import os from os.path import exists import torch import torch.nn as nn from torch.nn.functional import log_softmax, pad import math import copy import time from torch.optim.lr_scheduler import LambdaLR import pandas as pd import altair as alt from torchtext.data.functional import to_map_style_dataset from torch.utils.data import DataLoader from torchtext.vocab import build_vocab_from_iterator import torchtext.datasets as datasets import spacy import GPUtil
from torch.utils.data.distributed import DistributedSampler import torch.distributed as dist import torch.multiprocessing as mp from torch.nn.parallel import DistributedDataParallel as DDP
# Set to False to skip notebook execution (e.g. for debugging) RUN_EXAMPLES = True
defforward(self, src, tgt, src_mask, tgt_mask): "Take in and process masked src and target sequences." return self.decode(self.encode(src, src_mask), src_mask, tgt, tgt_mask)
classSublayerConnection(nn.Module): """ A residual connection followed by a layer norm. Note for code simplicity the norm is first as opposed to last. """
defforward(self, x, memory, src_mask, tgt_mask): for layer in self.layers: x = layer(x, memory, src_mask, tgt_mask) return self.norm(x)
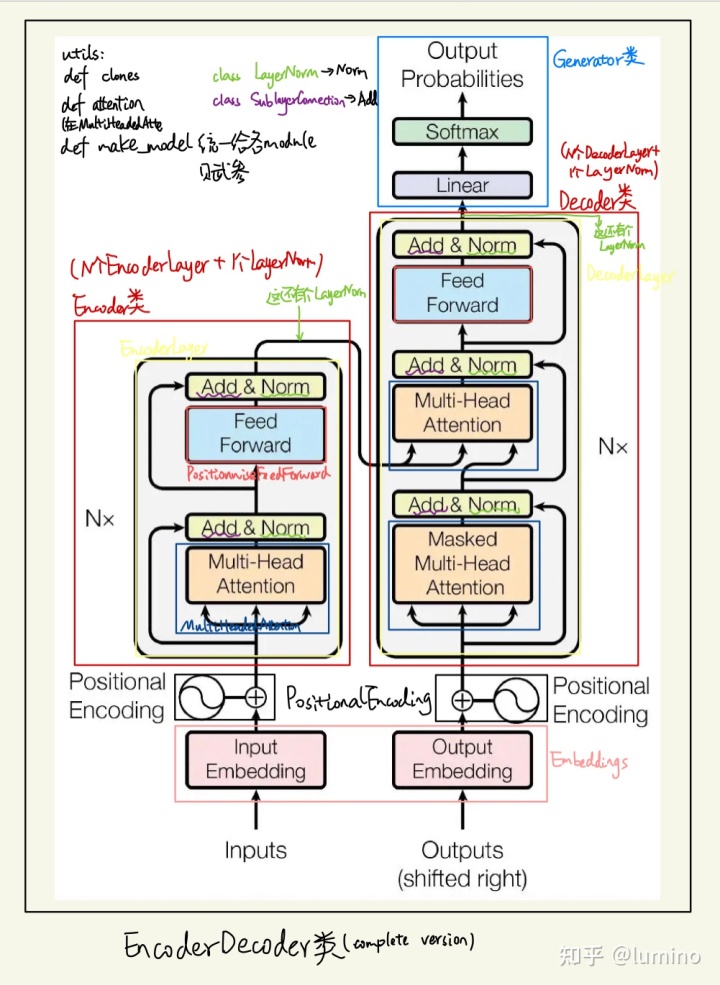
在每个encoder layer除了两个 sub-layers 外,还插入了第三个sub-layer,它在encoder stack的输出上执行multi-head attention。与encoder相同,我们在each of the two sub-layers使用残差连接,并且后接layer normalization。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17
classDecoderLayer(nn.Module): "Decoder is made of self-attn, src-attn, and feed forward (defined below)"
defforward(self, x, memory, src_mask, tgt_mask): "Follow Figure 1 (right) for connections." m = memory x = self.sublayer[0](x, lambda x: self.self_attn(x, x, x, tgt_mask)) x = self.sublayer[1](x, lambda x: self.src_attn(x, m, m, src_mask)) return self.sublayer[2](x, self.feed_forward)
我们还修改了decoder中的self-attention sub-layer,以防止它利用到后续位置的信息。This masking, combined with fact that the output embeddings are offset by one position, ensures that the predictions for position $i$ can depend only on the known outputs at positions less than $i$ .
defexample_mask(): LS_data = pd.concat( [ pd.DataFrame( { "Subsequent Mask": subsequent_mask(20)[0][x, y].flatten(), "Window": y, "Masking": x, } ) for y in range(20) for x in range(20) ] )
attention函数可以被描述为 mapping a query and a set of key-value pairs to an output,其中query, keys, values, and output都是向量。output是values的加权求和,其中每个value的权重是通过query with the corresponding key的compatibility function计算得到。
我们将这种特别的attention称为“Scaled Dot-Product Attention”。它的输入由$d_k$维度的queries、keys,$d_v$维度的values组成。 We compute the dot products of the query with all keys, divide each by $\sqrt{d_k}$, and apply a softmax function to obtain the weights on the values。
最常用的两个attention函数是additive attention和dot-product (multiplicative) attention。后者除了没有缩放$\frac{1}{\sqrt{d_k}}$,其余与我们的相同。而Additive attention computes the compatibility function using a feed-forward network with a single hidden layer. 虽然两者在理论复杂性上相似,但dot-product attention在实践中要快得多,空间效率更高,因为它可以使用高度优化的矩阵乘法代码来实现。
虽然对于较小的$d_k$值,这两种机制的性能相似,但对于较大的$d_k$值,additive attention优于dot product attention。我们怀疑较大的$d_k$值,dot product的幅度会增大,从而将Softmax函数推入其梯度极小的区域。(To illustrate why the dot products get large, assume that the components of $q$ and $k$ are independent random variables with mean $0$ and variance $1$. Then their dot product, $q \cdot k = \sum_{i=1}^{d_k} q_ik_i$, has mean $0$ and variance$d_k$.). 为了抵消这种影响,我们使用$\frac{1}{\sqrt{d_k}}$对dot products进行缩放。
Multi-head attention allows the model to jointly attend to information from different representation subspaces at different positions. 当仅有一个 attention head,平均化抑制了这一点。
Where the projections are parameter matrices $W^Q_i \in \mathbb{R}^{d_{\text{model}} \times d_k}$, $W^K_i \in \mathbb{R}^{d_{\text{model}} \times d_k}$, $W^V_i \in \mathbb{R}^{d_{\text{model}} \times d_v}$ and $W^O \in \mathbb{R}^{hd_v \times d_{\text{model}}}$。在本工作中,我们使用了$h=8$个平行attention layers, or heads。对于其中每一个,我们使用了$d_k=d_v=d_{\text{model}}/h=64$。由于each head的维度降低了,所以总的计算量与full dimensionality的single-head attention相同。
classMultiHeadedAttention(nn.Module): def__init__(self, h, d_model, dropout=0.1): "Take in model size and number of heads." super(MultiHeadedAttention, self).__init__() assert d_model % h == 0 # We assume d_v always equals d_k self.d_k = d_model // h self.h = h self.linears = clones(nn.Linear(d_model, d_model), 4) self.attn = None self.dropout = nn.Dropout(p=dropout)
defforward(self, query, key, value, mask=None): "Implements Figure 2" if mask isnotNone: # Same mask applied to all h heads. mask = mask.unsqueeze(1) nbatches = query.size(0)
# 1) Do all the linear projections in batch from d_model => h x d_k query, key, value = [ lin(x).view(nbatches, -1, self.h, self.d_k).transpose(1, 2) for lin, x in zip(self.linears, (query, key, value)) ]
# 2) Apply attention on all the projected vectors in batch. x, self.attn = attention( query, key, value, mask=mask, dropout=self.dropout )
# 3) "Concat" using a view and apply a final linear. x = ( x.transpose(1, 2) .contiguous() .view(nbatches, -1, self.h * self.d_k) ) del query del key del value return self.linears[-1](x)
Applications of Attention in our Model
Transformer以三种不同的方式使用了multi-head attention。
在“encoder-decoder attention” layers中,queries来自于之前的decoder layer, memory keys and values 来自encoder的输出。This allows every position in the decoder to attend over all positions in the input sequence. 这模仿了sequence-to-sequence模型中典型的encoder-decoder attention机制。
encoder中的self-attention layers. 这里的self-attention layers中,所有的 keys, values and queries均来自于上一层的输出。Each position in the encoder can attend to all positions in the previous layer of the encoder.
decoder中的self-attention layers. self-attention layers in the decoder allow each position in the decoder to attend to all positions in the decoder up to and including that position(up to and including:直到并包括)。我们需要防止信息在decoder中向左流动,以保持自回归(auto-regressive)特性。我们在scaled dot-product attention中实现了这一点,通过屏蔽Softmax输入中对应于非法连接的所有值(设置为$-\infty$)。
Position-wise Feed-Forward Networks
除了attention sub-layers,encoder and decoder中的每一层都包含一个fully connected feed-forward network(完全连接的前馈网络),该网络分别且相同地应用于每个位置。它由两个线性变换组成,中间有一个ReLU激活。
与其它的sequence transduction models相似,we use learned embeddings to convert the input tokens and output tokens to vectors of dimension $d_{\text{model}}$。我们还使用常用的 linear transformation and softmax function 将 decoder output转换为 predicted next-token probabilities. 在我们的模型中,我们在two embedding layers 和pre-softmax linear transformation共享相同的权重矩阵。在embedding layers,我们multiply those weights by $\sqrt{d_{\text{model}}}$。
defmake_model( src_vocab, tgt_vocab, N=6, d_model=512, d_ff=2048, h=8, dropout=0.1 ): "Helper: Construct a model from hyperparameters." c = copy.deepcopy attn = MultiHeadedAttention(h, d_model) ff = PositionwiseFeedForward(d_model, d_ff, dropout) position = PositionalEncoding(d_model, dropout) model = EncoderDecoder( Encoder(EncoderLayer(d_model, c(attn), c(ff), dropout), N), Decoder(DecoderLayer(d_model, c(attn), c(attn), c(ff), dropout), N), nn.Sequential(Embeddings(d_model, src_vocab), c(position)), nn.Sequential(Embeddings(d_model, tgt_vocab), c(position)), Generator(d_model, tgt_vocab), )
# This was important from their code. # Initialize parameters with Glorot / fan_avg. for p in model.parameters(): if p.dim() > 1: nn.init.xavier_uniform_(p) return model
@staticmethod defmake_std_mask(tgt, pad): "Create a mask to hide padding and future words." tgt_mask = (tgt != pad).unsqueeze(-2) tgt_mask = tgt_mask & subsequent_mask(tgt.size(-1)).type_as( tgt_mask.data ) return tgt_mask
Training Loop
接下来我们创建一个通用的训练和打分函数,来跟踪损失。我们传入一个损失函数,它还会执行参数更新。
1 2 3 4 5 6 7
classTrainState: """Track number of steps, examples, and tokens processed"""
step: int = 0# Steps in the current epoch accum_step: int = 0# Number of gradient accumulation steps samples: int = 0# total # of examples used tokens: int = 0# total # of tokens processed
defrun_epoch( data_iter, model, loss_compute, optimizer, scheduler, mode="train", accum_iter=1, train_state=TrainState(), ): """Train a single epoch""" start = time.time() total_tokens = 0 total_loss = 0 tokens = 0 n_accum = 0 for i, batch in enumerate(data_iter): out = model.forward( batch.src, batch.tgt, batch.src_mask, batch.tgt_mask ) loss, loss_node = loss_compute(out, batch.tgt_y, batch.ntokens) # loss_node = loss_node / accum_iter if mode == "train"or mode == "train+log": loss_node.backward() train_state.step += 1 train_state.samples += batch.src.shape[0] train_state.tokens += batch.ntokens if i % accum_iter == 0: optimizer.step() optimizer.zero_grad(set_to_none=True) n_accum += 1 train_state.accum_step += 1 scheduler.step()
total_loss += loss total_tokens += batch.ntokens tokens += batch.ntokens if i % 40 == 1and (mode == "train"or mode == "train+log"): lr = optimizer.param_groups[0]["lr"] elapsed = time.time() - start print( ( "Epoch Step: %6d | Accumulation Step: %3d | Loss: %6.2f " + "| Tokens / Sec: %7.1f | Learning Rate: %6.1e" ) % (i, n_accum, loss / batch.ntokens, tokens / elapsed, lr) ) start = time.time() tokens = 0 del loss del loss_node return total_loss / total_tokens, train_state
Training Data and Batching
我们在标准的WMT 2014英语-德语数据集上进行了训练,该数据集由大约450万个句子对组成。Sentences were encoded using byte-pair encoding, which has a shared source-target vocabulary of about 37000 tokens. 对于英语-法语,我们使用了更大的2014年WMT英语-法语数据集,包括3600万个句子和split tokens into a 32000 word-piece vocabulary.
Sentence pairs were batched together by approximate sequence length. 每个训练批次包含一组句子对,其中包含大约25000个source tokens和25000个target tokens。
def rate(step, model_size, factor, warmup): """ we have to default the step to 1 for LambdaLR function to avoid zero raising to negative power. """ if step == 0: step = 1 return factor * ( model_size ** (-0.5) * min(step ** (-0.5), step * warmup ** (-1.5)) )
# we have 3 examples in opts list. for idx, example in enumerate(opts): # run 20000 epoch for each example optimizer = torch.optim.Adam( dummy_model.parameters(), lr=1, betas=(0.9, 0.98), eps=1e-9 ) lr_scheduler = LambdaLR( optimizer=optimizer, lr_lambda=lambda step: rate(step, *example) ) tmp = [] # take 20K dummy training steps, save the learning rate at each step for step in range(20000): tmp.append(optimizer.param_groups[0]["lr"]) optimizer.step() lr_scheduler.step() learning_rates.append(tmp)
learning_rates = torch.tensor(learning_rates)
# Enable altair to handle more than 5000 rows alt.data_transformers.disable_max_rows()
我们使用KL div loss实现label smoothing. Instead of using a one-hot target distribution, we create a distribution that has confidence of the correct word and the rest of the smoothing mass distributed throughout the vocabulary.
defdata_gen(V, batch_size, nbatches): "Generate random data for a src-tgt copy task." for i in range(nbatches): data = torch.randint(1, V, size=(batch_size, 10)) data[:, 0] = 1 src = data.requires_grad_(False).clone().detach() tgt = data.requires_grad_(False).clone().detach() yield Batch(src, tgt, 0)
Loss Computation
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16
classSimpleLossCompute: "A simple loss compute and train function."
if is_interactive_notebook(): # global variables used later in the script spacy_de, spacy_en = show_example(load_tokenizers) vocab_src, vocab_tgt = show_example(load_vocab, args=[spacy_de, spacy_en])
defaverage(model, models): "Average models into model" for ps in zip(*[m.params() for m in [model] + models]): ps[0].copy_(torch.sum(*ps[1:]) / len(ps[1:]))
src_tokens = [ vocab_src.get_itos()[x] for x in rb.src[0] if x != pad_idx ] tgt_tokens = [ vocab_tgt.get_itos()[x] for x in rb.tgt[0] if x != pad_idx ]
print( "Source Text (Input) : " + " ".join(src_tokens).replace("\n", "") ) print( "Target Text (Ground Truth) : " + " ".join(tgt_tokens).replace("\n", "") ) model_out = greedy_decode(model, rb.src, rb.src_mask, 72, 0)[0] model_txt = ( " ".join( [vocab_tgt.get_itos()[x] for x in model_out if x != pad_idx] ).split(eos_string, 1)[0] + eos_string ) print("Model Output : " + model_txt.replace("\n", "")) results[idx] = (rb, src_tokens, tgt_tokens, model_out, model_txt) return results
defrun_model_example(n_examples=5): global vocab_src, vocab_tgt, spacy_de, spacy_en
defmtx2df(m, max_row, max_col, row_tokens, col_tokens): "convert a dense matrix to a data frame with row and column indices" return pd.DataFrame( [ ( r, c, float(m[r, c]), "%.3d %s" % (r, row_tokens[r] if len(row_tokens) > r else"<blank>"), "%.3d %s" % (c, col_tokens[c] if len(col_tokens) > c else"<blank>"), ) for r in range(m.shape[0]) for c in range(m.shape[1]) if r < max_row and c < max_col ], # if float(m[r,c]) != 0 and r < max_row and c < max_col], columns=["row", "column", "value", "row_token", "col_token"], )
defviz_encoder_self(): model, example_data = run_model_example(n_examples=1) example = example_data[ len(example_data) - 1 ] # batch object for the final example