本篇文章主要参考了TensorRT(1)-介绍-使用-安装,并加上了一些自己的理解。
简介
TensorRT是一个高性能的深度学习推理(Inference)优化器,可以为深度学习应用提供低延迟、高吞吐率的部署推理。TensorRT 之前称为GIE。
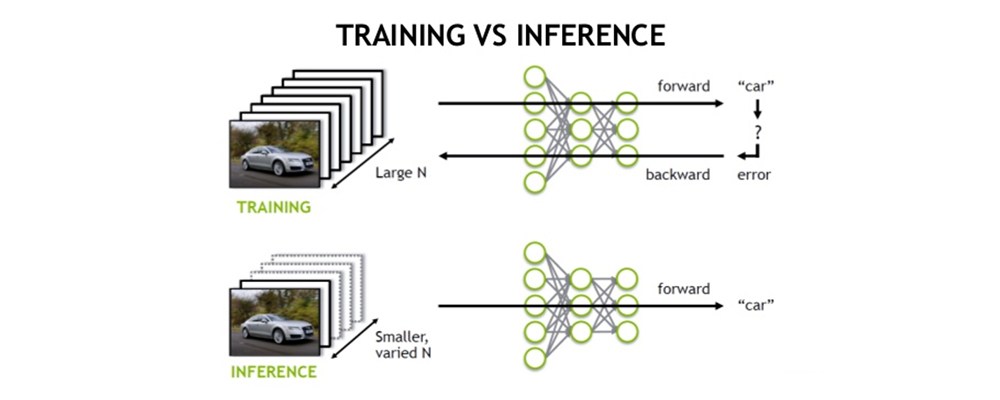
由上图可以很清楚的看出,训练(training)和 推理(inference)的区别:
- 训练(training)包含了前向传播和后向传播两个阶段,针对的是训练集。训练时通过误差反向传播来不断修改网络权值(weights)。
- 推理(inference)只包含前向传播一个阶段,针对的是除了训练集之外的新数据。可以是测试集,但不完全是,更多的是整个数据集之外的数据。其实就是针对新数据进行预测,预测时,速度是一个很重要的因素。
为了提高部署推理的速度,出现了很多轻量级神经网络,比如squeezenet,mobilenet,shufflenet等。基本做法都是基于现有的经典模型提出一种新的模型结构,然后用这些改造过的模型重新训练,再重新部署。
而tensorRT则是对训练好的模型进行优化,tensorRT只是推理优化器。当你的网络训练完之后,可以将训练模型文件直接丢进tensorRT中,而不再需要依赖深度学习框架(Caffe,TensorFlow等),如下:
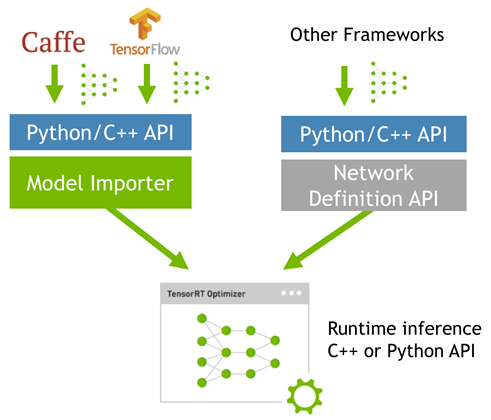
可以认为tensorRT是一个只有前向传播的深度学习框架,这个框架可以将 Caffe,TensorFlow等网络模型解析,然后与tensorRT中对应的层进行一一映射,把其他框架的模型统一全部转换到tensorRT中,然后在tensorRT中可以针对NVIDIA自家GPU实施优化策略,并进行部署加速。
TensorRT4.0几乎可以支持所有常用的深度学习框架,对于caffe和tensorflow来说,tensorRT可以直接解析他们的网络模型;对于caffe2,pytorch,mxnet,chainer,CNTK等框架则是首先要将模型转为 ONNX 的通用深度学习模型,然后对ONNX模型做解析。而tensorflow和MATLAB已经将TensorRT集成到框架中去了。
基本上比较经典的层比如,卷积,反卷积,全连接,RNN,softmax等,在tensorRT中都是有对应的实现方式的,tensorRT是可以直接解析的。
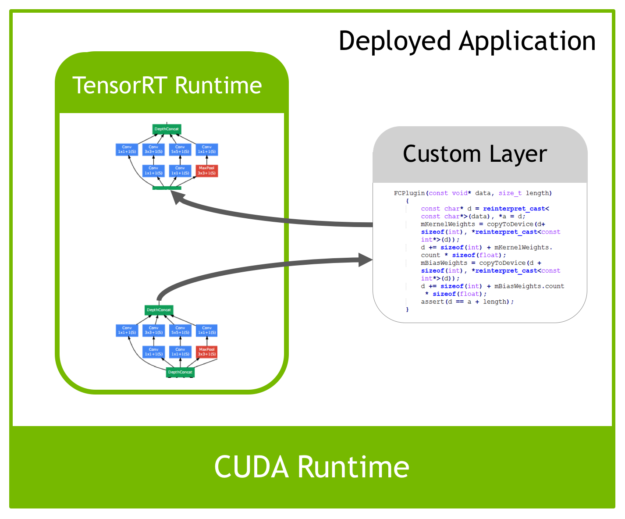
对于自定义层,tensorRT中有一个 Plugin 层,这个层提供了 API 可以由用户自己定义tensorRT不支持的层。 如下图:
优化方式
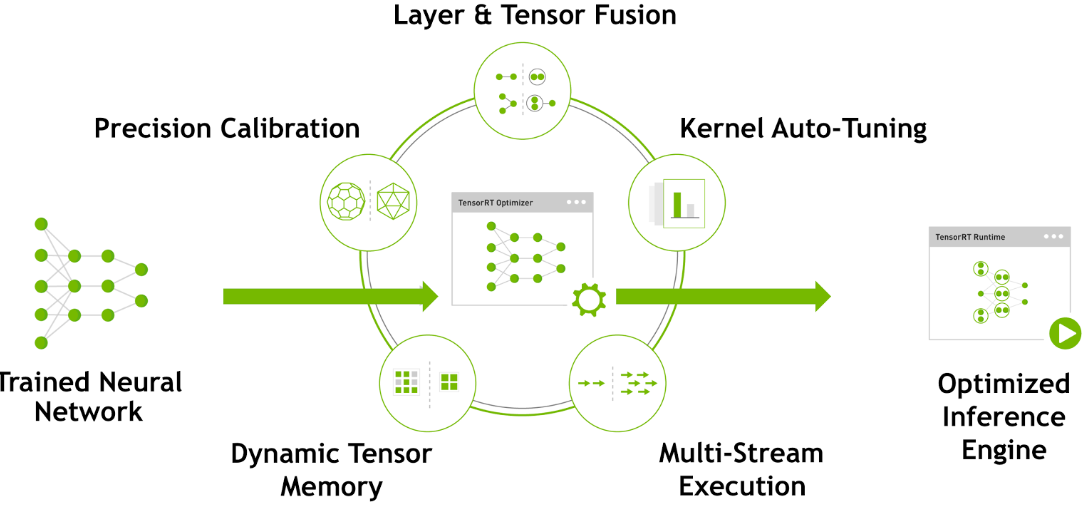
TensorRT优化方法主要有以下几种方式,最主要的是前面两种。
层间融合或张量融合(Layer & Tensor Fusion)
如下图左侧是GoogLeNet Inception模块的计算图。这个结构中有很多层,在部署模型推理时,这每一层的运算操作都是由GPU完成的,但实际上是GPU通过启动不同的CUDA(Compute unified device architecture)核心来完成计算的,CUDA核心计算张量的速度是很快的,但是往往大量的时间是浪费在CUDA核心的启动和对每一层输入/输出张量的读写操作上面,这造成了内存带宽的瓶颈和GPU资源的浪费。TensorRT通过对层间的横向或纵向合并(合并后的结构称为CBR,意指 convolution, bias, and ReLU layers are fused to form a single layer),使得层的数量大大减少。
- 横向合并可以把卷积、偏置和激活层合并成一个CBR结构,只占用一个CUDA核心。而在绝大部分框架中,比如卷积、偏置和激活层这三层是需要调用三次cuDNN对应的API
- 纵向合并可以把结构相同,但是权值不同的层合并成一个更宽的层,也只占用一个CUDA核心。
合并之后的计算图(下图右侧)的层次更少了,占用的CUDA核心数也少了,因此整个模型结构会更小,更快,更高效。对于concat这一层,比如说这边计算出来一个1×3×24×24,另一边计算出来1×5×24×24,concat到一起,变成一个1×8×24×24的矩阵,这个叫concat这层这其实是完全没有必要的,因为TensorRT完全可以实现直接接到需要的地方,不用专门做concat的操作,所以这一层也可以取消掉。
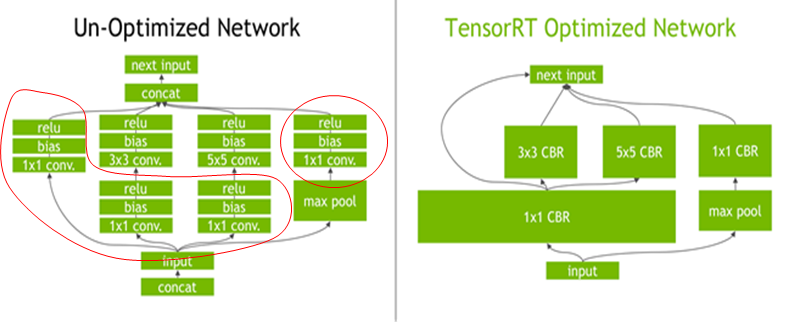
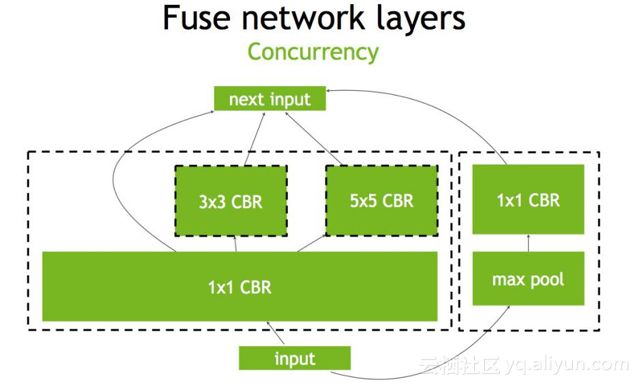
另外还可以做并发(Concurrency),如下图左半部分(max pool和1×1 CBR)与右半部分(大的1×1 CBR,3×3 CBR和5×5 CBR)彼此之间是相互独立的两条路径,本质上是不相关的,可以在GPU上通过并发来做,来达到的优化的目标。
数据精度校准(Weight &Activation Precision Calibration)
大部分深度学习框架在训练神经网络时网络中的张量(Tensor)都是32位浮点数的精度(Full 32-bit precision,FP32),一旦网络训练完成,在部署推理的过程中由于不需要反向传播,完全可以适当降低数据精度,比如降为FP16或INT8的精度。更低的数据精度将会使得内存占用和延迟更低,模型体积更小。
如下表为不同精度的动态范围:
| Precision | Dynamic Range |
|---|---|
| FP32 | −3.4×1038 +3.4×1038−3.4×1038 +3.4×1038 |
| FP16 | −65504 +65504−65504 +65504 |
| INT8 | −128 +127 |
INT8只有256个不同的数值,使用INT8来表示 FP32精度的数值,肯定会丢失信息,造成性能下降。不过TensorRT会提供完全自动化的校准(Calibration )过程,会以最好的匹配性能将FP32精度的数据降低为INT8精度,最小化性能损失。关于校准过程,后面会专门做一个探究。可以见TensorRT(5)-INT8校准原理
Kernel Auto-Tuning
网络模型在推理计算时,是调用GPU的CUDA核进行计算的。TensorRT可以针对不同的算法,不同的网络模型,不同的GPU平台,进行 CUDA核的调整(怎么调整的还不清楚),以保证当前模型在特定平台上以最优性能计算。
TensorRT will pick the implementation from a library of kernels that delivers the best performance for the target GPU, input data size, filter size, tensor layout, batch size and other parameters.
Dynamic Tensor Memory
在每个tensor的使用期间,TensorRT会为其指定显存,避免显存重复申请,减少内存占用和提高重复使用效率。
Multi-Stream Execution
Scalable design to process multiple input streams in parallel,这个应该就是GPU底层的优化了。
名词解释
TensorRT中有三个Parser用于模型的导入:
- Caffe Parser: 支持Caffe框架模型的导入
- UFF Parser:通用框架格式(UFF)是描述DNN的执行图的数据格式
- ONNX Parser:通用模型交换格式(ONNX)是一种开放式的文件格式,用于存储训练好的模型
需要清楚的是,各种框架间模型的转换,需要的仅仅是模型的定义及权值。通过将模型保存为以上三个Parser可以解析的格式,则基本上就可以将模型导入到TensorRT中。
事实上,一个模型从导入到执行,会经过下面三个阶段:
- Network Definition: 这一阶段在TensorRT中定义网络模型,可以使用TensorRT提供的Parser导入已有模型进行定义,也可以使用TensorRT中提供的网络层来编程定义(这一步应该也需要准备好相关的权值)
- Builder:前面提到过,TensorRT会对模型进行优化,这一步就是配置各项优化参数,并能生成可执行Inference的Engine
- Engine:Engine可理解为一个Builder的实例,是我们导入的模型经过Builder的配置所生成的一个优化过的Inference执行器,所有的Inference可直接调用Engine来执行
一个模型从导入到生成Engine是需要花费一些时间的,因此TensorRT提供了Engine的序列化和反序列化操作,一旦我们确定了一个Engine,可以对其进行序列化操作,下次执行Inference时直接反序列化该Engine即可。
其余琐碎的东西:
- TensorRT提供了C++接口和Python接口,官方建议使用C++接口
- 一个Engine的建立是根据特定GPU和CUDA版本来的,所以在一个机器上序列化的Engine到另一个机器上不一定能使用,因此在使用Builder生成Engine前,要注意自己的环境配置
- TensorRT可结合DALI(加速数据读取)和DLA(加速某些层的运算)一起使用
- 对于TensorRT中不支持的层,需要自己编写相应的文件,TensorRT提供了相关支持
TensorRT使用流程
在使用tensorRT的过程中需要提供以下文件(以caffe为例):
- A network architecture file (deploy.prototxt), 模型文件
- Trained weights (net.caffemodel), 权值文件
- A label file to provide a name for each output class. 标签文件
前两个是为了解析模型时使用,最后一个是推理输出时将数字映射为有意义的文字标签。
tensorRT的使用包括两个阶段, build and deployment:
build
build:Import and optimize trained models to generate inference engines。build阶段主要完成模型转换(从caffe或TensorFlow到TensorRT),在模型转换时会完成前述优化过程中的层间融合,精度校准。这一步的输出是一个针对特定GPU平台和网络模型的优化过的TensorRT模型,这个TensorRT模型可以序列化存储到磁盘或内存中。存储到磁盘中的文件称之为 plan file。
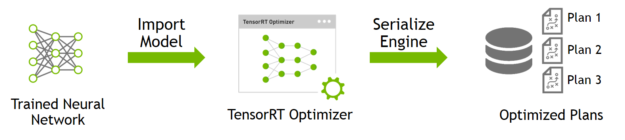
下面代码是一个简单的build过程:
1 | //创建一个builder |
上面的过程使用了一个高级别的API:CaffeParser,直接读取 caffe的模型文件,就可以解析,也就是填充network对象。解析的过程也可以直接使用一些低级别的C++API,比如:
1 | ITensor* in = network->addInput(“input”, DataType::kFloat, Dims3{…}); |
解析caffe模型之后,必须要指定输出tensor,设置batch size,和设置工作空间。
- 设置batch size就跟使用caffe测试是一样的。关于
builder->setMaxBatchSize(1);官方解释为:The maximum batch size specifies the batch size for which TensorRT will optimize. At runtime, a smaller batch size may be chosen. - 设置工作空间是进行前述层间融合和张量融合的必要措施。层间融合和张量融合的过程是在调用
builder->buildCudaEngine时才进行的。关于builder->setMaxWorkspaceSize(1 << 30);官方解释为:Layer algorithms often require temporary workspace. This parameter limits the maximum size that any layer in the network can use. If an insufficient scratch is provided, it is possible that TensorRT may not be able to find an implementation for a given layer.
另外,官方文档问题:Q: How do I choose the optimal workspace size?
A: Some TensorRT algorithms require additional workspace on the GPU. The method IBuilderConfig::setMaxWorkspaceSize() controls the maximum amount of workspace that may be allocated, and will prevent algorithms that require more workspace from being considered by the builder. At runtime, the space is allocated automatically when creating an IExecutionContext. The amount allocated will be no more than is required, even if the amount set in IBuilderConfig::setMaxWorkspaceSize() is much higher. Applications should therefore allow the TensorRT builder as much workspace as they can afford; at runtime TensorRT will allocate no more than this, and typically less.
deploy
deploy:Generate runtime inference engine for inference。deploy阶段主要完成推理过程,Kernel Auto-Tuning 和 Dynamic Tensor Memory 应该是在这里完成的。将上面一个步骤中的plan文件首先反序列化,并创建一个 runtime engine,然后就可以输入数据(比如测试集或数据集之外的图片),然后输出分类向量结果或检测结果。

以下是一个简单的deploy代码:这里面没有包含反序列化过程和测试时的batch流获取
1 | // The execution context is responsible for launching the |
在执行的时候创建context,主要是分配预先的资源,engine加context就可以做推断(Inference)。
参考
TensorRT(1)-介绍-使用-安装
《一》TensorRT之基本概念
TensorRT 实战教程
tensorrt/developer-guide
TensorRT - Custom Layer
高性能深度学习支持引擎实战——TensorRT
深度学习算法优化系列二十二 | 利用TensorRT部署YOLOV3-Tiny INT8量化模型

