归一化方式
为什么要进行数据归一化
在喂给机器学习模型的数据中,对数据要进行归一化的处理。
为什么要进行归一化处理,下面从寻找最优解这个角度给出自己的看法。
假定为预测房价的例子,自变量为面积,房间数两个,因变量为房价。
那么可以得到的公式为:
- 其中$x_1$代表房间数,$\theta_1$代表变量$x_1$前面的系数。
- 其中$x_2$代表房间数,$\theta_2$代表变量$x_2$前面的系数。
首先我们祭出两张图代表数据是否均一化的最优解寻解过程。
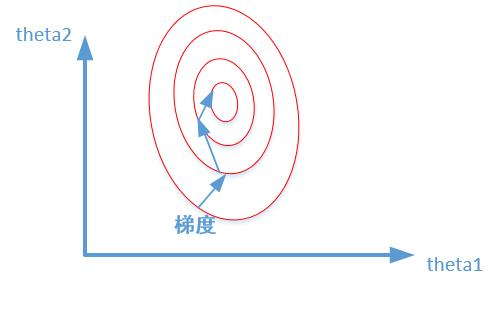
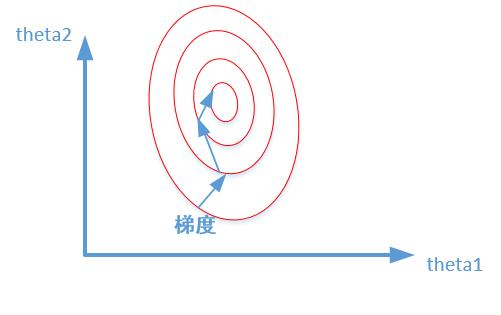
未归一化:
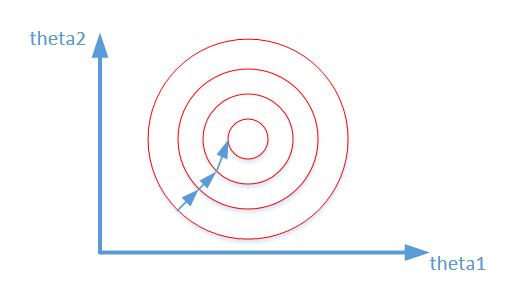
归一化之后
为什么会出现上述两个图,并且它们分别代表什么意思。
我们在寻找最优解的过程也就是在使得损失函数值最小的$\theta_1,\theta_2$。
上述两幅图代码的是损失函数的等高线。
我们很容易看出,当数据没有归一化的时候,面积数的范围可以从0~1000,房间数的范围一般为0~10,可以看出面积数的取值范围远大于房间数。
这样造成的影响就是在画损失函数的时候,
数据没有归一化的表达式,可以为:
造成图像的等高线为类似椭圆形状,最优解的寻优过程就是像下图所示:
而数据归一化之后,损失函数的表达式可以表示为:
其中变量的前面系数几乎一样,则图像的等高线为类似圆形形状,最优解的寻优过程像下图所示:
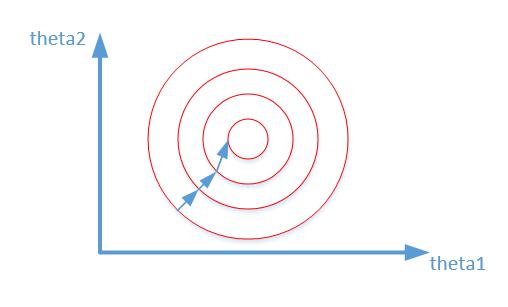
从上可以看出,数据归一化后,最优解的寻优过程明显会变得平缓,更容易正确的收敛到最优解。
这是数据为什么要归一化的一个原因。
另外一方面,在大型项目的数据分析中,由于数据来源的不同通常会导致数据的量纲、数据的量级产生差异,为了让这些数据具备可比性,需要采用标准化方法来消除这些差异。数据的标准化(normalization)就是指将原始各指标数据按比例缩放,去除数据的单位限制,将其转化为无量纲的纯数值,便于不同单位或量级的指标能够进行比较和加权。数据标准化最典型的就是数据的归一化处理,即将数据统一映射到[0,1]区间上。
目前数据标准化方法有多种,归结起来可以分为直线型方法(如极值法、标准差法)、折线型方法(如三折线法)、曲线型方法(如半正态性分布)。不同的标准化方法,对系统的评价结果会产生不同的影响,然而不幸的是,在数据标准化方法的选择上,还没有通用的法则可以遵循。常见的方法有:min-max标准化(min-max normalization)、log函数转换、atan函数转换、z-score标准化(zero-mena normalization,此方法比较常用)、模糊量化法。
min-max标准化(min-max normalization)也叫离差标准化,是对原始数据的线性变换,使结果落到[0,1]区间,转换函数如下:其中max为样本数据的最大值,min为样本数据的最小值。这种方法有一个缺陷就是当有新数据加入时,可能导致max和min的变化,需要重新定义。log函数转换是通过以10为底的log函数转换以实现归一下,具体方法如下:$y=log_{10}(x)/log_{10}(max)$,max为样本数据最大值,并且所有的数据都要大于等于1。atan函数转换用反正切函数实现数据的归一化:需要注意的是如果想使用这个方法映射到[0,1]的区间,则数据都应该大于等于0,小于0的数据将被映射到[-1,0]区间上。当然并非所有数据标准化的结果都需要映射到[0,1]区间上,这时就可以使用z-score标准化方法,该方法是SPSS中最为常用的标准化方法:z-score 标准化(zero-mean normalization)也叫标准差标准化,该方法使得经过处理的数据符合标准正态分布,即均值为0,标准差为1,其转化函数为:$y=(x−μ)/σ$,其中$μ$为所有样本数据的均值,$σ$为所有样本数据的标准差。
下面对三种常见的标准化方式进行介绍。
线性比例变换法
Python代码如下:
1 | import numpy as np |
极差变换法
- 这种方法有个缺陷就是当有新数据加入时,可能导致max和min的变化,需要重新定义。
- 除此之外,通过利用变量取值的最大值和最小值(或者最大值)将原始数据转换为界于某一特定范围的数据,从而消除量纲和数量级影响,改变变量在分析中的权重来解决不同度量的问题。该方法在对变量无量纲化过程中仅仅与该变量的最大值和最小值这两个极端值有关,而与其他取值无关,这使得该方法在改变各变量权重时过分依赖两个极端取值。
自定义Python代码如下:
1 | import numpy as np |
使用sklearn.preprocessing.MinMaxScaler类实现:
1 | import numpy as np |
0均值方法(Z-score方法)
- 即每一变量值与其平均值之差除以该变量的标准差。虽然该方法在无量纲化过程中利用了所有的数据信息,但是该方法在无量纲化后不仅使得转换后的各变量均值相同,且标准差也相同,即无量纲化的同时还消除了各变量在变异程度上的差异,从而转换后的各变量在聚类分析中的重要性程度是同等看待的。而实际分析中,经常根据各变量在不同单位间取值的差异程度大小来决定其在分析中的重要性程度,差异程度大的其分析权重也相对较大。
- z-score标准化方法适用于最大值和最小值未知的情况,或有超出取值范围的离群数据的情况。
- 若假设数据集是正态分布的,那么该方法归一化后会生成标准正太分布的数据集。
- 若更改了数据集,通常要重新计算方差和均值。
- 需要注意的是,我们只能在训练数据集上计算均值和方差,测试数据集和验证数据集都需要采用这个均值和方差,因为测试数据集对于你来说是一个黑盒子,你不能使用里面的任何先验信息。
自定义Python代码如下:
1 | import numpy as np |
使用sklearn.preprocessing.scale()函数,可以直接将给定数据进行标准化
1 | import numpy as np |
使用sklearn.preprocessing.StandardScaler类,使用该类的好处在于可以保存训练集中的参数(均值、方差)直接使用其对象转换测试集数据。
1 | import numpy as np |
分析
线性比例变换法和0均值方法(Z-score方法)得到的数据不一定分布在[0, 1]之间,并且分布区间通常不确定,而极差变换法得到的数据一定在[0,1]之间。
每个维度都是去量纲化的,避免了不同量纲的选取对距离计算产生的巨大影响。在分类、聚类算法中,需要使用距离来度量相似性的时候、或者使用PCA技术进行降维的时候,第三种方法(Z-score standardization)表现更好。在不涉及距离度量、协方差计算、数据不符合正太分布的时候,可以使用第一种方法或其他归一化方法。比如图像处理中,将RGB图像转换为灰度图像后将其值限定在[0 255]的范围。
那么在机器学习中哪些算法可以不做归一化呢?概率模型不需要归一化,因为它们不关心变量的值,而是关心变量的分布和变量之间的条件概率。像svm、线性回归之类的最优化问题就需要归一化。决策树属于前者。归一化也是提升算法应用能力的必备能力之一。
常用图像预处理方式
预处理方式一
输入图片 height, width
RESIZE_SIDE_MIN = 256
RESIZE_SIDE_MAX = 512
R_MEAN = 123.68G_MEAN = 116.78B_MEAN = 103.94
训练预处理
- scale = width < height ? small_size / width : small_size / height 其中 small_size 为 RESIZE_SIDE_MIN 到 RESIZE_SIDE_MAX 的随机数
- new_width = width scale new_height = height scale
- 用二分插值法将 (height, width) 转为 (new_height, new_width)
- 将 new_height, new_width 的图片 crop 为 crop_height(224), crop_width(224) 其中必须满足 new_height >= crop_height, new_width >= crop_width
- 将图片左右翻转(50% 的概率会翻转)
- RGB 分别减去其平均值,其中依次为 R_MEAN, G_MEAN B_MEAN
测试预处理
- 用二分插值法将 (height, width) 转为 (new_height, new_width) 其中 new_height = new_width = 256
- 从 crop 中心的 crop_height, crop_width
- RGB 分别减去其平均值,其中依次为 R_MEAN, G_MEAN B_MEAN
采用上述预处理方法的模型
- resnet_v1_50
- resnet_v1_101
- resnet_v1_152
- resnet_v1_200
- resnet_v2_50
- resnet_v2_101
- resnet_v2_152
- resnet_v2_200
- vgg
- vgg_a
- vgg_16
- vgg_19
预处理方式二
训练预处理
- 对图片进行随机 crop, 使其与 bbox 的重叠部分大于 0.1,长宽比在 (0.75, 1.33) 之间,croped 之后的图片大小为原图的(0.05, 1.0)。
- 将 crop 之后的图片大小 resize 为 crop_height(224), crop_width(224)
- 将 crop 图片左右翻转(50% 的概率会翻转)
- 调整 crop 图片的亮度(32. / 255.)和饱和度(0.5, 1.5)
- 每个元素减去 0.5,再乘以 2.0
测试预处理
- central crop
- 二分法插值,将图片变为 height, width
- 每个元素减去 0.5,再乘以 2.0
采用上述预处理方法的模型
- inception
- inception_v1
- inception_v2
- inception_v3
- inception_v4
- inception_resnet_v2
- mobilenet_v1
- nasnet_mobile
- nasnet_large
- pnasnet_large
参考
深度学习两种图像数据预处理具体方法
机器学习中常见的几种归一化方法以及原因
数据归一化及两种常用归一化方法
数据标准化的三种最常用方式总结(归一化)
数据进行归一化为什么这么重要!

