Pytorch的两种保存模型方式
众所周知,Pytorch存储模型主要有两种方式。
方式一:Save/Load state_dict (Recommended)
只保存权重:
1 | torch.save(model.state_dict(), PATH) |
加载模型:
1 | model = TheModelClass(*args, **kwargs) |
方式二:Save/Load Entire Model
保存模型和权重:
1 | torch.save(model, PATH) |
加载模型:
1 | # Model class must be defined somewhere |
注意到方式二在加载模型的时候,官方有一个提醒:# Model class must be defined somewhere,也就是从PATH中读取时需要定义出来TheModelClass,否则的话会直接报错。可能你看到这个地方不是很明白,我们可以做一个实验。
Save/Load Entire Model:缺陷
我们首先定义模型结构,并进行保存,假设下面代码存储在文件E:\Working\torch_save\save_learn.py。
1 | import torch |
执行该文件,可以保存模型到./model_file.pth,并且得到输出如下:
1 | # 输出 |
此时,新建一个文件E:\Working\torch_save\load_learn.py,代码如下:
1 | import torch |
执行该文件,会报错如下,也就是在该文件中,找不到TheModelClass类的定义:
1 | Traceback (most recent call last): |
那么,既然./model_file.pth文件已经保存了模型结构,怎么可以在不知道源代码的情况下,加载进来呢?围绕这个问题,我进行了一系列的探索。
pickle库
再看一遍Pytorch的官方文档,有关于为什么在加载模型时,必须要事先定义类的解释说明:
This save/load process uses the most intuitive syntax and involves the least amount of code. Saving a model in this way will save the entire module using Python’s pickle module. The disadvantage of this approach is that the serialized data is bound to the specific classes and the exact directory structure used when the model is saved. The reason for this is because pickle does not save the model class itself. Rather, it saves a path to the file containing the class, which is used during load time. Because of this, your code can break in various ways when used in other projects or after refactors.
简单来说,Pytorch保存整个module使用的是pickle库,由于这个库在保存类的时候,并不是保存类本身,而是只保存了类名和类定义的位置,在加载的时候,pickle库会找类定义的位置,去加载类的定义。可以看这句话还是很懵逼,我们可以直接去pickle官方库看相应的解释。
以下来自官方文档,为了方便理解,这里将这些内容全部复制过来了。
可以被序列化/反序列化的对象
下列类型可以被封存:
None、True和False- 整数、浮点数、复数
- str、byte、bytearray
- 只包含可封存对象的集合,包括 tuple、list、set 和 dict
- 定义在模块最外层的函数(使用
def定义,lambda函数则不可以) - 定义在模块最外层的内置函数
- 定义在模块最外层的类
- 某些类实例,这些类的
__dict__属性值或__getstate__()函数的返回值可以被封存(详情参阅 封存类实例 这一段)。
尝试封存不能被封存的对象会抛出 PicklingError 异常,异常发生时,可能有部分字节已经被写入指定文件中。尝试封存递归层级很深的对象时,可能会超出最大递归层级限制,此时会抛出 RecursionError 异常,可以通过 sys.setrecursionlimit() 调整递归层级,不过请谨慎使用这个函数,因为可能会导致解释器崩溃。
注意,函数(内置函数或用户自定义函数)在被封存时,引用的是函数全名。这意味着只有函数所在的模块名,与函数名会被封存,函数体及其属性不会被封存。因此,在解封的环境中,函数所属的模块必须是可以被导入的,而且模块必须包含这个函数被封存时的名称,否则会抛出异常。
同样的,类也只封存名称,所以在解封环境中也有和函数相同的限制。注意,类体及其数据不会被封存,所以在下面的例子中类属性 attr 不会存在于解封后的环境中:
1 | import pickle |
用Hex Fiend软件(Windows下的WinHex软件)查看file.pickle文件,可以如下所示,可以看到确实只封存了名称。

这些限制决定了为什么必须在一个模块的最外层定义可封存的函数和类。
类似的,在封存类的实例时,其类体和类数据不会跟着实例一起被封存,只有实例数据会被封存。这样设计是有目的的,在将来修复类中的错误、给类增加方法之后,仍然可以载入原来版本类实例的封存数据来还原该实例。如果你准备长期使用一个对象,可能会同时存在较多版本的类体,可以为对象添加版本号,这样就可以通过类的 __setstate__() 方法将老版本转换成新版本。
封存类实例
在本节中,我们描述了可用于定义、自定义和控制如何封存和解封类实例的通用流程。
通常,使一个实例可被封存不需要附加任何代码。Pickle 默认会通过 Python 的内省机制获得实例的类及属性。而当实例解封时,它的 __init__() 方法通常 不会 被调用。其默认动作是:先创建一个未初始化的实例,然后还原其属性,下面的代码展示了这种行为的实现机制:
1 | def save(obj): |
由此可见,确实是pickle本身的机制导致了Pytorch load的异常。
Hex Fiend分析
那么,真的没有办法去加载保存在./model_file.pth文件中的结构么?我们又从该文件的二进制流中进行分析。用Hex Fiend软件打开./model_file.pth文件,可以在最前面看到一些模型类的定义和类所处的位置,而这些信息跟我们的真实情况一模一样。

那么就可以想到,既然Pytorch在load的时候找不到类的定义和位置,而这些信息在Hex Fiend软件中又可以看到,那我们建立对应的文件,并把类的定义手动复制过来不就行了么?
观察Hex Fiend软件中的信息,发现我们类的定义都是在E:/Working/torch_save/save_learn.py,因此,我们只需要新建一个文件load_test.py,将类的定义放到该文件夹中,如下所示:
1 | import torch |
因为我们这里类的定义都是一个文件中的,所以新建一个文件即可。若类的定义是放在不同的文件中的,则需要建立对应目录的文件,并放对应的类。
运行这个文件,我们发现竟然可以load进来了。
1 | TheModelClass( |
那么能够进行前向推理呢?我们又添加了如下代码:
1 | output = model(torch.ones(1, 3, 32, 32)) |
但是发现会报错:NameError: name 'F' is not defined。也就是说forward前向推理中F未定义。我们导入相应的库import torch.nn.functional as F,此时再运行文件,发现可以推理了,输出如下,推理结果与真实结果一致,说明我们加载成功了。
1 | tensor([[0.5042]], grad_fn=<SigmoidBackward>) |
我们由此还可以得出一个结论:模型在前向推理时会调用forward函数,也就是forward函数必须与真实的forward函数完全一致,否则会报错。
另外,我们还可以观察一下,我在模型定义时用了get_conv()函数来声明卷积层,而该函数的定义在./model_file.pth文件中并没有,但是我们仍然还原出了模型,那么是不是类的初始化并不重要呢?我们把类的初始化代码都删除,只保留代码如下:
1 | import torch |
发现仍然可以推理成功,且结果正确。
最后,我们在运行时还观察到如下warning,也就是TheModelClass的原定义已经被更改了。
/torch/serialization.py:671: SourceChangeWarning: source code of class ‘main.TheModelClass’ has changed. you can retrieve the original source code by accessing the object’s source attribute or set
torch.nn.Module.dump_patches = Trueand use the patch tool to revert the changes.
warnings.warn(msg, SourceChangeWarning)
我们点开该warning提醒的位置,可以发现Pytorch会将保存在./model_file.pth文件中的源码与当前的源码进行对比。值得注意的是,下面有一行代码if container_type.dump_patches:,这个是nn.Module才有的属性,所以在还原类的时候,必须让类继承nn.Module,否则还原的时候会保存。
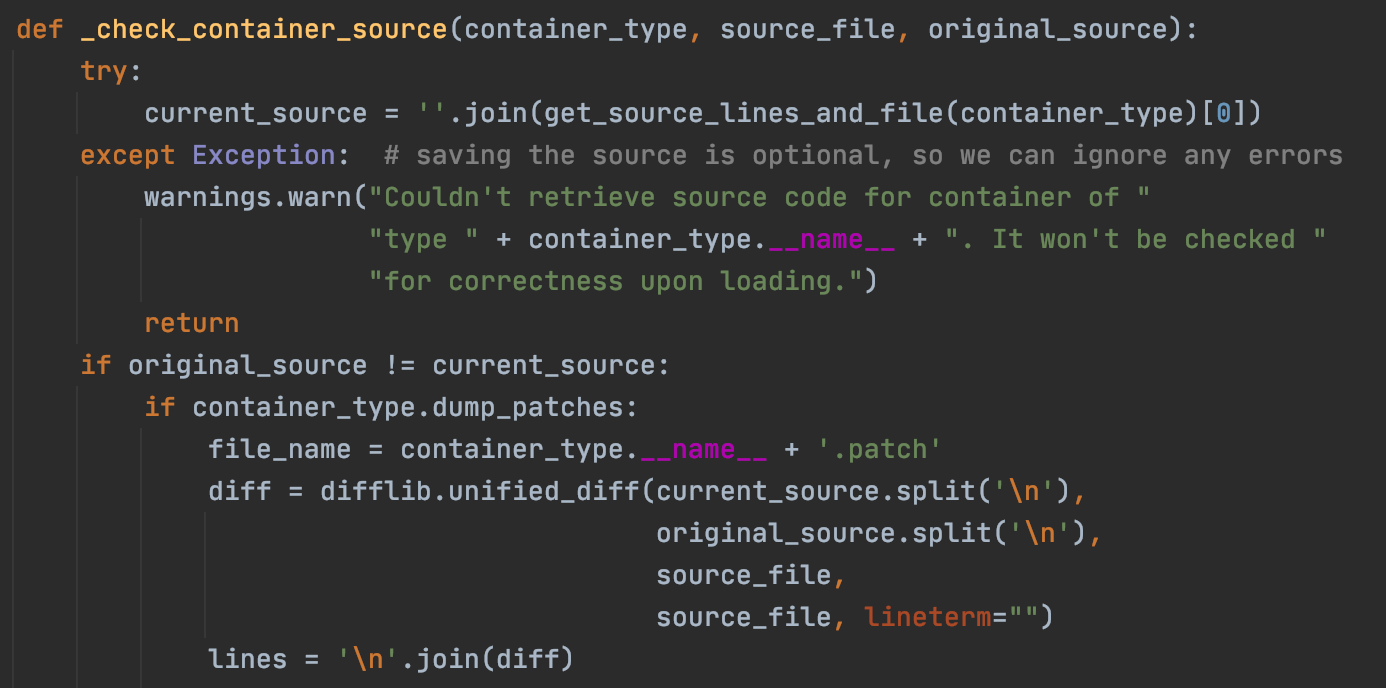
那么我们就可以得出另一个结论:类的具体初始化可以没有或者不正确,但是类的位置和名字必须正确,且类必须继承nn.Module。
压缩存储方式
在本文的开头,我们在保存模型的时候,使用了参数_use_new_zipfile_serialization=False,这会使用非压缩存储方式。若不使用该参数,存储模型的时候,会采用压缩存储方式。这种存储方式并不会保存像类的定义和位置这些信息,而且会进行压缩(因为我们可以用zip解压模型文件)。
至于为什么说这种存储方式并不会保存类的定义和位置呢?这不仅仅可以通过Hex Fiend分析得到,而且还可以直接看torch save的源代码,其文件位于torch\serialization.py中。
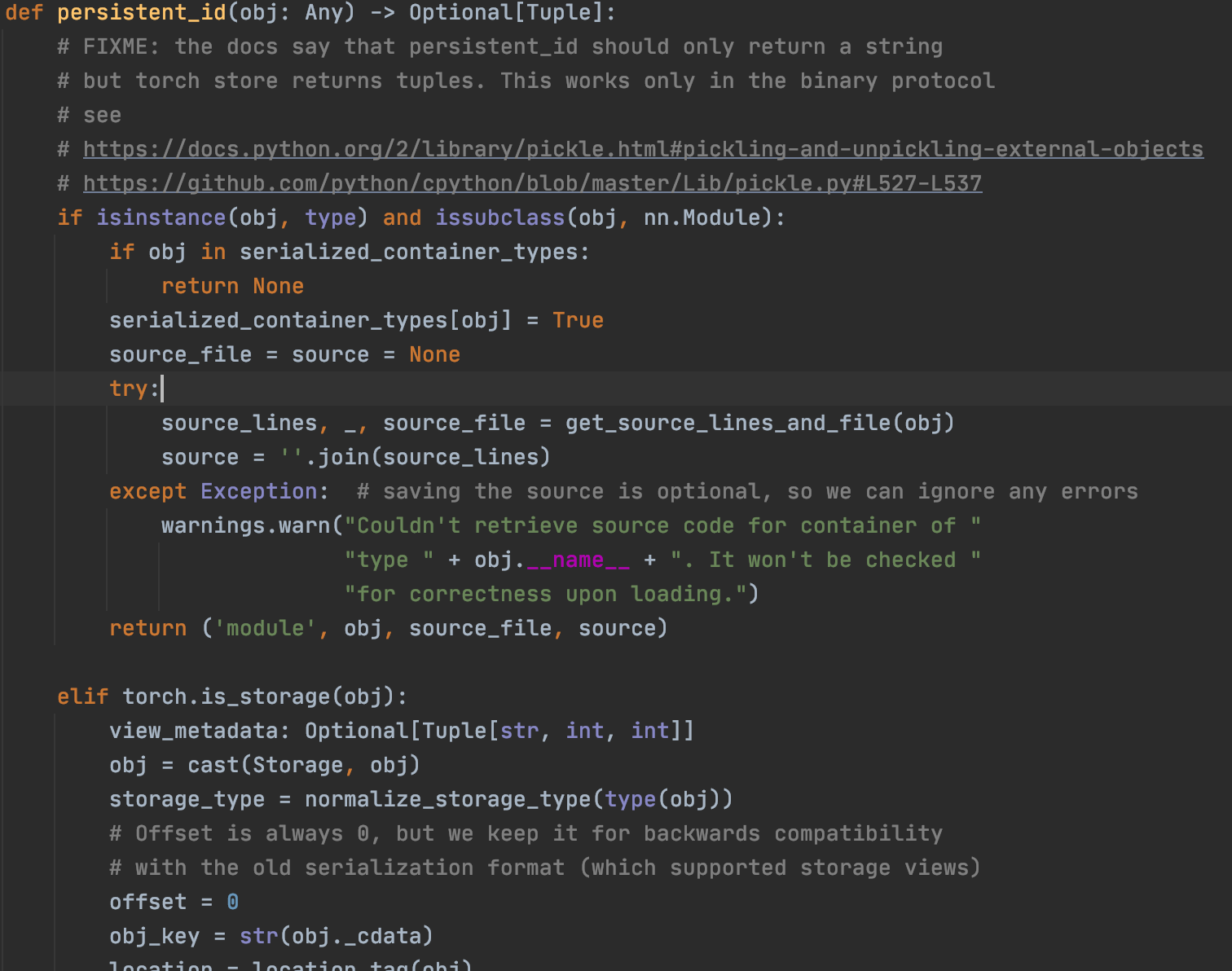
如下是非压缩存储方式,在持久化存储时使用的代码(关于持久化存储可以看官方的代码)。
如下是压缩存储方式,在持久化存储时使用的代码。
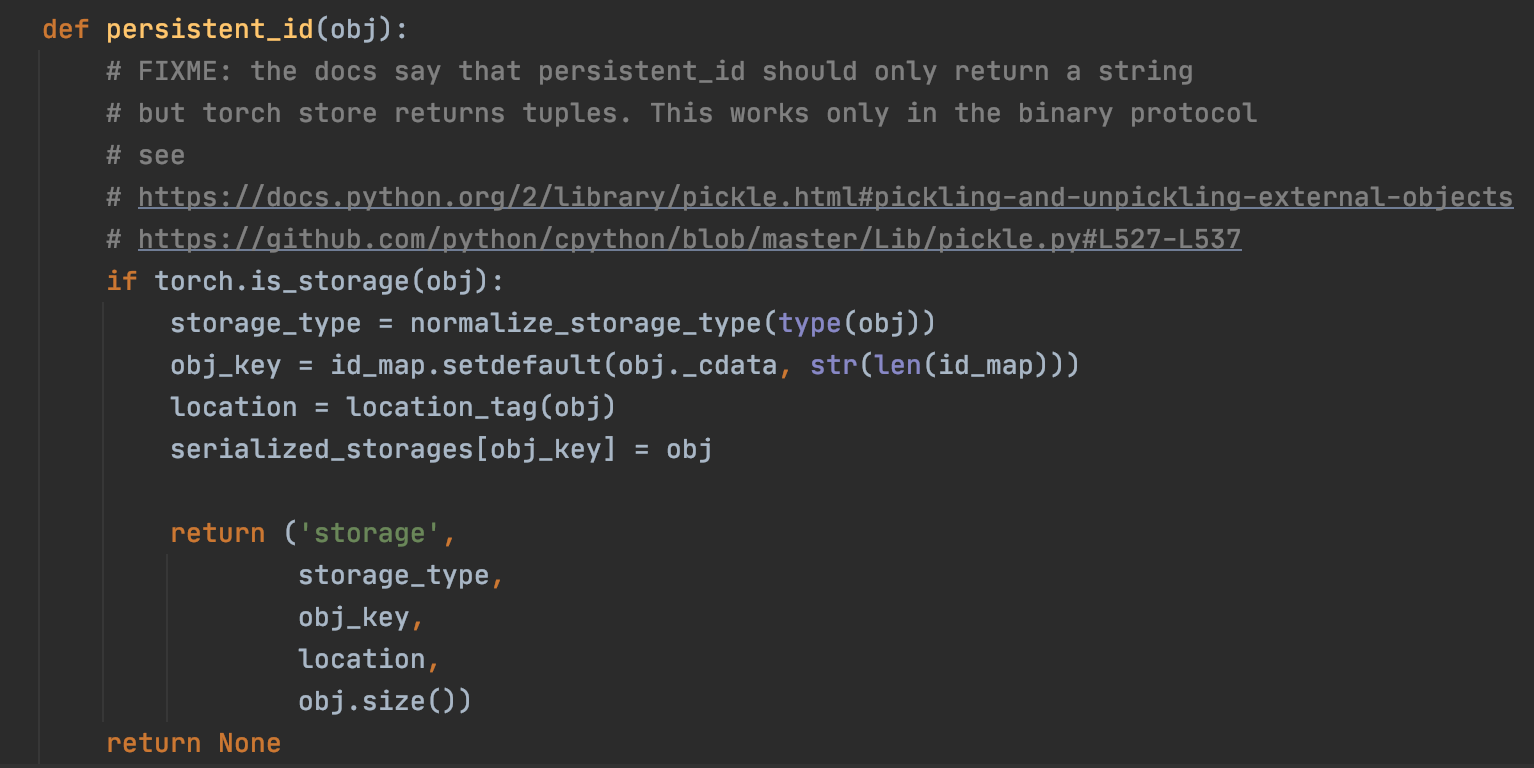
对比一下可以发现,非压缩存储方式查询相应的源码并进行保存,而压缩存储方式不会。
前面介绍说pickle并不会保存类的实现,而Pytorch在非压缩存储方式却保存了相应的源码,这也跟上述的持久化存储函数有关。
因此像前文介绍的,从Hex Fiend中获取类的定义和位置,然后实现模型的load和推理,并不适合压缩存储方式。而对于压缩存储方式,当同时存储了模型和权重,同时又没有源码的情况下,如何load并推理,目前还没有研究出来。
总结
我们最后做一下总结:
- Pytorch存储Entire Model的时候,有非压缩(旧)与压缩(新)两种方式。这两种方式都会借助于pickle库实现保存。
- pickle库本身在封存类的时候,只会封装类名,其类体和类数据不会跟着实例一起被封存。这导致了Pytorch恢复Entire Model时,必须要有类的定义。
- 在恢复Entire Model时,Model类的具体初始化可以没有或者不正确,但是类的位置和名字必须正确,且类必须继承
nn.Module。模型在前向推理时会调用forward函数,也就是forward函数必须与真实的forward函数完全一致,否则会报错。 - 非压缩的的方式,会将所有Model Class源代码保存下来,而压缩的方式并不会保存这些信息。因此前者可以通过手动恢复Model Class定义的方式来加载模型,而后者不可以。

