最近稍微学习了一下TensorRT,这里参考这很多博客,主要参考了如何使用TensorRT对训练好的PyTorch模型进行加速?。然后加上自己的一些注释。
现在训练深度学习模型主流的框架有TensorFlow,Pytorch,mxnet,caffe等。这个贴子只涉及Pytorch,对于TensorFlow的话,可以参考TensorRT部署深度学习模型,这个帖子是C++如何部署TensorRT。其实原理都是一样的,对于TensorFlow模型,需要把pb模型转化为uff模型;对于Pytorch模型,需要把pth模型转化为onnx模型;对于caffe模型,则不需要转化,因为tensorRT是可以直接读取caffe模型的;mxnet模型也是需要转化为onnx的。
对于TensorRT的安装,这里就不赘述了,之前我的博客有介绍过。
Python环境下Pytorch模型转化为TensorRT
Python环境下Pytorch模型转化为TensorRT有两种路径,一种是先把Pytorch的pt模型转化为onnx,然后再转化为TensorRT;另一种是直接把pytorch的pt模型转成TensorRT。
Pytorch->Onnx->TensorRT
首先,先把pt模型转化为onnx模型,需要安装onnx,直接pip install onnx即可。以ResNet50为例,代码如下:
1 | import torchvision |
以上代码使用torchvision里面预训练的resnet50模型为基础,将resnet50的pt模型转化成res50.onnx,其中规定onnx的输入名是’input’,输出名是’output’,输入图像的大小是3通道224x224。其中batch size是1,其实这个batch size你可以取3、4、5等。运行这个代码就可以生成一个名为resnet50.onnx文件。
比较Pytorch和TensorRT的结果:
1 | import pycuda.autoinit |
运行结果如下:
1 | TensorRT ok |
这里测得时间有点不准,第一次运行的时间是比较长的,但是我暂时没有GPU实验,所以先不讨论这个结果了。
代码来源于PyTorch_ONNX_TensorRT。
Pytorch->TensorRT
接下来介绍Python环境下,直接把Pytorch模型转化为TensorRT,参考的代码来源于NVIDIA-AI-IOT/torch2trt这个工程比较简单易懂,质量很高,安装也不难,原文作者(即下面的第一个参考链接)运行的结果如下:
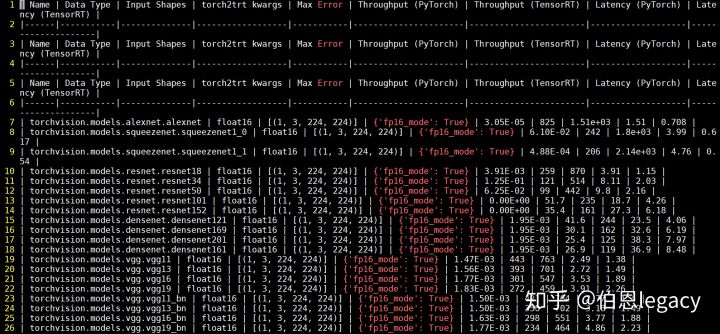
对于你自己的Pytorch模型,只需要把代码的model进行替换即可。注意在运行过程中经常会出现”output tensor has no attribute _trt”,这是因为你模型当中有一些操作还没有实现,需要自己实现。
C++环境下Pytorch模型转化为TensorRT
C++环境下Pytorch模型转化为TensorRT有两种路径,一种是先把Pytorch的pth模型转化为onnx,然后使用TensorRT进行解析从而构造TensorRT引擎,这里和Python环境下的第一种方法大同小异;另一种是先把Pytorch的pth模型转化为onnx模型,然后使用onnx-tensorrt转换为TensorRT的trt文件,然后在C++环境下的使用TensorRT直接加载trt文件,从而构建engine。
Pytorch->Onnx->TensorRT解析
c++环境下,以TensorRT5.1.5.0的sampleOnnxMNIST为例子,用opencv读取一张图片,然后让TensorRT进行doInference输出(1,1000)的特征。代码如下所示
1 |
|
其中,image.cpp的代码为:
1 |
|
image.hpp的内容为:
1 |
|
运行结果为:
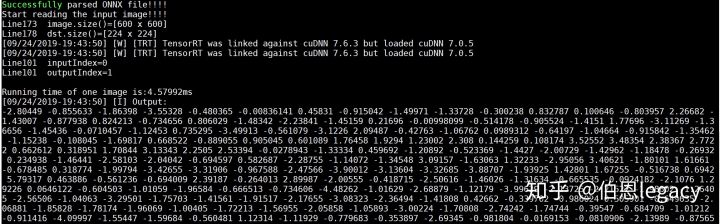
同样的test.jpg在python环境下的运行结果为:

可以发现,c++环境下resnet50输出的(1,1000)的特征与Python环境下feat1(TensorRT)和feat2(pytorch)的结果差距很小。
总结:
onnxToTRTModel的过程为:创建一个builder和network,使用parser解析Onnx模型填充network;使用builder类的方法设置batch size、workspace、推理方法(fp32、fp16、int8)。使用builder->buildCudaEngine(*network)执行优化方法创建engine。因为一个模型从导入到生成Engine是需要花费一些时间的,所以可以将engine序列化到内存或者存储文件中,便于使用(需要注意的是,若将序列化文件存储到了文件中,该文件和GPU平台高度相关,换一个平台需要重新生成该文件)。最后是销毁一些中间变量parser、engine、network、builder。mian函数主要过程为:执行onnxToTRTModel函数得到序列化engine——内存中的trtModelStream。创建运行时环境 IRuntime对象runtime,然后使用该对象反序列化trtModelStream得到engine;使用engine创建上下文环境context,主要用于inference 函数中启动cuda核。执行doInference函数过程。然后销毁context、engine、runtime。doInference函数的主要过程为:从上下文环境context恢复engine。为输入输出tensor开辟显存,到void* buffers中。创建cuda流,用于管理数据复制,存取,和计算的并发操作。从内存到显存,从CPU到GPU,将输入数据拷贝到显存中。启动cuda核,异步执行推理计算。从显存到内存,将计算结果拷贝回内存中。同步不同的cuda流。销毁流对象stream和释放显存buffers。
Pytorch->Onnx->TensorRT模型
上面的是将pytorch首先转化为onnx,然后让TensorRT解析onnx从而构建TensorRT引擎。那么我们如何让TensorRT直接加载引擎文件呢,也就是说,我们先把onnx转化为TensorRT的trt文件,然后让c++环境下的TensorRT直接加载trt文件,从而构建engine。
在这里我们首先使用onnx-tensorrt这个项目来使resnet50.onnx转化为resnet50.trt。采用的项目是onnx-tensorrt这个项目的安装也不难,这个也在我之前的博客里面有介绍,所以不展开了。
运行如下命令,就可以获得rensnet50.trt这个引擎文件
1 | onnx2trt resnet50.onnx -o resnet50.trt |
需要注意的是,onnx-tensort这个项目在编译的时有一个指定GPU计算能力的选项,如下图所示:
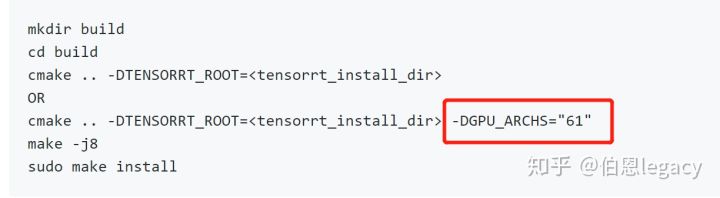
另外在onnx2trt命令有个-b操作,是指定生成的trt文件的batch size的。在实际test过程中,你的batch size是多少,这个就设置成多少。按照下面参考链接1作者的说法:
记得我当时trt文件的batch size是1,但是我实际的batch size是8,运行后,只有一张图片有结果,其他7张图片都是0。
还有,导出onnx模型时,网络的数据输入要和TensorRt数据输入大小保持一致(b,c,w,h)。对于retinaface,若不这样做,否则可能因为特征图大小不一样,导致预测的anchor偏置数量与预设anchor数量不一致。在进行后处理时导致访问非法内存。
如果能顺利生成trt文件的话,在代码中可以直接添加以下函数,来生成engine, 其他就不需要改变。
1 | bool read_TRT_File(const std::string& engineFile, IHostMemory*& trtModelStream) |
如果想保存引擎文件的话,可以在自己的代码中添加这几句话,就可以生成trt文件,然后下次直接调用trt文件。
1 | nvinfer1::IHostMemory* data = engine->serialize(); |
总结
按照目前我的观察,这里只说C++接口,按照第一种方法可以在导出Onnx模型后,使用C++代码控制使用fp32、fp16或者int8进行推理,但是若按照第二种方法,无法使用C++代码控制使用fp32、fp16或者int8进行推理,虽然onnx2trt有一个-d参数指明是float32还是float16,但即便是这样,按照How to use FP16 ot INT8? #32,好像也有很多坑待填。
参考
如何使用TensorRT对训练好的PyTorch模型进行加速?
TensorRT(1)-介绍-使用-安装
TensorRT(2)-基本使用:mnist手写体识别
caffe模型TensorRT部署实践(一)
The TensorRT support multi-gpus inference? #322

