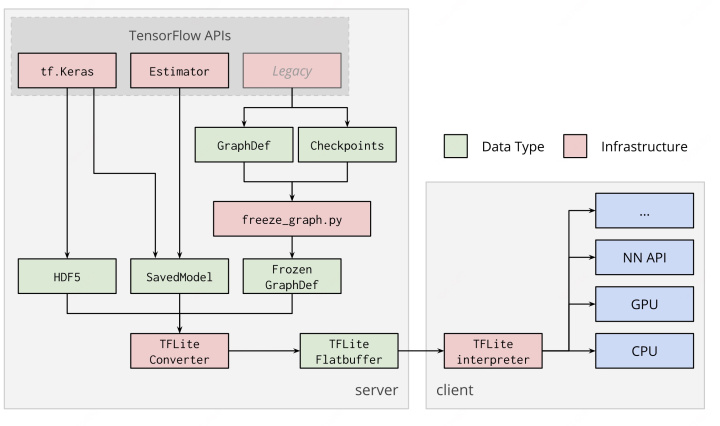
with tf.gfile.GFile(graph_pb, "rb") as f: graph_def = tf.GraphDef() graph_def.ParseFromString(f.read())
sigs = {}
with tf.Session(graph=tf.Graph()) as sess: # name="" is important to ensure we don't get spurious prefixing tf.import_graph_def(graph_def, name="") g = tf.get_default_graph() input_ids = sess.graph.get_tensor_by_name( "input_ids:0") input_mask = sess.graph.get_tensor_by_name( "input_mask:0") segment_ids = sess.graph.get_tensor_by_name( "segment_ids:0") probabilities = g.get_tensor_by_name("loss/pred_prob:0")
$ saved_model_cli show --dir export/1524906774 \ --tag_set serve --signature_def serving_default The given SavedModel SignatureDef contains the following input(s): inputs['inputs'] tensor_info: dtype: DT_STRING shape: (-1) The given SavedModel SignatureDef contains the following output(s): outputs['classes'] tensor_info: dtype: DT_STRING shape: (-1, 3) outputs['scores'] tensor_info: dtype: DT_FLOAT shape: (-1, 3) Method name is: tensorflow/serving/classify
$ saved_model_cli run --dir export/1524906774 \ --tag_set serve --signature_def serving_default \ --input_examples 'inputs=[{"SepalLength":[5.1],"SepalWidth":[3.3],"PetalLength":[1.7],"PetalWidth":[0.5]}]' Result for output key classes: [[b'0' b'1' b'2']] Result for output key scores: [[9.9919027e-01 8.0969761e-04 1.2872645e-09]]
deffreeze_session(session, keep_var_names=None, output_names=None, clear_devices=True): """ Freezes the state of a session into a pruned computation graph. Creates a new computation graph where variable nodes are replaced by constants taking their current value in the session. The new graph will be pruned so subgraphs that are not necessary to compute the requested outputs are removed. @param session The TensorFlow session to be frozen. @param keep_var_names A list of variable names that should not be frozen, or None to freeze all the variables in the graph. @param output_names Names of the relevant graph outputs. @param clear_devices Remove the device directives from the graph for better portability. @return The frozen graph definition. """ graph = session.graph with graph.as_default(): freeze_var_names = list(set(v.op.name for v in tf.global_variables()).difference(keep_var_names or [])) output_names = output_names or [] output_names += [v.op.name for v in tf.global_variables()] input_graph_def = graph.as_graph_def() if clear_devices: for node in input_graph_def.node: node.device = "" frozen_graph = tf.graph_util.convert_variables_to_constants( session, input_graph_def, output_names, freeze_var_names) return frozen_graph frozen_graph = freeze_session(K.get_session(), output_names=[out.op.name for out in model.outputs])
""" To save custom objects to HDF5, you must do the following: 1. Define a get_config method in your object, and optionally a from_config classmethod. get_config(self) returns a JSON-serializable dictionary of parameters needed to recreate the object. from_config(cls, config) uses the returned config from get_config to create a new object. By default, this function will use the config as initialization kwargs (return cls(**config)). 2. Pass the object to the custom_objects argument when loading the model. The argument must be a dictionary mapping the string class name to the Python class. E.g. tf.keras.models.load_model(path, custom_objects={'CustomLayer': CustomLayer}) """
""" --saved_model_dir: Type: string. Specifies the full path to the directory containing the SavedModel generated in 1.X or 2.X. --output_file: Type: string. Specifies the full path of the output file. """ tflite_convert \ --saved_model_dir=1583934987 \ --output_file=rbt.tflite
#--keras_model_file. Type: string. Specifies the full path of the HDF5 file containing the tf.keras model generated in 1.X or 2.X. #--output_file: Type: string. Specifies the full path of the output file. tflite_convert \ --keras_model_file=h5_dir/ \ --output_file=rbt.tflite
@tf.function(input_signature=[tf.TensorSpec(shape=[1, 10], dtype=tf.float32)]) defadd(self, x): ''' Simple method that accepts single input 'x' and returns 'x' + 4. ''' # Name the output 'result' for convenience. return {'result' : x + 4}
# Save the model module = TestModel() # You can omit the signatures argument and a default signature name will be # created with name 'serving_default'. tf.saved_model.save( module, SAVED_MODEL_PATH, signatures={'my_signature':module.add.get_concrete_function()})
# Convert the model using TFLiteConverter converter = tf.lite.TFLiteConverter.from_saved_model(SAVED_MODEL_PATH) tflite_model = converter.convert() with open(TFLITE_FILE_PATH, 'wb') as f: f.write(tflite_model)
# Load the TFLite model in TFLite Interpreter interpreter = tf.lite.Interpreter(TFLITE_FILE_PATH) # There is only 1 signature defined in the model, # so it will return it by default. # If there are multiple signatures then we can pass the name. my_signature = interpreter.get_signature_runner()
# my_signature is callable with input as arguments. output = my_signature(x=tf.constant([1.0], shape=(1,10), dtype=tf.float32)) # 'output' is dictionary with all outputs from the inference. # In this case we have single output 'result'. print(output['result'])
# Load the TFLite model and allocate tensors. interpreter = tf.lite.Interpreter(model_path="converted_model.tflite") interpreter.allocate_tensors()
# Get input and output tensors. input_details = interpreter.get_input_details() output_details = interpreter.get_output_details()
# Test the model on random input data. input_shape = input_details[0]['shape'] input_data = np.array(np.random.random_sample(input_shape), dtype=np.float32) interpreter.set_tensor(input_details[0]['index'], input_data)
interpreter.invoke()
# The function `get_tensor()` returns a copy of the tensor data. # Use `tensor()` in order to get a pointer to the tensor. output_data = interpreter.get_tensor(output_details[0]['index']) print(output_data)