在pytorch中,官方向我们提供了用于学习率控制的辅助类Scheduler,这些类位于torch.optim.lr_scheduler下。在这些类中提供了基于epoch的学习率调整方法。
torch.optim.lr_scheduler.LambdaLR
将每一个参数组的学习率设置为初始学习率乘以给定的学习率,当last_epoch=-1时,将学习率设定为初始学习率。
例如:
1 | lambda1 = lambda epoch: epoch // 30 |
torch.optim.lr_scheduler.StepLR
每step_size步给每一个参数组乘以gamma。这一衰减可以和scheduler之外学习率的改变一起发生。
例如:
1 | >>>> # Assuming optimizer uses lr = 0.05 for all groups |
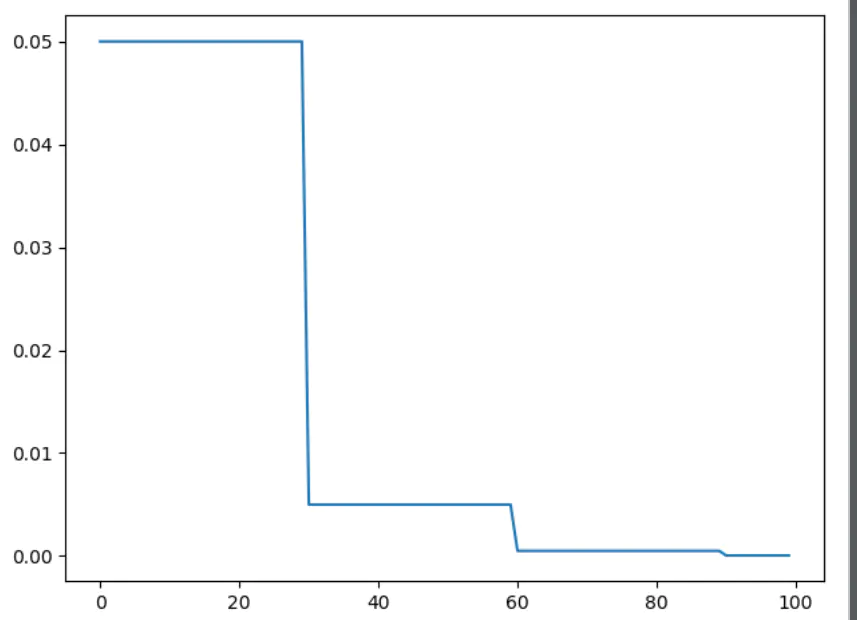
torch.optim.lr_scheduler.MultiStepLR
在指定的epoch,给每一个参数组乘以gamma。这一衰减可以和scheduler之外的衰减同时发生。
例如:
1 | >>>> # Assuming optimizer uses lr = 0.05 for all groups |
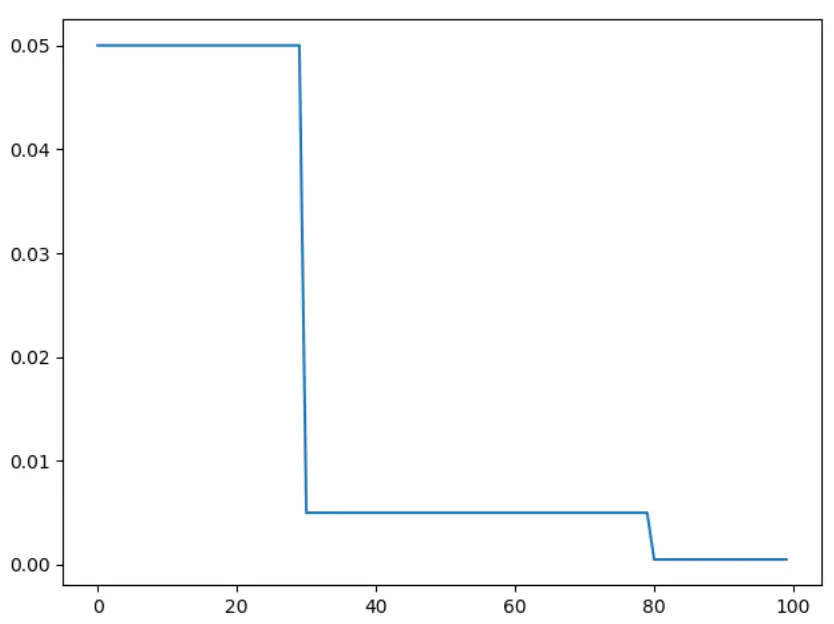
torch.optim.lr_scheduler.ExponentialLR
对学习率进行指数衰减。
例如:
1 | scheduler = lr_scheduler.ExponentialLR(optimizer, gamma=0.9) |
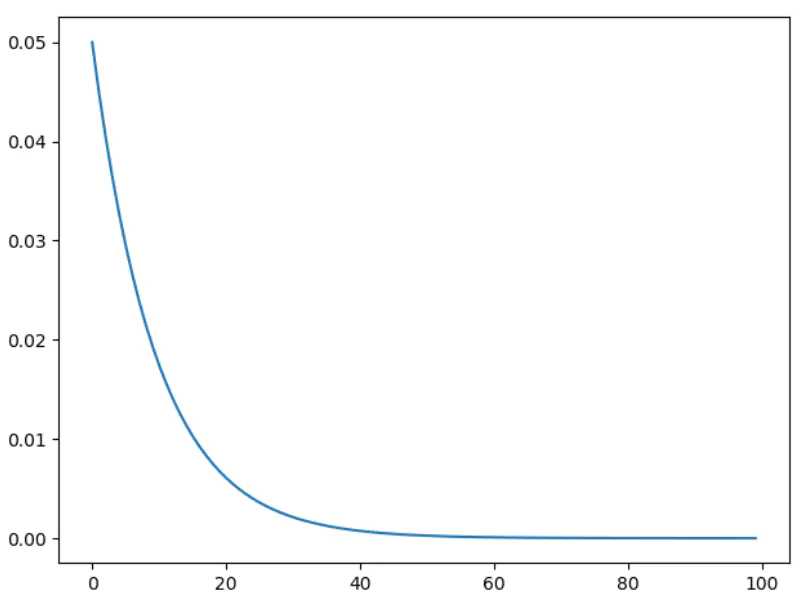
torch.optim.lr_scheduler.CosineAnnealingLR
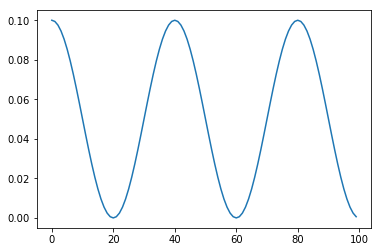
余弦退火衰减,在采用小批量随机梯度下降(MBGD/SGD)算法时,神经网络应该越来越接近 Loss 值的全局最小值。当它逐渐接近这个最小值时,学习率应该变得更小来使得模型不会超调且尽可能接近这一点。余弦退火利用余弦函数来降低学习率,进而解决这个问题。
如果学习率仅由这一scheduler设定,那么每一步的学习率的计算公式如下:
由上式可以看出,每隔$T_{max}$个epoch,学习率会重启为初始学习率。
例如,设置总的epochs为100,$T_{max}=20$,学习率变化曲线如下图所示:
设置总的epochs为100,$T_{max}=100$,学习率变化曲线如下图所示:
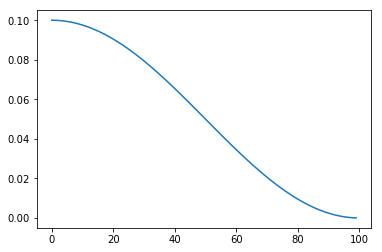
1 | import torch |
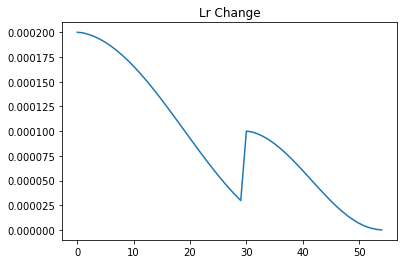
torch.optim.lr_scheduler.ReduceLROnPlateau
当某一给定的矩阵停止提升时,对学习率进行衰减。这一scheduler读取给定的矩阵,当该矩阵的数值在patience个epoch内未提升时,衰减学习率。
1 | >>>> optimizer = torch.optim.SGD(model.parameters(), lr=0.1, momentum=0.9) |
torch.optim.lr_scheduler.CyclicLR
依据循环学习率策略对每一个参数组的学习率进行设置。这一策略以固定的频率在两个边界之间对学习率进行设定。
循环学习率策略在每一个batch的训练之后对学习率进行调整,也就是说,应该在每一次训练步骤完成之后调用.step方法。
这个类由三个内建的调整策略:
- triangular:基础循环,不对幅度进行缩放。
- triangular2:基础三角循环,在每一次循环中对幅值减半。
- exp_range:在每一次循环迭代中,对初始学习率乘以
gamma**(cycle iterations)。

