本文从图网络的现有论文中梳理出了目前图网络被应用最多的数据集,主要有三大类,分别是引文网络、社交网络和生物化学图结构,分类参考了论文《A Comprehensive Survey on Graph Neural Networks》。(结尾附数据集下载链接)
引文网络(Cora、PubMed、Citeseer)
引文网络,顾名思义就是由论文和他们的关系构成的网络,这些关系包括例如引用关系、共同的作者等,具有天然的图结构,数据集的任务一般是论文的分类和连接的预测,比较流行的数据集有三个,分别是Cora、PubMed、Citeseer,它们的组成情况如图1所示,Nodes也就是数据集的论文数量,features是每篇论文的特征,数据集中有一个包含多个单词的词汇表,去除了出现频率小于10的词,但是不进行编码,论文的属性是由一串二进制码构成,只用0和1表示该论文有无这个词汇。
文件构成以cora数据集为例,整个语料库中有2708篇论文。在词干堵塞和去除词尾后,只剩下1433个独特的单词。文档频率小于10的所有单词都被删除。数据集包含两个文件,cora.cites和cora.content。
文件构成
cora.cites文件
cora.cites文件中的数据如下:
1 | <ID of cited paper> <ID of citing paper> |
即被引用论文和包含引用的论文,刚好构成了一条天然的边。每行包含两个纸质id。第一个条目是被引用论文的标识,第二个标识代表包含引用的论文。链接的方向是从右向左。
如果一行由“论文1 论文2”表示,则链接是“论文1 <- 论文2”(论文2引用论文1)。可以通过论文之间的索引关系建立邻接矩阵adj。
邻接矩阵的写法如下:
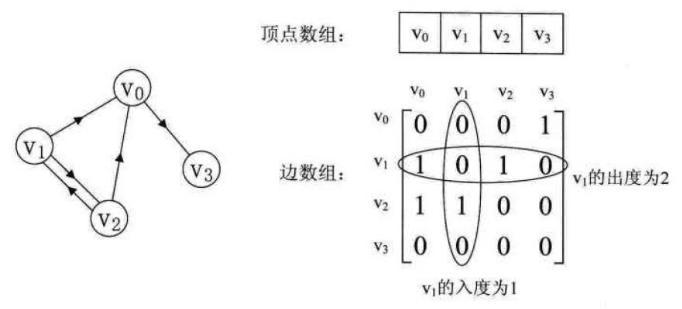
这里之所以将矩阵写出来,是因为注意
cora.cites文件中箭头的方向不是从通常的左到右的,而是从右到左的。例如有一行为1 2,那么邻接矩阵的值应该在第二行第一列!
ora.content文件
cora.content文件的数据如下:
1 | <paper id> <word attributes> + <class label> |
由论文id、上面说到的二进制码和论文对应的类别组成,其余两个数据集类似。
每行的第一个条目包含纸张的唯一字符串标识,后跟二进制值,指示词汇中的每个单词在纸张中是存在(由1表示)还是不存在(由0表示)。
最后,该行的最后一个条目包含纸张的类别标签。因此数据集的feature应该为2709×1433维度。第一行为idx,最后一行为label。
部分数据
1 | 31336 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 ... Neural_Networks |
社交网络(BlogCatalog、Reddit、Epinions)
BlogCatalog数据集是一个社会关系网络,图是由博主和他(她)的社会关系(比如好友)组成,labels是博主的兴趣爱好。Reddit数据集是由来自Reddit论坛的帖子组成,如果两个帖子被同一人评论,那么在构图的时候,就认为这两个帖子是相关联的,labels就是每个帖子对应的社区分类。Epinions是一个从一个在线商品评论网站收集的多图数据集,里面包含了多种关系,比如评论者对于另一个评论者的态度(信任/不信任),以及评论者对商品的评级。
文件构成
BlogCatalog数据集的结点数为10312,边条数为333983,label维度为39,数据集包含两个文件:
- Nodes.csv:以字典的形式存储用户的信息,但是只包含节点id。
- Edges.csv:存储博主的社交网络(好友等),以此来构图。
Epinions数据集包含文件如下:
- Ratings_data.txt:包含用户对于一件物品的评级,文件中每一行的结构为user_iditem_id rating_value。
- Trust_data.txt:存储了用户对其他用户的信任状态,存储方式为
source_user_id target_user_id trust_statement_value,其中信任状态只有信任和不信任(1、0)。
由于Reddit comments 数据集的文件太多,所以这里略过了,如果需要或者感兴趣的话,可以从文末的连接进入查看。
生物化学结构(PPI、NCI-1、NCI-109、MUTAG、QM9、Tox21)
PPI是蛋白质互作网络,数据集中共有24张图,其中20张作为训练,2张作为验证,2张作为测试,每张图对应不同的人体组织,实例如图3,该数据是为了从系统的角度研究疾病分子机制、发现新药靶点等等。
平均每张图有2372个结点,每个结点特征长度为50,其中包含位置基因集,基序集和免疫学特征。基因本体集作为labels(总共121个),labels不是one-hot编码。
NCI-1、NCI-109和MUTAG是关于化学分子和化合物的数据集,原子代表结点,化学键代表边。NCI-1和NCI-109数据集分别包含4100和4127个化合物,labels是判断化合物是否有阻碍癌细胞增长得性质。MUTAG数据集包含188个硝基化合物,labels是判断化合物是芳香族还是杂芳族。
QM9数据集包括了13万有机分子的构成,空间信息及其对应的属性. 它被广泛应用于各类数据驱动的分子属性预测方法的实验和对比。
Toxicology in the 21st Century 简称tox21,任务是使用化学结构数据预测化合物对生物化学途径的干扰,研究、开发、评估和翻译创新的测试方法,以更好地预测物质如何影响人类和环境。数据集有12707张图,12个labels。
文件构成
PPI数据集的构成:
- train/test/valid_graph.json:保存了训练、验证、测试的图结构数据。
- train/test/valid_feats.npy :保存结点的特征,以numpy.ndarry的形式存储,shape为
[n, v],n是结点的个数,v是特征的长度。 - train/test/valid_labels.npy:保存结点的label,也是以numpy.ndarry的形式存储,形为n*h,h为label的长度。
- train/test/valid/_graph_id.npy :表示这个结点属于哪张图,形式为numpy.ndarry,例如
[1, 1, 2, 1...20].。
NCI-1、NCI-109和MUTAG数据集的文件构成如下:
- (用DS代替数据集名称)n表示结点数,m表示边的个数,N表示图的个数
- DS_A.txt (m lines):图的邻接矩阵,每一行的结构为(row, col),即一条边。
- DS_graph_indicator.txt (n lines):表明结点属于哪一个图的文件。
- DS_graph_labels.txt (N lines):图的labels。
- DS_node_labels.txt (n lines):结点的labels。
- DS_edge_labels.txt (m lines):边labels。
- DS_edge_attributes.txt (m lines):边特征。
- DS_node_attributes.txt (n lines):结点的特征。
- DS_graph_attributes.txt (N lines):图的特征,可以理解为全局变量。
QM9的文件结构如下:
- QM9_nano.npz:该文件需要用numpy读取,其中包含三个字段:’ID’ 分子的id,如:
qm9:000001;’Atom’ 分子的原子构成,为一个由原子序数的列表构成,如[6,1,1,1,1]表示该分子由一个碳(C)原子和4个氢(H)原子构成.;’Distance’ 分子中原子的距离矩阵,以上面[6,1,1,1,1]分子为例,它的距离矩阵即为一个5x5的矩阵,其中行列的顺序和上述列表一致,即矩阵的第N行/列对应的是列表的第N个原子信息. - ‘U0’ 分子的能量属性(温度为0K时),也是我们需要预测的值(分类的种类为13)
Tox21文件夹中包含13个文件,其中12个文件夹就是化合物的分类
Imagenet数据集
之前因为这个数据集的规模太大,所以一直没有详细了解。最近做Zero-Shot Learning的一些论文经常使用该数据集(emmm…),所以这里了解一下。该数据集的官方地址为
该数据集是由根据WordNet层次结构(目前只有名词)组织的图像数据库,其中层次结构的每个节点都有成百上千的图像。其总共有大约21K类,每一类节点对应一个wnid(WordNet ID of class),1500多万张图片,如下图展示了32326类的Imagetnet数据集组织形式。
常用的为ISLVRC 2012(ImageNet Large Scale Visual Recognition Challenge)比赛用的子数据集,其中:
- 训练集:1,281,167张图片+标签
- 验证集:50,000张图片+标签
- 测试集:100,000张图片
属于1000个不同的类别。
wordnet简介
传统词典一般都是按字母顺序组织词条信息的,这样的词典在解决用词和选义问题上是有价值的。然而,它们有一个共同的缺陷,就是忽略了词典中同义信息的组织问题。WordNet是由Princeton 大学的心理学家,语言学家和计算机工程师联合设计的一种基于认知语言学的英语词典。而每个不同的语义(sense)又可能对应多个词,如topic和subject在某些情况下是同义的,
WordNet与其他标准词典最显著的不同在于:它将词汇分成五个大类:名词、动词、形容词、副词和虚词。实际上,WordNet仅包含名词、动词、形容词和副词。虚词通常是作为语言句法成分的一部分,WordNet忽略了英语中较小的虚词集。
WordNet的语料库,在nltk_data文件夹下的corpora文件夹中,corprora文件夹是下载的,下载方式是使用两行代码。
1 | pip install nltk |
WordNet与一般字典的不同在于组织结构的不同,它是以同义词集合(Synset)作为基本的构建单位来组织的,用户可以在同义词集合中找到一个合适的词去表达一个已知的概念。而与传统词典类似的是它也给出了定义和例句。
基本使用,如果说WordNet是一个数据库,那么Synset就是一条数据的主键,而每一条数据,代表的是一个词义。Synset在文件中的格式,上一篇已经介绍了,这次介绍一下python中显示的Synset。
1 | from nltk.corpus import wordnet as wn |
由上图可见,Synset由三部分组成,第一部分是词义,第二部分是词性,第三部分是编号。’dog’所有词义中词性为名词(n)的词性有7个,词性为动词(v)的有1个。这个排列顺序是根据该词义出现的次数排列的。
1 | # 查看不同词义的定义 |
可以看到,同样的都是名词’dog’有着不同的定义。
1 | # 查看例句(可能有多句,放在同一个列表中) |
上面说过,wordnet中,Synset是一条数据的主键。这个主键和词性+8位offset对应。如下所示
1 | # 查询词性 |
在imagenet中,类别是词性+8位offset命名的,这被称为wnid,因此每一个类别均对应着一条Synset主键。所以知道了Synset主键之后,我们也可以得到其wnid(词性+8位offset):
1 | def getwnid(u): |
所谓hypernym,表示某一个概念的上位词,假如A的上位词是B,简单的理解即是B是一个大的概念,A是B概念的一种情况,A更加具体。
1 | # 例如,A概念表示狗,B概念表示家养动物,我们知道狗是家养动物的一种,则可以称家养动物是狗的一个上位词。 |
跟上位词对应,也有下位词概念,英文单词为hyponym,在下面的例子中,basenji、corgi等都是狗的不同品种,都是狗这个具体概念下的更加具体的概念
1 | wn.synset('dog.n.01').hyponyms() |
下载地址
Cora:https://s3.us-east-2.amazonaws.com/dgl.ai/dataset/cora_raw.zip
Pubmed:https://s3.us-east-2.amazonaws.com/dgl.ai/dataset/pubmed.zip
Citeseer:https://s3.us-east-2.amazonaws.com/dgl.ai/dataset/citeseer.zip
BlogCatalog:http://socialcomputing.asu.edu/datasets/BlogCatalog
Reddit:https://github.com/linanqiu/reddit-dataset
Epinions:http://www.trustlet.org/downloaded_epinions.html
PPI:http://snap.stanford.edu/graphsage/ppi.zip
NCI-1:https://ls11-www.cs.uni-dortmund.de/people/morris/graphkerneldatasets/NCI1.zip
NCI-109:https://ls11-www.cs.uni-dortmund.de/people/morris/graphkerneldatasets/NCI109.zip
MUTAG:https://ls11-www.cs.uni-dortmund.de/people/morris/graphkerneldatasets/MUTAG.zip
QM9:https://github.com/geekinglcq/QM9nano4USTC
Tox21:https://tripod.nih.gov/tox21/challenge/data.jsp
数据集合:https://linqs.soe.ucsc.edu/data
参考
Cora数据集介绍+读取
数据集 | 图网络一般适用的数据集整理
【数据集介绍】ImageNet介绍
ImageNet-DataSet
WordNet 简介
WordNet
【Python&NLP】关于WordNet,我的一些用法和思路(一)
【Python&NLP】关于WordNet,我的一些用法和思路(二)
WordNet相关概念探索梳理

