图片解码
RGB图像存储的时候并不是记录的三维矩阵,而是经过压缩编码的结果,所以要将一副图像还原为一个三维矩阵,需要解码过程。
例如,读取png图像代码:
1 | # 读取原始的图像 |
文件格式
TFRecord格式
Protocol Buffers
为了更好的理解TFRecord格式,我们首先对Protocol Buffers进行介绍。
Protocol Buffers(也称protobuf)是Google公司出口的一种独立于开发语言,独立于平台的可扩展的结构化数据序列机制。通俗点来讲它跟xml和json是一类。是一种数据交互格式协议。
网上有很多它的介绍,主要优点是它是基于二进制的,所以比起结构化的xml协议来说,它的体积很少,数据在传输过程中会更快。C语言编写的,另外它也支持c++、java、python、php、javascript等主流开发语言。
定义第一个Protocol Buffer消息:
创建扩展名为.proto的文件,如:MyMessage.proto,并将以下内容存入该文件中。
1 | message LogonReqMessage { |
这里将给出以上消息定义的关键性说明。
- message是消息定义的关键字,等同于C++中的struct/class,或是Java中的class。
- LogonReqMessage为消息的名字,等同于结构体名或类名。
- required前缀表示该字段为必要字段,既在序列化和反序列化之前该字段必须已经被赋值。与此同时,在Protocol Buffer中还存在另外两个类似的关键字,optional和repeated,带有这两种限定符的消息字段则没有required字段这样的限制。相比于optional,repeated主要用于表示数组字段。具体的使用方式在后面的用例中均会一一列出。
- int64和string分别表示长整型和字符串型的消息字段,在Protocol Buffer中存在一张类型对照表,既Protocol Buffer中的数据类型与其他编程语言(C++/Java)中所用类型的对照。该对照表中还将给出在不同的数据场景下,哪种类型更为高效。该对照表将在后面给出。
- acctID和passwd分别表示消息字段名,等同于Java中的域变量名,或是C++中的成员变量名。
- 标签数字1和2则表示不同的字段在序列化后的二进制数据中的布局位置。在该例中,passwd字段编码后的数据一定位于acctID之后。需要注意的是该值在同一message中不能重复。另外,对于Protocol Buffer而言,标签值为1到15的字段在编码时可以得到优化,既标签值和类型信息仅占有一个byte,标签范围是16到2047的将占有两个bytes,而Protocol Buffer可以支持的字段数量则为2的29次方减一。有鉴于此,我们在设计消息结构时,可以尽可能考虑让repeated类型的字段标签位于1到15之间,这样便可以有效的节省编码后的字节数量。另外 19000 到 19999 也不能用。他们是protobuf 的编译预留标签。
定义第二个(含有枚举字段)Protocol Buffer消息:
1 | //在定义Protocol Buffer的消息时,可以使用和C++/Java代码同样的方式添加注释。 |
这里将给出以上消息定义的关键性说明(仅包括上一小节中没有描述的)。
- enum是枚举类型定义的关键字,等同于C++/Java中的enum。
- UserStatus为枚举的名字。
- 和C++/Java中的枚举不同的是,枚举值之间的分隔符是分号,而不是逗号。
- OFFLINE/ONLINE为枚举值。
- 0和1表示枚举值所对应的实际整型值,和C/C++一样,可以为枚举值指定任意整型值,而无需总是从0开始定义。如:
1
2
3
4
5
6
7
8
9enum OperationCode {
LOGON_REQ_CODE = 101;
LOGOUT_REQ_CODE = 102;
RETRIEVE_BUDDIES_REQ_CODE = 103;
LOGON_RESP_CODE = 1001;
LOGOUT_RESP_CODE = 1002;
RETRIEVE_BUDDIES_RESP_CODE = 1003;
}
定义第三个(含有嵌套消息字段)Protocol Buffer消息:
我们可以在同一个.proto文件中定义多个message,这样便可以很容易的实现嵌套消息的定义。如:
1 | enum UserStatus { |
这里将给出以上消息定义的关键性说明(仅包括上两小节中没有描述的)。
- LogonRespMessage消息的定义中包含另外一个消息类型作为其字段,如UserInfo userInfo。
- 上例中的UserInfo和LogonRespMessage被定义在同一个.proto文件中,那么我们是否可以包含在其他.proto文件中定义的message呢?Protocol Buffer提供了另外一个关键字import,这样我们便可以将很多通用的message定义在同一个.proto文件中,而其他消息定义文件可以通过import的方式将该文件中定义的消息包含进来,如:
1
import "myproject/CommonMessages.proto"
限定符(required/optional/repeated)的基本规则。
- 在每个消息中必须至少留有一个required类型的字段。
- 每个消息中可以包含0个或多个optional类型的字段。
- repeated表示的字段可以包含0个或多个数据。需要说明的是,这一点有别于C++/Java中的数组,因为后两者中的数组必须包含至少一个元素。
- 如果打算在原有消息协议中添加新的字段,同时还要保证老版本的程序能够正常读取或写入,那么对于新添加的字段必须是optional或repeated。道理非常简单,老版本程序无法读取或写入新增的required限定符的字段。
TFRecord简介
TFRecord 是谷歌推荐的一种二进制文件格式,理论上它可以保存任何格式的信息。它特别适应于 Tensorflow ,或者说它就是为 Tensorflow 量身打造的。
1 | uint64 length |
上面是 Tensorflow 的官网给出的文档结构。整个文件由文件长度信息、长度校验码、数据、数据校验码组成。
但对于我们普通开发者而言,我们并不需要关心这些,Tensorflow 提供了丰富的 API 可以帮助我们轻松读写 TFRecord 文件。
TFRecord 的核心内容在于内部有一系列的 Example ,Example 是 protocolbuf 协议下的消息体(一种特定的消息体)。主要在tf.train.Example中给出定义
在这里我相信大家都对 protocolbuf 比较了解,如果不了解也没有关系,它本质上和 xml 及 json 没有多大的区别。
网上有很多 example 的简单说明。
1 | message Example { |
熟悉 protobuf 同学看到这个格式定义就能马上明白了。
一个 Example 消息体包含了一系列的 feature 属性。
每一个 feature 是一个 map,也就是 key-value 的键值对。
key 取值是 String 类型。
而 value 是 Feature 类型的消息体,它的取值有 3 种:
- BytesList
- FloatList
- Int64List
需要注意的是,他们都是列表的形式。
protocolbuf 是通用的协议格式,对主流的编程语言都适用。所以这些 List 对应到 python 语言当中是 列表,而对于 Java 或者 C/C++ 来说他们就是数组。
举个例子,一个 BytesList 可以存储 Byte 数组,因此像字符串、图片、视频等等都可以容纳进去。
所以 TFRecord 可以存储几乎任何格式的信息。
但需要说明的是,更官方的文档来源于 Tensorflow的源码,这里面有详细的定义及注释说明。
TFRecord创建
我们可以利用 TFWriter 轻松完成这个任务。
但制作之前,我们要先明确自己的目的。
我们必须想清楚,要把什么信息存储到 TFRecord 文件当中,这其实是最重要的。
下面,举例说明。
因为深度学习很多都是与图片集打交道,那么,我们可以尝试下把一张张的图片转换成 TFRecord 文件。
首先定义 Example 消息体。
1 | Example Message { |
上面的 Example 表示,要将一张 cat 图片信息写进 TFRecord 当中,而图片信息包含了图片的名字,图片的维度信息还有图片的数据,分别对应了 name、shape、content 3 个 feature。
实际使用Python调用API定义该消息体的,这里列出来是为了更好的理解下面代码。
下面,我们开始用代码实现它。
1 | def write_test(input,output): |
运行上面的代码,就可以在当前目录生成cat.tfrecord文件。
上面代码注释都比较详细,我挑重点来讲。
- 将图片解码,然后转化成 string 数据,然后填充进去。
- Feature 的 value 是列表,所以要记得加 []
- example 需要调用 SerializetoString() 进行序列化后才行。
TFRecord读取
上一节是讲如何将一张图片的信息写入到一个 tfrecord 文件当中。
现在,我们需要检验它是否正确,这就需要用到如何读取 TFRecord 文件的知识点了。
1 | def _parse_record(example_proto): |
代码比较简单,我也有给详细的注释,我挑重要的几点讲解一下。
- 我用 dataset 去读取 tfrecord 文件
- 在解析 example 的时候,用现成的 API 就好了 tf.parse_single_example
- 用 np.fromstring() 方法就可以获取解析后的 string 数据,记得数据格式还原成 np.uint8
- 用 tf.image.encode_jpeg() 方法可以将图片数据编码成 jpeg 格式。
- 用 tf.gfile.GFile 对象可以将图片数据保存到本地。
- 因为将图片 shape 写进了 example 中,解析的时候必须指定维度,在这里是
[3],不然程序报错。
CSV
CSV文件以纯文本形式存储表达数据(数字和文本),这意味这该文件是一个字符序列,读取该文件不需要经过想二进制数据那样的反序列华过程。
数据读取
在TensorFlow 1.3以前的版本中总体来说有两种读取数据方法:
- 使用placeholder和feed_dict读内存中的数据
- 使用queue pipeline(队列式管道)读取硬盘中的数据
Dataset API是从 TensorFlow 1.3开始添加新的输入管道。使用此 API 的性能要比使用 feed_dict 或队列式管道的性能高得多,而且此 API 更简洁,使用起来更容易。在TensorFlow 1.3中,Dataset API是放在contrib包中的:tf.contrib.data.Dataset,而在TensorFlow 1.4中则是tf.data.Dataset。
下面分别对这三种方式进行说明
queue pipeline
读取机制图解
首先需要思考的一个问题是,什么是数据读取?以图像数据为例,读取数据的过程可以用下图来表示:
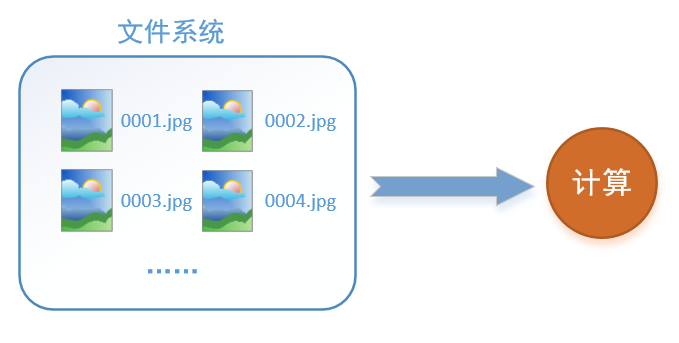
假设我们的硬盘中有一个图片数据集0001.jpg,0002.jpg,0003.jpg……我们只需要把它们读取到内存中,然后提供给GPU或是CPU进行计算就可以了。这听起来很容易,但事实远没有那么简单。事实上,我们必须要把数据先读入后才能进行计算,假设读入用时0.1s,计算用时0.9s,那么就意味着每过1s,GPU都会有0.1s无事可做,这就大大降低了运算的效率。
如何解决这个问题?方法就是将读入数据和计算分别放在两个线程中,将数据读入内存的一个队列,如下图所示:
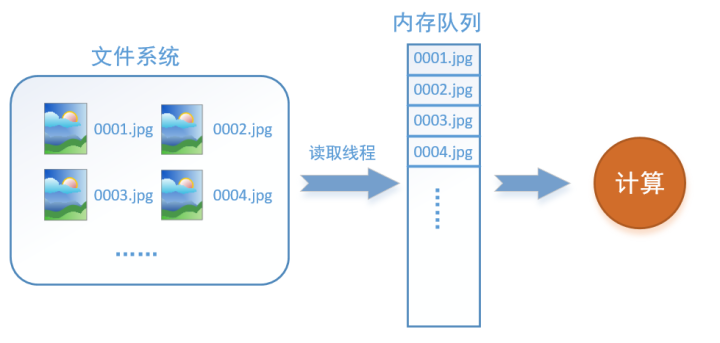
读取线程源源不断地将文件系统中的图片读入到一个内存的队列中,而负责计算的是另一个线程,计算需要数据时,直接从内存队列中取就可以了。这样就可以解决GPU因为IO而空闲的问题!
而在tensorflow中,为了方便管理,在内存队列前又添加了一层所谓的“文件名队列”。
为什么要添加这一层文件名队列?我们首先得了解机器学习中的一个概念:epoch。对于一个数据集来讲,运行一个epoch就是将这个数据集中的图片全部计算一遍。如一个数据集中有三张图片A.jpg、B.jpg、C.jpg,那么跑一个epoch就是指对A、B、C三张图片都计算了一遍。两个epoch就是指先对A、B、C各计算一遍,然后再全部计算一遍,也就是说每张图片都计算了两遍。
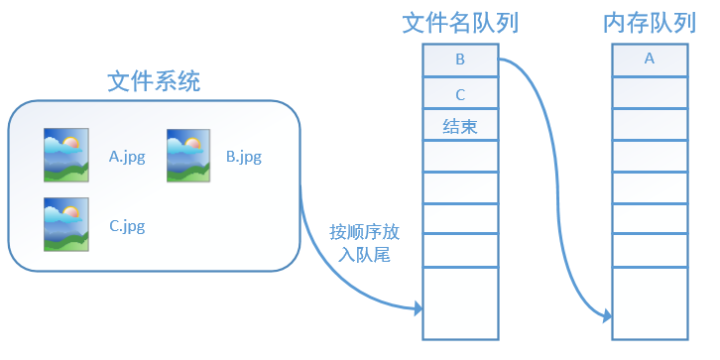
tensorflow使用文件名队列+内存队列双队列的形式读入文件,可以很好地管理epoch。下面我们用图片的形式来说明这个机制的运行方式。如下图,还是以数据集A.jpg, B.jpg, C.jpg为例,假定我们要跑一个epoch,那么我们就在文件名队列中把A、B、C各放入一次,并在之后标注队列结束。

程序运行后,内存队列首先读入A(此时A从文件名队列中出队):
再依次读入B和C:
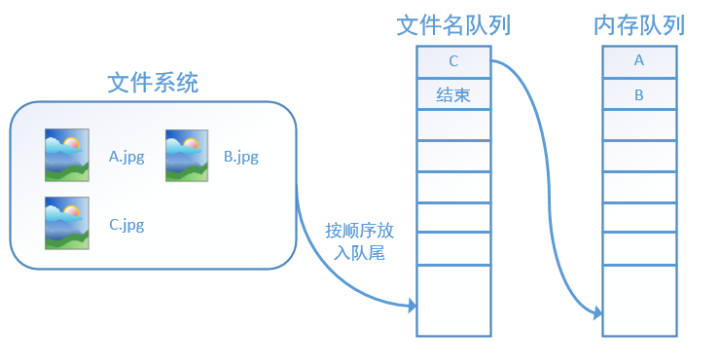
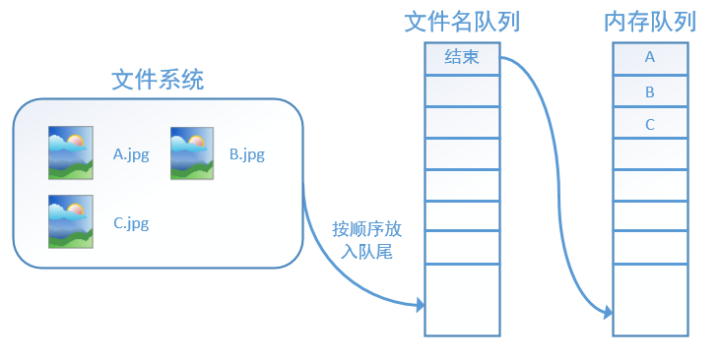
此时,如果再尝试读入,系统由于检测到了“结束”,就会自动抛出一个异常(OutOfRange)。外部捕捉到这个异常后就可以结束程序了。这就是tensorflow中读取数据的基本机制。如果我们要跑2个epoch而不是1个epoch,那只要在文件名队列中将A、B、C依次放入两次再标记结束就可以了。
tensorflow读取数据机制的对应函数
如何在tensorflow中创建上述的两个队列呢?
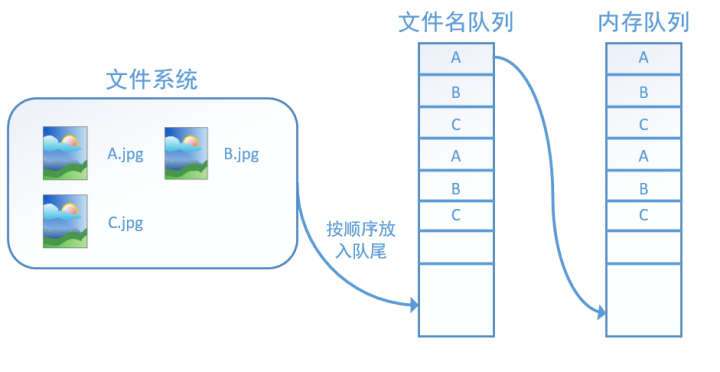
对于文件名队列,我们使用tf.train.string_input_producer函数。这个函数需要传入一个文件名list,系统会自动将它转为一个文件名队列。
此外tf.train.string_input_producer还有两个重要的参数,一个是num_epochs,它就是我们上文中提到的epoch数。另外一个就是shuffle,shuffle是指在一个epoch内文件的顺序是否被打乱。若设置shuffle=False,如下图,每个epoch内,数据还是按照A、B、C的顺序进入文件名队列,这个顺序不会改变:
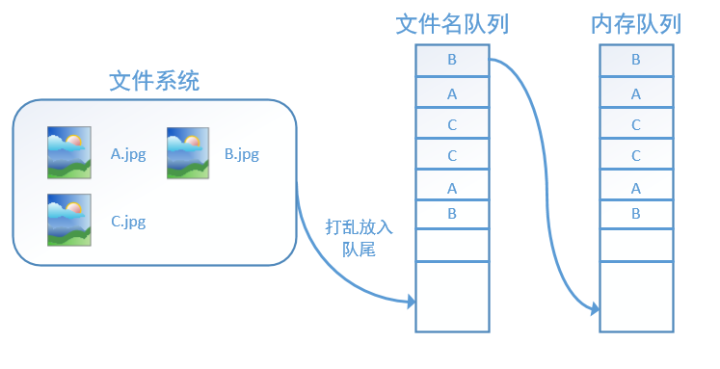
如果设置shuffle=True,那么在一个epoch内,数据的前后顺序就会被打乱,如下图所示:
在tensorflow中,内存队列不需要我们自己建立,我们只需要使用reader对象从文件名队列中读取数据就可以了,具体实现可以参考下面的实战代码。
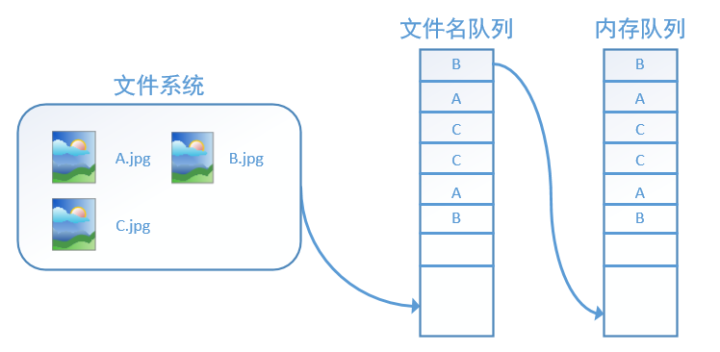
除了tf.train.string_input_producer外,我们还要额外介绍一个函数:tf.train.start_queue_runners。初学者会经常在代码中看到这个函数,但往往很难理解它的用处,在这里,有了上面的铺垫后,我们就可以解释这个函数的作用了。
在我们使用tf.train.string_input_producer创建文件名队列后,整个系统其实还是处于“停滞状态”的,也就是说,我们文件名并没有真正被加入到队列中(如下图所示)。此时如果我们开始计算,因为内存队列中什么也没有,计算单元就会一直等待,导致整个系统被阻塞。

而使用tf.train.start_queue_runners之后,才会启动填充队列的线程,这时系统就不再“停滞”。此后计算单元就可以拿到数据并进行计算,整个程序也就跑起来了,这就是函数tf.train.start_queue_runners的用处。
实战代码
我们用一个具体的例子感受tensorflow中的数据读取。如图,假设我们在当前文件夹中已经有A.jpg、B.jpg、C.jpg三张图片,我们希望读取这三张图片5个epoch并且把读取的结果重新存到read文件夹中。

对应的代码如下:
1 | # 导入tensorflow |
我们这里使用ilename_queue = tf.train.string_input_producer(filename, shuffle=False, num_epochs=5)建立了一个会跑5个epoch的文件名队列。并使用reader读取,reader每次读取一张图片并保存。
运行代码后,我们得到就可以看到read文件夹中的图片,正好是按顺序的5个epoch:

如果我们设置filename_queue = tf.train.string_input_producer(filename, shuffle=False, num_epochs=5)中的uffle=True,那么在每个epoch内图像就会被打乱,如图所示:

我们这里只是用三张图片举例,实际应用中一个数据集肯定不止3张图片,不过涉及到的原理都是共通的。
Datasets API
详细例程可以看tensorflow_dataset_api.py。
这里值得注意的是,使用Datasets API需要初始化操作,而使用Queue需要开启队列。
参考
通信协议之Protocol buffer(Java篇)
Protocol Buffer技术
Tensorflow】你可能无法回避的 TFRecord 文件格式详细讲解
Tensorflow Dataset API详解
十图详解tensorflow数据读取机制(附代码)

