了一些问题,随时执行下面指令:
1 | sudo apt-get update |
Pip换源
先安装pip管理工具
1 | sudo apt install python3-pip |
修改 ~/.pip/pip.conf (没有就创建一个), 内容如下:
1 | [global] |
conda换源
使用命令gedit ~/.condarc,然后写入如下内容:
1 | channels: |
运行 conda clean -i 清除索引缓存,保证用的是镜像站提供的索引。
另外,需要更改miniconda文件夹的权限,否则写不进去。我这里的安装路径为/home/zdaiot/miniconda3/,用户名为zdaiot
1 | sudo chown -R zdaiot /home/zdaiot/miniconda3/ |
the system is running in low-graphics mode
比较高级的显卡,例如泰坦V,在安装完毕系统后提示重启。但是重启后出现了下图
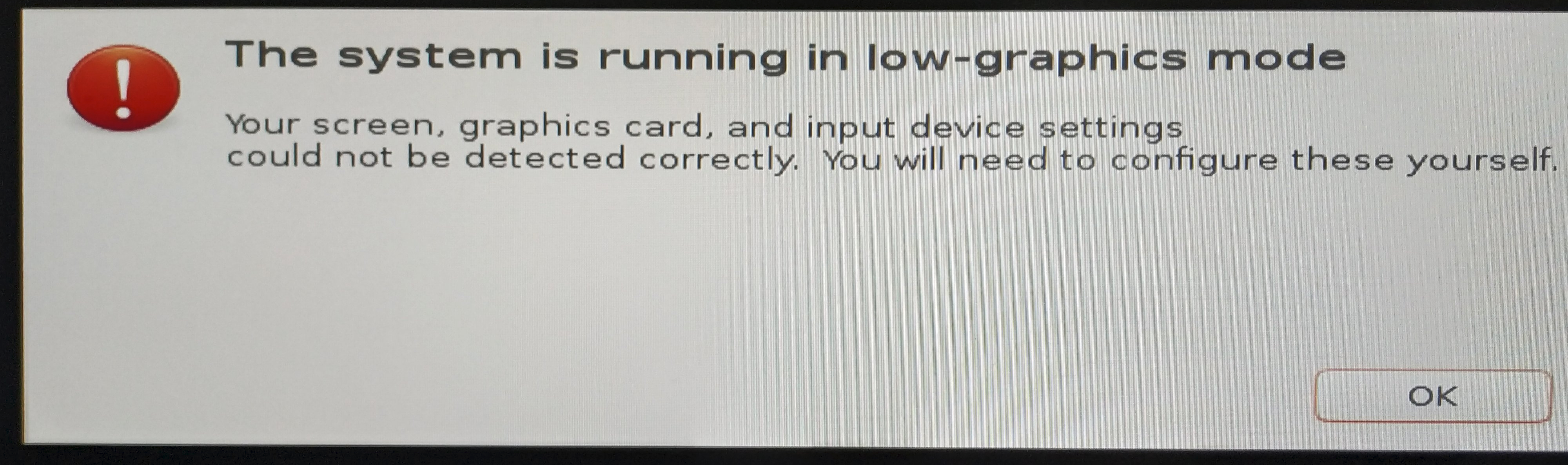
解决方法:在Ubuntu grub的启动选项中选择ubuntu高级选项->recovery mode->resume,即可正常进入界面,接着按照下面的方式安装NVIDIA驱动,重启即可。
在只有Ubuntu系统的时候,开机是无法找到grub引导界面的。这时进入Ubuntu系统的tty界面,备份/etc/default/grub文件 打开/etc/default/grub文件,找到 GRUB_HIDDEN_TIMEOUT=0 这行,使用#注释掉,变成#GRUB_HIDDEN_TIMEOUT=0,然后执行下面命令
1 | sudo update-grub |
更新内核后显卡驱动异常
如果在Ubuntu内核更新后,显卡驱动异常,具体体现为屏幕分辨率异常。重装NVIDIA驱动也无法正常安装。
解决方法为:在Ubuntu grub的启动选项中选择ubuntu高级选项-旧内核启动系统。
安装NVIDIA显卡驱动
下面方法一与方法二,若不适用NVIDIA作为显示,则可以不干掉nouveau nvidia驱动(即下面的第2步),但是还是推荐干掉它,防止意外。
安装之前要先关闭secret boot,对于华硕主板bios,进入cms打开只有uefi启动,然后进入secret boot,改windows uefi为other uefi
若把显示器接到显卡上,发现没有亮屏。则进入Bios->高级->高级\北桥\显示设置,将首选显卡改为Auto,初始化iGPU改为关闭(这里以华硕主板为例)。
若本来驱动正常,忽然挂了,考虑是因为Ubuntu内核更新导致的,启动Ubuntu的时候,选择高级启动选项,进入旧的内核方式启动即可。
CUDA版本和英伟达驱动版本对应可以在这里找到。驱动和cudnn的版本要对应上。
安装
这里提供了三种安装驱动的方法,保险起见,因选择方法一或者方法三;而为了方便的话,建议选择方法二。
方法一:在线安装驱动
1.卸载你电脑中此刻有的nvidia的驱动。(复制命令就行,方便,后面也一样)
1 | sudo apt-get remove --purge nvidia* |
运行了这个命令之后,你系统中的NVIDIA、的一些驱动就应该被卸载了。
如果在之前安装过驱动,此时可能用上面指令卸载不完全,可以使用如下指令
1 | sudo /usr/bin/nvidia-uninstall |
2.然后干掉Ubuntu自带的nouveau nvidia驱动,刚装的系统木有vim ,gedit这个图形的还不错嘛
1 | sudo gedit /etc/modprobe.d/blacklist-nouveau.conf |
打开后把这些复制进去
1 | blacklist nouveau |
保存 ,更新一个
1 | sudo update-initramfs -u |
接着重启,使用下这个命令看看nouveau有没有被干掉,若什么也没有输出,则已经被干掉了
1 | lsmod | grep nouveau |
3.添加一个PPA到系统,等一下安装驱动要用的。复制下面的话命令就行(放在这里是因为你现在还在图形界面,复制方便)
1 | sudo add-apt-repository ppa:graphics-drivers/ppa |
复制完上面那个命令执行之后,千万记得
1 | sudo apt-get update |
4.上面的准备工作做完,按CTRL+ATL+F1进入终端1(很基础的东西不用我解释啦),这个时候你应该就_脱离图形界面_进入字符界面了(需要重新登录一次就登陆一次。),要是这个时候你看不到教程,还是推荐用手机或者平板或者其他的边看教程边操作。
在终端下面运行:
1 | sudo service lightdm stop |
打开右上角的设置,找到Software&Updates,接着找到Additional Drivers,即可查看适用于你电脑的显卡驱动。这里我的显示的是NVIDIA 384版本,然后运行:
1 | sudo apt-get install nvidia-384 |
5.重新进入图像化界面:
1 | sudo service lightdm start |
如果,你见到了久违的图像化熟悉界面,且没有卡在循环登陆界面,那么恭喜你,你已经通过了最难的一步。
方法二:离线安装驱动
英伟达显卡驱动Linux 64位(包括历史版本):下载地址
1.卸载你电脑中此刻有的nvidia的驱动。(复制命令就行,方便,后面也一样)
1 | sudo apt-get remove --purge nvidia* |
2.然后干掉Ubuntu自带的nouveau nvidia驱动,刚装的系统木有vim ,gedit这个图形的还不错嘛
1 | sudo gedit /etc/modprobe.d/blacklist-nouveau.conf |
打开后把这些复制进去
1 | blacklist nouveau |
保存 ,更新一个
1 | sudo update-initramfs -u |
接着重启,使用下这个命令看看nouveau有没有被干掉,若什么也没有输出,则已经被干掉了
1 | lsmod | grep nouveau |
3.按CTRL+ATL+F1进入终端1,登陆后在终端下面运行:
1 | sudo service lightdm stop |
找到自己从官网下载的run文件,然后cd到下载好的NVIDIA384.130驱动目录
先给个权限吧
1 | chmod 777 NVIDIA-Linux-x86_64-384.130.run |
执行下面指令安装!
1 | sudo ./NVIDIA-Linux-x86_64-384.130.run |
一路保持默认回车就行了。
之前我安装驱动的时候,会在后面加上
--no-opengl-files参数,加上这个参数会导致训练过程中其他界面渲染特别卡。所以对于台式机,不要加上这句话了(笔记本有待验证)。加上这句话在系统设置中可以看到图形那一栏是llvmpipe (LLVM 6.0, 256 bits),这其实没有装好。
4.重新进入图像化界面:
1 | sudo service lightdm start |
如果,你见到了久违的图像化熟悉界面,且没有卡在循环登陆界面,那么恭喜你,你已经通过了最难的一步。
方法三:setting中的驱动
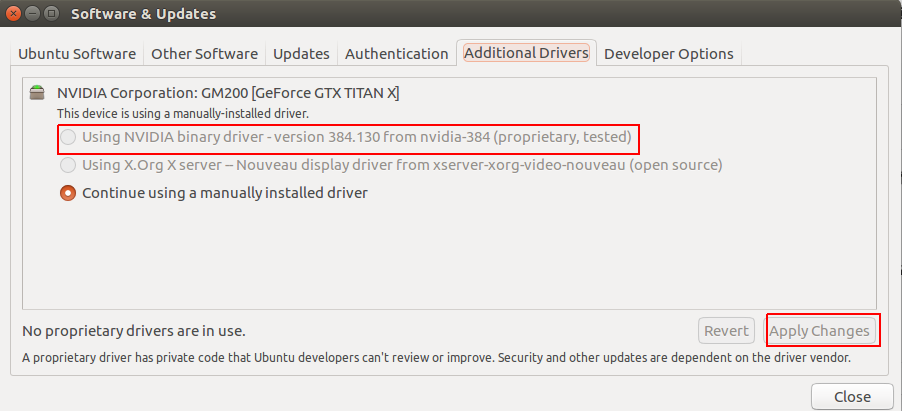
有的时候,利用离线安装驱动的方法会遇到莫名其妙的问题,可以试试System Setting中的驱动,如下图选择using NVIDIA binary driver选项(因为我这里已经手动安装过了,所以是灰色),然后点击Apply Changes。
测试
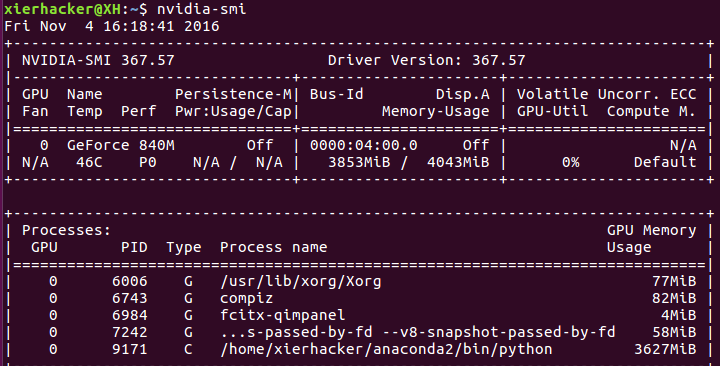
无论通过2.1中的方法一还是2.2中的方法二,没有卡在登陆界面,可以通过运行:
1 | nvidia-smi |
来看是不是能够输出你的GPU的一些信息。要是不能够输出的话,重启。能够输出的话,也建议重启一次。
Bug
Bug1
若出现sudo service lightdm stop无法关闭图像化界面,出现运行上述语句直接跳转到登陆界面,上述语句改为:
1 | `systemctl disable lightdm.service` |
则对应的方法一与方法二的第4步改为:
1 | # 开启图形界面命令 |
Bug2
如果是服务器的u,麻烦了不带核显。。遇到开机黑的情况
进入grub界面后,第三行有一个“高级选项”,选择后,按下“e”键进入编辑模式,找到“linux”那一行,将光标移动到这一行最后,先按下空格键加一个空白,然后输入
1 | acpi_osi=linux nomodeset |
应该可以,待测试
如果你有便宜的亮机卡,先插上去开机也行呀
CUDA10.0+CUDNN
注意,不同于CUDA9版本对应的英伟达驱动为384版本,这里CUDA10对应的英伟达驱动为410版本。实测在384版本下,CUDA10无法使用。
找到CUDA10,平台选择如下所示,然后点击下载。
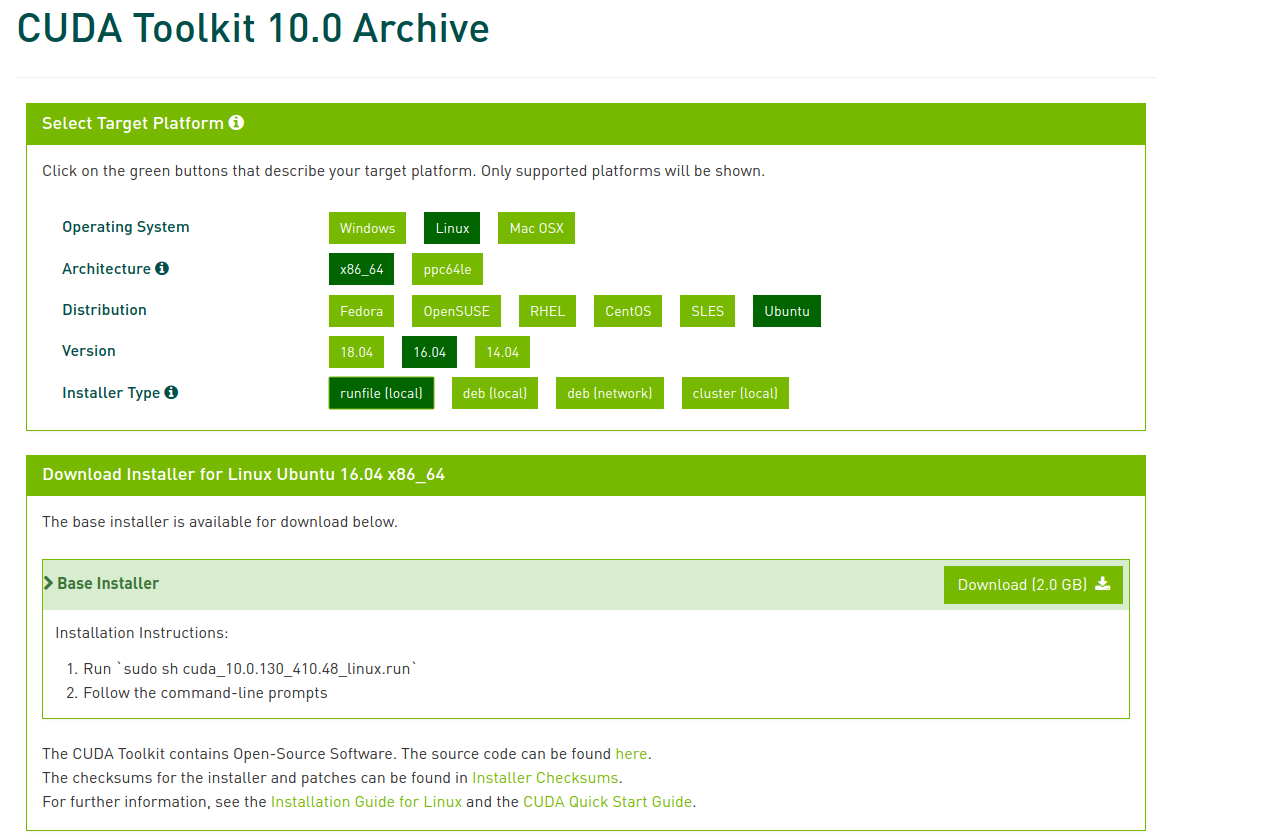
安装CUDA10.0
cd到你下载CUDA9.0的位置,运行
1 | sudo ./cuda_10.0.130_410.48_linux.run |
接着会出现很长很长的license让你看。之前都是老老实实的按键盘的下键,翻到最后,累到吐。后来查了查怎么调到最后,下面放大招,同时按住键盘的ctrl+C即可跳转到最后的一行。
注意:执行后会有一些提示让你确认,在第二个提示的地方,有个让你选择是否安装驱动时(Install NVIDIA Accelerated Graphics Driver for Linux-x86_64 410.48?),一定要选择否:因为前面我们已经安装了更加新的nvidia384,所以这里不要选择安装。总结安装过程如下
1 | Do you accept the previously read EULA? |
安装成功后,会出现类似于下面的语句:
1 | =========== |
接下来到了很关键的一步了,配置环境变量
运行下面语句来编辑.bashrc配置文件
1 | gedit ~/.bashrc |
在该文件的最后加上下面几句即可
1 | export PATH=/usr/local/cuda/bin${PATH:+:${PATH}} |
安装完毕后,来个自带的例子测一下。
1 | cd /usr/local/cuda-10.0/samples/1_Utilities/deviceQuery |
出现了下面的你的GPU的一些信息的话,就是真的安装成功了。
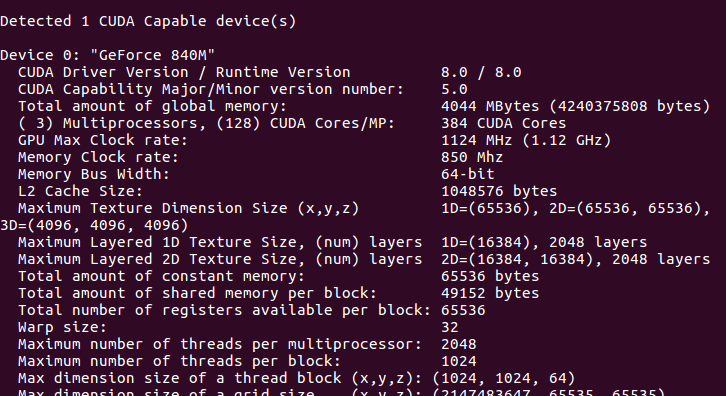
到这里,CUDA就安装成功了,其实不算是很难,注意一些情况就行了。
安装CUDNN7
这里需要一个NVIDIA的开发者账号,注册一个就OK,需要登陆后到cuDNN选择安装包,这里选择的版本对应cuda10版本的V7
cd到你下载CUDNN7的位置,运行下面语句即可,从下面语句可以看出来,CUDNN7不用安装,直接复制到对应路径即可
1 | // 如果下载的安装包是以.solitairetheme8结尾,则将文件名中.solitairetheme8替换为tgz即可 |
安装CUDNN8的时候,需要注意cuda/include不只有cudnn.h这一个文件,因此需要执行如下命令:
1 | sudo cp cuda/include/* /usr/local/cuda/include/ |
CUDA9.0+CUDNN
找到CUDA9,平台选择如下所示,然后点击下载。
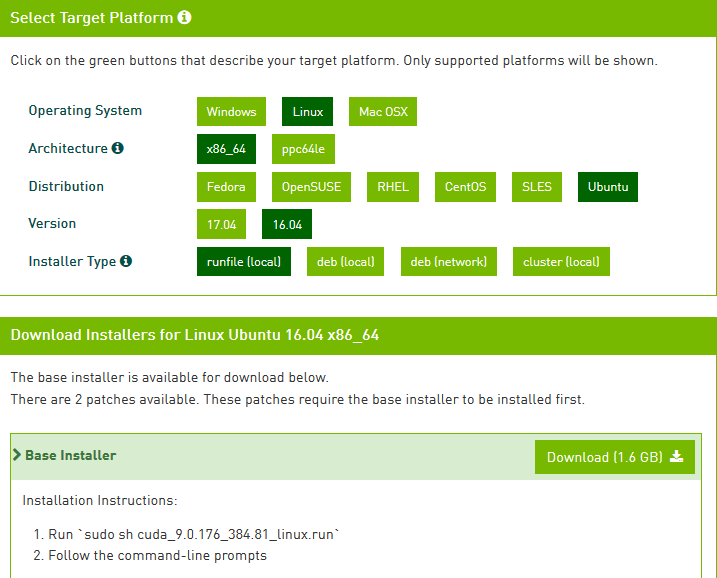
安装CUDA9.0
cd到你下载CUDA9.0的位置,运行
1 | sudo sh cuda_9.0.176_384.81_linux.run |
接着会出现很长很长的license让你看。之前都是老老实实的按键盘的下键,翻到最后,累到吐。后来查了查怎么调到最后,下面放大招,同时按住键盘的ctrl+C即可跳转到最后的一行。
注意:执行后会有一些提示让你确认,在第二个提示的地方,有个让你选择是否安装驱动时(Install NVIDIA Accelerated Graphics Driver for Linux-x86_64 384.81?),一定要选择否:因为前面我们已经安装了更加新的nvidia384,所以这里不要选择安装。然后其余的让你萱蕚选择yes/no/quit的时候均选择yes,没有选择项的直接回车保持默认即可
安装成功后,会出现类似于下面的语句:
1 | =========== |
接下来到了很关键的一步了,配置环境变量
运行下面语句来编辑.bashrc配置文件
1 | gedit ~/.bashrc |
在该文件的最后加上下面几句即可
1 | export PATH=/usr/local/cuda/bin${PATH:+:${PATH}} |
安装完毕后,来个自带的例子测一下。
1 | cd /usr/local/cuda-9.0/samples/1_Utilities/deviceQuery |
出现了下面的你的GPU的一些信息的话,就是真的安装成功了。
到这里,CUDA就安装成功了,其实不算是很难,注意一些情况就行了。
安装CUDNN7
这里需要一个NVIDIA的开发者账号,注册一个就OK,需要登陆后到cuDNN选择安装包,这里选择的版本是对应cuda9的V7
cd到你下载CUDNN7的位置,运行下面语句即可,从下面语句可以看出来,CUDNN7不用安装,直接复制到对应路径即可
1 | // 如果下载的安装包是以.solitairetheme8结尾,则将文件名中.solitairetheme8替换为tgz即可 |
卸载CUDA
在登陆界面状态下,按Ctrl + Alt + f1,进入TUI
执行
1 | sudo /usr/local/cuda-9.0/bin/uninstall_cuda_9.0.pl |
然后重启
1 | sudo reboot |
CUDA8.0+CUDNN
安装CUDA8.0
cd到你下载CUDA8.0的位置,运行
1 | sudo sh cuda_8.0.61_375.26_linux.run |
接着会出现很长很长的license让你看。之前都是老老实实的按键盘的下键,翻到最后,累到吐。后来查了查怎么调到最后,下面放大招,同时按住键盘的ctrl+C即可跳转到最后的一行。
注意:执行后会有一些提示让你确认,在第二个提示的地方,有个让你选择是否安装驱动时(Install NVIDIA Accelerated Graphics Driver for Linux-x86_64 375.26?),一定要选择否:因为前面我们已经安装了更加新的nvidia367,所以这里不要选择安装。然后其余的让你萱蕚选择yes/no/quit的时候均选择yes,没有选择项的直接回车保持默认即可
安装成功后,会出现类似于下面的语句:
1 | =========== |
接下来到了很关键的一步了,配置环境变量
运行下面语句来编辑.bashrc配置文件
1 | gedit ~/.bashrc |
在该文件的最后加上下面几句即可
1 | export PATH=/usr/local/cuda-8.0/bin${PATH:+:${PATH}} |
安装完毕后,来个自带的例子测一下。
1 | cd /usr/local/cuda-8.0/samples/1_Utilities/deviceQuery |
出现了下面的你的GPU的一些信息的话,就是真的安装成功了。
到这里,CUDA就安装成功了,其实不算是很难,注意一些情况就行了。
CUDNN安装
CUDA8.0对应的CUDNN版本有5.1和6两个版本,这两个版本使用与不同的深度学习框架,具体安装哪个根据自己的需求而定。这里需要一个NVIDIA的开发者账号,注册一个就OK,需要登陆后到cuDNN选择安装包
版本一:安装CUDNN5.1
下载完cudnn5.1之后进行解压
cd进入cudnn5.1解压之后的include目录,在命令行进行如下操作:
1 | sudo cp cudnn.h /usr/local/cuda/include/ #复制头文件 |
再将cd进入lib64目录下的动态文件进行复制和链接:
1 | sudo cp lib* /usr/local/cuda/lib64/ #复制动态链接库 |
执行完之后,cuDNN5.1算是安装完成了。
版本二:安装CUDNN6
下载完cudnn6之后进行解压,cd进入cudnn5.1解压之后的include目录,在命令行进行如下操作:
1 | sudo cp *.h /usr/local/cuda/include/ |
再将cd进入lib64目录下的动态文件进行复制和链接:
1 | sudo cp libcudnn* /usr/local/cuda/lib64/ |
执行完之后,cuDNN6算是安装完成了。
卸载CUDA
在登陆界面状态下,按Ctrl + Alt + f1,进入TUI
执行
1 | sudo /usr/local/cuda-8.0/bin/uninstall_cuda_8.0.pl |
然后重启
1 | sudo reboot |
Bug
若出现CUDA未安装成功的情况,尝试降级GCC,可能你下载的CUDA8.0最高支持的版本只到GCC5.3。
下载GCC源码并且解压
1 | wget ftp://mirrors.kernel.org/gnu/gcc/gcc-5.3.0/gcc-5.3.0.tar.gz |
下载编译所需依赖项:
1 | cd gcc-5.3.0 //进入解包后的gcc文件夹 |
建立编译输出目录:
1 | mkdir gcc-build-5.3.0 |
进入输出目录,执行以下命令,并生成makefile文件:
1 | cd gcc-build-5.3.0 |
编译(这里会花一点时间):
1 | make -j4 |
安装
1 | sudo make install |
弄好了,然后你可以看一下自己的gcc版本
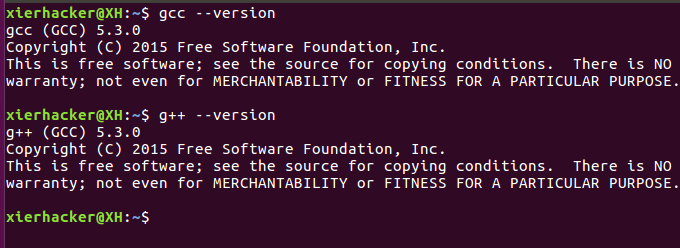
多个版本的CUDA并存
推荐下面第一种安装方法。
方法一
在我们安装CUDA的时候,发现默认建立了一个软连接。
1 | cd /usr/local |
可以看到cuda指向真正的地址。例如:cuda -> /usr/local/cuda-10.0。而我们在bashrc的时候,使用的是软连接地址,而非真实地址。因此,我们可以按照上述安装CUDA10.0与CUDA9.0的方法分别安装CUDA、CUDNN和设置环境变量。
然后,需要使用CUDA9.0的时候,使用下面命令,让cuda指向cuda9即可。
1 | sudo ln -s /usr/local/cuda-9.0 cuda |
若需要使用CUDA10.0,使用下面命令,让cuda指向cuda10即可。
1 | sudo ln -s /usr/local/cuda-10.0 cuda |
方法二
可以将两个版本的cuda安装到不同的地址,在bashrc文件中根据不同的安装位置设置不同版本cuda的环境,下面以CUDA9.0与CUDA8.0并存为例。
首先,按照步骤3中的安装cuda9.0的方法,装上cuda9.0。
然后,安装cuda8.0的时候,注意下面几个步骤的选择,其余的选择与上文中的步骤4一样。
1 | Enter Toolkit location |
安装cudnn的时候,注意复制的路径:
1 | sudo cp -a cuda/include/cudnn.h /home/ubuntu/cuda8/include/ |
运行下面语句来编辑.bashrc配置文件
1 | gedit ~/.bashrc |
在该文件的最后加上下面几句即可
1 | export PATH=/home/ubuntu/cuda8/bin${PATH:+:${PATH}} |
经过上述步骤,就完成了CUDA8.0和CUDA9.0的并存。想适应那个CUDA,只需要更改 .bashrc 文件中的环境变量即可。
值得注意的是,深度学习框架通常不同时支持cuda9.0与cuda8.0,所以当你切换CUDA版本的时候,需要重新安装适合对应CUDA版本的深度学习框架版本,这个比较无语
软件配置
Pycharm配置
Pycharm下会出现ImportError: libcublas.so.9.0: cannot open shared object file: No such file or directory的bug,更改为bin/pycharm.sh为如下的形式,对于pycharm2017.3.4以及以后版本,则要改第5行和第6行:
若改完之后启动Pycharm报错了,说找不到java类似的错误,将
LD_LIBRARY_PATH="$IDE_BIN_HOME:$LD_LIBRARY_PATH" "$JAVA_BIN" \这句话去掉。
1 | # |
或者可以采取下面方式修复该bug:
设置环境变量和动态链接库,在命令行输入:
1 | sudo gedit /etc/profile |
在打开的文件末尾加入:
1 | export PATH=/usr/local/cuda/bin:$PATH |
保存之后,创建链接文件:
1 | sudo gedit /etc/ld.so.conf.d/cuda.conf |
在打开的文件中添加如下语句:
1 | /usr/local/cuda/lib64 |
然后执行
1 | sudo ldconfig |
使链接立即生效。此时有可能会报什么 is not a symbol 之类的错了,忽略不计。
spyder
在启动器中直接点击spyder的图标,使用tensorflow的过程中,出现了ImportError: libcublas.so.9.0: cannot open shared object file: No such file or directory错误,若~/.bashrc已经有CUDA的环境配置,检查/usr/local/cuda-9.0/lib64下是否有 libcublas.so.9.0。如果有,终端输入:在终端执行sudo ldconfig /usr/local/cuda-9.0/lib64即可。
ldconfig 命令的用途,主要是在默认搜寻目录(/lib和/usr/lib)以及动态库配置文件/etc/ld.so.conf内所列的目录下,搜索出可共享的动态链接库(格式如前介绍,lib.so),进而创建出动态装入程序(ld.so)所需的连接和缓存文件,缓存文件默认为 /etc/ld.so.cache,此文件保存已排好序的动态链接库名字列表。
安装Opencv
方法一:非编译式
Opencv经常使用,以前经常采用编译的方法去安装Opencv,比较郁闷的是为啥Opencv只有Windows下的非编译安装方法。最近终于在论坛上找到了在Ubuntu下非编译安装方法,吓得我赶紧记录下来
for Python2:
1 | sudo apt-get install libopencv-dev |
for Python3:
1 | sudo pip3 install opencv-python |
方法二:编译式
编译的方法好处是,C++也能调用,以安装Opencv3.1为例
首先肯定是先安装依赖了,官方列出了一些:
1 | sudo apt-get install build-essential |
反正不管了,全部都装上去。
在你喜欢的地方建立一个工作目录,随便什么名字,就在home目录下面建立了一个OpenCV的目录
1 | mkdir OpenCV |
进入这个工作目录(OpenCV)然后用git克隆官方的项目(下载接受会需要一点时间,等待)
1 | cd Opencv |
克隆好了之后,你就会看见你的工作目录(OpenCV)下面有了两个项目的文件夹opencv了。
进入到你下载的那个opencv文件夹,这时候建立一个build的文件夹,用来接收cmake之后的文件。cd build进入到build里面,运行这句命令(直接复制就行):
1 | cmake -D CMAKE_BUILD_TYPE=RELEASE -D CMAKE_INSTALL_PREFIX=/usr/local .. |
这里要解释一下,后面是一个空格加上两个点,不要搞错了。
运行之后,下图表示cmake完成了。
这个时候的build下面也有了一些文件。你当然不用管这些是什么。
直接运行sudo make -j4,编译等待
make完成之后,再sudo make install就安装好了。
你能够在/usr/local中找到你新安装的opencv的一些头文件和库了。
这里要说明一下,要是中途出现了一些问题是与cuda有关的,打开opencv下面那个cmakelist文件把with_cuda设置为OFF,如下图,之后再cmake,再编译。
OK,OpenCV也到这里了。
TensorFlow
从此处可以看到tensorflow与cuda、cudnn的对应关系。如下图所示:

若你安装的是CUDA8.0,则需要指定TensorFLow版本,因为最新的版本是根据CUDA9.0编译的
1 | sudo pip install tensorflow-gpu==1.4.0 |
若安装的是CUDA9.0,也需要指令Tensorflow版本,因为CUDA9只支持到tensorflow1.12
1 | sudo pip install tensorflow-gpu==1.12.2 |
若安装的是CUDA10.0
1 | sudo pip install tensorflow-gpu |
然后就安装好啦,运行下面的代码检验一下
1 | import tensorflow as tf |
正确输出Hello, TensorFlow!的话,就表示安装成功啦。
Pytorch
点击这里,os选择Linux,Package Manager选择pip方式。接着根据Python和自己安装CUDA版本,按照下方提示安装即可。这里以CUDA9.0和Python3.5为例:

1 | sudo pip3 install http://download.pytorch.org/whl/cu90/torch-0.3.1-cp35-cp35m-linux_x86_64.whl |
注意对于cuda10环境下,若直接使用pip3 install torchvision,会导致出现from torchvision import _C ImportError: libcudart.so.9.0: cannot open shared object file:错误,我们需要官网查看torchvision的安装方法。例如对于Python3.7安装方式为
1 | pip3 install https://download.pytorch.org/whl/cu100/torchvision-0.3.0-cp37-cp37m-linux_x86_64.whl |
最简单的方式是可以使用anaconda的安装方式,同时还可以指定cuda版本:
1 | conda install pytorch torchvision cudatoolkit=9.0 |
当然也可以从这里找到所有的发行版本,然后下载相应版本。
PyTorch选择cuda的顺序
各个版本的CUDA:
- cuda:完整版的cuda
- cuda动态链接库:阉割版的cuda,只有cuda运行时需要的动态链接库。
- cudatoolkit:是conda提供的阉割版的cuda,只有cuda运行时需要的动态链接库。
pytorch选择cuda的顺序:
- 分为编译时的查找顺序和执行时的查找顺序
- 编译时的查找顺序由 torch/utils/cpp_extension.py的_find_cuda_home()决定。
- 执行的查找顺序由动态库的搜索路径决定
编译时的查找顺序
1、顺序总览
(1)环境变量CUDA_HOME 或 CUDA_PATH
(2)/usr/local/cuda
(3)which nvcc的上级上级目录(which nvcc 会在环境变量PATH中找)
(4)如果上述都不存在,则torch.utils.cpp_extension.CUDA_HOME为None,会使用conda安装的cudatoolkit,其路径为cudart 库文件目录的上级目录(此时可能是通过 conda 安装的 cudatoolkit,一般直接用 conda install cudatoolkit,就是在这里搜索到 cuda 库的)。
2、编译pytorch时的使用过cuda版本
1 | python -c "import torch;print(torch.version.cuda )" |
pytorch可能不是在你的电脑上编译的,这个版本代表pytorch在编译时,使用过的cuda版本。
这时候,我们只在本地有相应版本的cuda动态链接库,就可以使用别人已经编译好的pytorch,非常方便。
3、当编译一个新程序,会使用的cuda版本:
1 | python -c "import torch.utils.cpp_extension; print(torch.utils.cpp_extension.CUDA_HOME)" |
在很多时候,(比如安装apex,precious roipooling),我们需要使用cuda重新编译,这时候,我们需要的不仅仅是一个阉割版的cuda动态链接库,我们需要一个完整的cuda,以上的CUDA_HOME就是完整cuda的路径。
执行时的查找顺序
1、执行的查找顺序由动态库的搜索路径决定,搜索so文件的顺序如下
(1)gcc编译时指定的运行时库路径,如-rpath
(2)LD_LIBRARY_PATH
(3)/etc/ld.so.cache
(4)/lib,/usr/lib等
2、conda的查找顺序
1 | envname=my_env_pytorch17 |
可以看到,conda是通过rpath的方式实现的,先去查找lib。
1 | ls ~/miniconda3/envs/$envname/lib/ | grep libcudart.so |
可以看到,lib中包含一个libcudart.so.10.2.89,这就是安装的cudatoolkit,是10.2版本的。
Mxnet
按照这里的教程安装即可
这里以安装的CUDA9.0,Python3.5为例
1 | sudo pip3 install mxnet-cu90 |
查看Pytorch是否支持CUDA,并查看支持的CUDA版本。
1 | python -c "import torch; print(torch.cuda.is_available())" |
theano
for CUDA8.0
1 | sudo pip install theano |
直接复制下面的测试代码看是不是能够出来结果。
1 | from theano import function, config, shared, sandbox |

成功,但是这个时候使用的CPU来跑的。然后接下来的任务就是给他添加GPU加速。
在你的主目录下面,(就是你直接~/文件夹,后者你自己cd之后回车的那个文件夹)。
1 | sudo vim .theanorc |
建立一个.theanorc的文件。
文件中的的内容直接复制下面就行了。
1 | [global] |
保存。再次运行那个例子。得到结果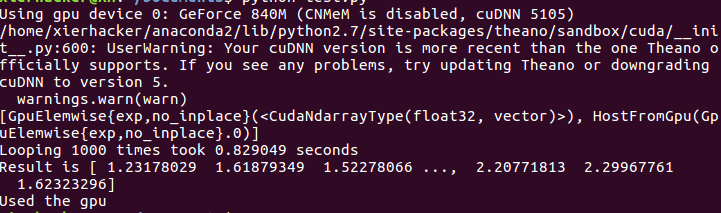
CPU那个用了30多秒,这个只用了0.8秒,说明GPU的加速还是有点用的。
至此,theano安装完成了。
for CUDA9.0 Or CDUA10.0
1 | sudo pip install theano |
在你的主目录下面,(就是你直接~/文件夹,后者你自己cd之后回车的那个文件夹)。
1 | sudo gedit .theanorc |
建立一个.theanorc的文件,如何使用GPU:http://deeplearning.net/software/theano/tutorial/using_gpu.html。
1 | [global] |
运行下面的例子,注意例子的命名不能是 theano.py,否则的话,导包错误
1 | from theano import function, config, shared, tensor |
运行:
1 | THEANO_FLAGS=device=cuda0 python test.py |
最后输出的是
若从cuda9.0升级到10.0,重新编译libgpuarray后,需要重新安装theano
Caffe
因为Caffe是最难安装的,因此就放到了最后了。废话不说多了。
首先你需要从github上面clone或者下载.zip的压缩包。效果是一样的。然后你得到一个cafffe-master的压缩包或者文件夹。进到这个文件夹里面,你会看到是这个样子的。
首先安装第三方依赖:
1 | sudo apt-get install libprotobuf-dev libleveldb-dev libsnappy-dev libopencv-dev libhdf5-serial-dev protobuf-compiler libgflags-dev libgoogle-glog-dev liblmdb-dev libatlas-base-dev libjpeg62 |
接着,你会看到其中有一个文件叫Makefile.config.example这个文件是官方给出了编译的“模板”,我们可以直接拿过来小小的修改一下就行。复制下面的命令把名字改为Makefile.config
1 | cp Makefile.config.example Makefile.config |
你会发现下面多了一个Makefile.config的文件
打开这个文件并且修改(我这里用的是vscode,你可以换成其他的编辑器比如vim):
1 | code Makefile.config |
你能够看到类似于这样的东西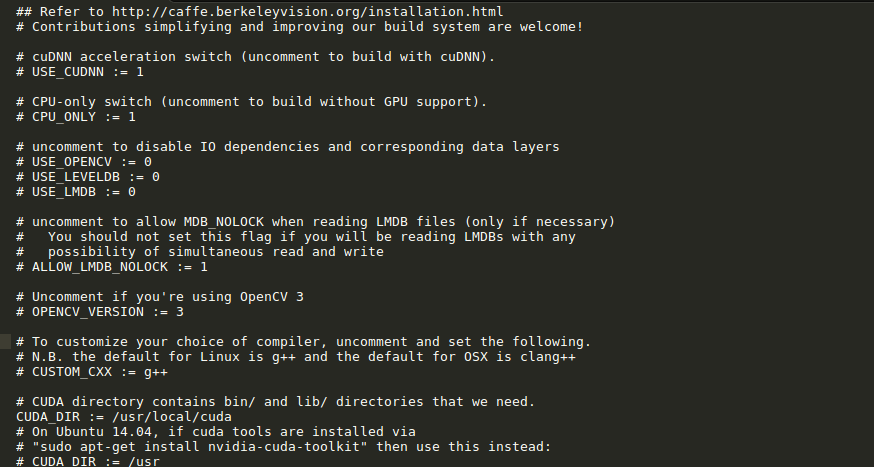
然后根据个人情况修改文件:
1) 若使用cudnn,则将#USE_CUDNN := 1修改成: USE_CUDNN := 1 (就是去掉注释的‘#’号)
2) 若使用cuda9,则注释掉-gencode arch=compute_20,code=sm_20 \和-gencode arch=compute_20,code=sm_21 \
在我的电脑上,在使用cuda9的情况下,没有注释掉
-gencode arch=compute_20,code=sm_21 \仍然可以编译过去,但是今天在一个笔记本上没有编译过去,所以大家按照Makefile.config文件中的要求——# For CUDA >= 9.0, comment the *_20 and *_21 lines for compatibility.注释掉吧~
3) 为了防止出现fatal error: hdf5.h: No such file or directory,将下面两行语句进行修改
1 | INCLUDE_DIRS := $(PYTHON_INCLUDE) /usr/local/include |
修改为:
1 | INCLUDE_DIRS := $(PYTHON_INCLUDE) /usr/local/include /usr/lib/x86_64-linux-gnu/hdf5/serial/include |
4) 解除下面几行的注释,可以使用Python 3 (default is Python 2,未成功)
1 | PYTHON_LIBRARIES := boost_python3 python3.5m |
编译,-j$(nproc)表示全部线程
1 | make all -j$(nproc) |
修改环境变量
gedit ~/.bashrc 打开 “.bashrc” 文件,在文件末尾加入如下代码并保存:
1 | # Set Caffe environment |
为验证安装成功,终端输入 ipython 或 python 进入Python解释器环境,输入:import caffe,不报错误代表caffe的Python接口可以使用。
报错
报错:fatal error: gflags/gflags.h: No such file or directory
1 | sudo apt-get install libgflags-dev |
报错:`fatal error: glog/logging.h: No such file or directory`
1 | sudo apt install libgoogle-glog-dev |
报错:mdb.h: No such file or directory
1 | sudo apt install liblmdb-dev |
报错:
/usr/bin/ld: cannot find -lcblas
/usr/bin/ld: cannot find -latlas
1 | sudo apt install libatlas-base-dev |
报错:
ImportError: libjpeg.so.62: cannot open shared object file: No such file or
1 | sudo apt install libjpeg62 |
报错:编译Python3的时候:
/usr/bin/ld: cannot find -lboost_python3
1 | cd /usr/lib/x86_64-linux-gnu |
报错:
pip3 安装出现:AttributeError: '_NamespacePath' object has no attribute 'sort'
I edited line #2121~2122 of this file: sudo vim /usr/local/lib/python3.5/dist-packages/pip/_vendor/pkg_resources/__init__.py
1 | #orig_path.sort(key=position_in_sys_path) |
报错:
CUDA9.0环境下,运行make runtest -j$(nproc)报下面的错:
1 | math_functions.cu:28] Check failed: status == CUBLAS_STATUS_SUCCESS (13 vs. 0) CUBLAS_STATUS_EXECUTION_FAILED |
解决方法:安装Patch 2 (Released Mar 5, 2018) 解决。但是在笔记本上失败了,推测是因为该笔记本的计算能力为2.1,但是在CUDA9.0下编译caffe需要comment the *_20 and *_21 lines for compatibility,所以会失败。因此,遇到这种情况可能需要降级到8.0解决~
报错:
1 | .build_release/src/caffe/proto/caffe.pb.h:4:0: error: unterminated #ifndef |
解决方法:编译caffe的时候,开个两个终端。关闭一个即可。
报错:
Python3下出现:Failed to include caffe_pb2, things might go wrong!
仍待解决
常见错误
cudnn链接库问题
例如报错:
1 | ImportError: libcudnn.so.7: cannot open shared object file: No such file or directory |
则进入/usr/local/cuda/lib64目录,使用ls -al指令查看是否有该链接库。
参考
ImportError: libcublas.so.9.0: cannot open shared object file: No such file or directory
cuda problem when training the model
Check failed: status == CUBLAS_STATUS_SUCCESS (13 vs. 0) CUBLAS_STATUS_EXECUTION_FAILED
Ubuntu 16.04 卸载Nvidia显卡驱动和cuda
tensorflow CUDA cudnn 版本对应关系
UBUNTU 系统开机没有grub启动项
Anaconda 清华源即将恢复!
Updating Anaconda Fails. Environment Not Writable Error
v0.3: Import error [CUDA10]
图形”llvmpipe (LLVM 6.0, 256 bits)”
解压 .solitairetheme8 文件
Anaconda 镜像使用帮助
解决pip安装超时的问题
【环境】pytorch选择cuda的顺序【关于cudatoolkit和/usr/local/cuda】

