再有几个小时比赛就要结束了,但是只有前20名可以进决赛,我们还在30名左右徘徊。虽然没什么希望进决赛,但是还是可以总结总结的。毕竟如果不总结过段时间就会全部忘记。
另外,这次比赛的源代码已经释放出来了,具体点这里。
任务介绍
本赛题任务是对西安的热门景点、美食、特产、民俗、工艺品等图片进行分类,即首先识别出图片中物品的类别(比如大雁塔、肉夹馍等),然后根据图片分类的规则,输出该图片中物品属于景点、美食、特产、民俗和工艺品五大类中的哪一种。
模型输出格式:
1 | { |
也就是本次任务,根据数据类标主要有两个思路:
- 先分大类,再分小类
- 直接分小类
另外比赛还要求:
除本次大赛提供的训练数据之外,参赛选手也可以使用其他来源的图片数据。
不允许使用“测试时增强”策略和“模型融合”策略(如投票、stacking和blending)来提升模型的效果,只能使用端到端预测的单模型,每个赛事阶段结束后,都会要求入围选手提交代码和模型,由赛事组进行人工审核模型是否符合要求。
难点
本次比赛虽然是较为简单的分类任务,但是背后也有几个难点,主要如下:
- 开放了所使用数据集,选手可以使用其他来源的图片数据。所以对数据的搜集、清洗、分析能力要求较高
- 图像尺寸多变,且大部分图像宽高不是成比例的
- 测试数据集只有1000张图片,规模过小以至于几张图片的分错就会导致名次波动很大
- 各个类别的样本不均衡且相差较大
数据集
这次比赛官方数据集给了一共3731张图片,测试数据集一共有1000张。
其中,数据集的样例如下:

该图片对应的txt文件中的内容为:
1 | img_4122.jpg, 50 |
数据分析
首先,对官方数据集的各个类别的样本数量进行统计,统计结果如下:
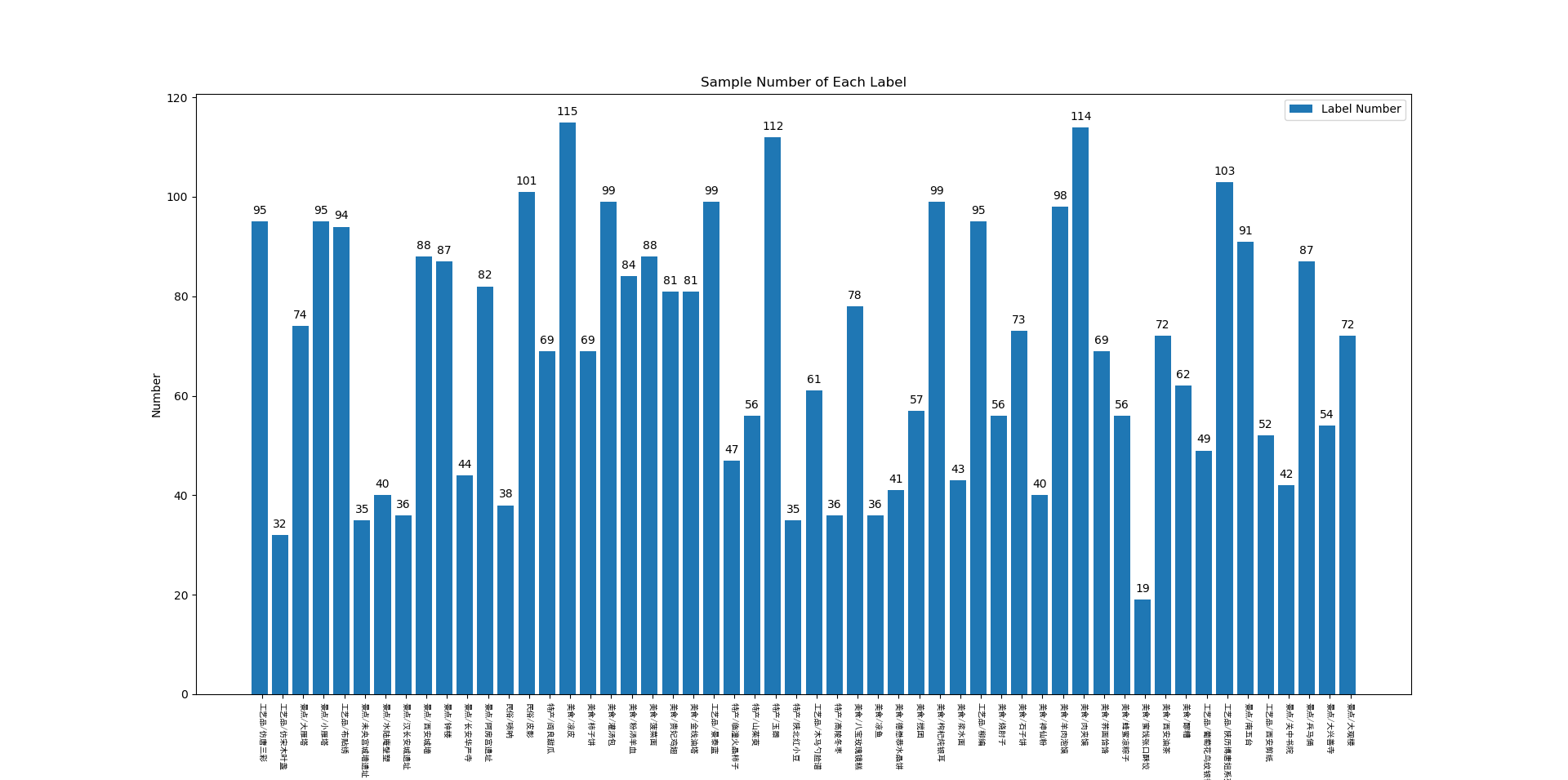
从该图中可以看出,该数据集的类别分布是及其不均衡的,最多的样本为凉皮(数量为115张),而数量最少的是蜜饯张口酥饺(数量为19张)。
然后,对官方数据集的宽高比例进行分析,分析结果如下(只显示多于100张图片的比例):
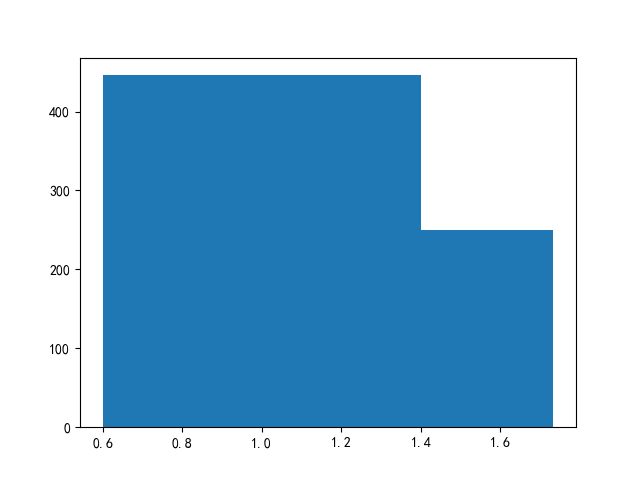
从上图中可以看出,大部分图像的宽高比例均在0.6到1.4之间。也就是说若输入宽高等比例的正方形图像也是有所依据的。
最后对图像的平均宽度和平均高度进行分析,结果显示所有图像的平均宽为610,而平均高为497。
数据增强
除了常用的数据resize和标准化操作外,我们还用了一些别的数据增强方式:
首先,对于图像而言,颜色是特别重要的特征,但是有的时候需要模型去一些关注除了颜色之外的特征。例如柿子一般是红色的,如果模型过度关注颜色特征,可能会将非红色的柿子判定为其他类别。因此我们加入了灰度变换,概率为0.3。(加上灰度变换后性能会提升大概0.001)
为了增强网络的鲁棒性,提高模型的泛化能力,我们采用了CutMix的正则化增强方式,CutMix的概率为0.5(加上CutMix后,在训练数据集上最终正确率会稳定到0.90附近,但是网络的泛化性能比较稳定,表现为在官方测试数据集上分数比较稳定)。
比赛前期,我们也采用过随机擦除(Random Erase)的方式,但是网络的泛化性能不是很稳定。猜测是因为随机擦除可能会导致图像中的一些像素信息丢失,使得模型关注点反复变化。
另外,我们还采用了随机左右翻转,概率为0.5。考虑到景点图等一般情况是不会上下颠倒的(例如大雁塔一般情况下不会倒过来),而有一部分类别是有可能上下颠倒的(例如布贴绣),所以我们也采用了随机上下翻转,概率为0.25。经过测试,若去掉上下翻转,测试集上的正确率会从0.958掉到0.949,性能下降的特别明显。
最后,考虑到图像可能带有一些旋转(例如布贴绣),我们采用了ShiftScaleRotate变换,详细信息可以点这里。
我们数据集采用的直接Resize到特定尺寸的形式,但是如果采用ImageNet数据集中常用的随机中心裁剪,在测试集上的性能会下降0.5左右的分数;另外,考虑到图像中目标的形状比较重要,若采用等比例中心裁剪的方式,测试集上的正确率会从0.958掉到0.948,性能下降的特别明显。
之所以出现这种情况,一方面是与ImageNet数据不同,我们数据集中的目标不一定在图像中间。而若采用等比例中心裁剪会导致图像出现大量黑块,而黑块的位置不定而且大小不定,这对模型的训练不是特别友好。
数据扩充与清洗
该比赛是允许使用额外数据集的,所以数据的扩充与清洗特别重要。因此,我们也对数据集进行了扩充,在扩充之前,在测试集上的最高正确率为0.958,而扩充之后,相同的参数最高正确率为0.967。下面就对数据的扩充与清洗策略进行介绍。
第一步,使用Python爬虫脚本从必应、百度、Google等下载相应类别的图片,然后以“类别名称+编号”命名,例如“凉鱼_79.jpg”。
这里有一个小技巧,凉鱼在西安还有另外一个叫法——“浆水鱼鱼”,同时搜索“凉鱼”和“浆水鱼鱼”可以下载到更多的图片。
第二步,对数据进行初步清洗,删除掉损坏的图片并将所有图片格式统一为jpg格式。
第三步,挑选在官方数据集上表现最好的模型,对这些图片的类别进行预测,并将预测结果写入到名称为“类别+编号.txt”中。例如,将上面“凉鱼_79.jpg”的预测结果写入到“凉鱼_79.txt”中。txt文件的内容为凉鱼_79.jpg, 33,即文件名称+类别编号。
第四步,删除掉所有预测类别与文件名称对应类别不符的图片。例如,若上面的“凉鱼_79.jpg”,相同名称的txt文件内容为“凉鱼_79.jpg, 32”,而编号32对应的“凉皮”。出现这种情况有两种原因,一是网络对这个图片预测错了,二是该图片本身就是为“凉皮”。为了减轻人工筛选数据集的麻烦,我们对这类数据统一删除了。
第五步,人工快速过一遍这些数据集,删除掉一些明显错误的样本。
一开始,我们人工删除的比较极端,将模棱两可的、明显错误的、遮挡严重的、图像分辨率过低的、图像中主体不明确的(例如只有“石子”的“石子饼”图片)、手工图、旅游概念图等全部删除了。这样导致了数据多样性不足,在验证集上比较高,测试集表现很差。所以人工删除数据集只需要删除肯定是错的样本就行了。
第六步,将扩充数据集和官方数据集合并,因为考虑到官方数据集也是从网上爬虫下载的,为了防止相同的图片同时出现在训练集和验证集,导致验证集上正确率过高,我们删除了重复样本。删除重复样本的方法为:对比所有文件的md5值,对于md5值相同的样本,只保留第一个样本,其余删除。并检查是否每一个jpg文件都对应这相同名称的txt文件。
第七步,将全部数据集划分五折进行训练,并在训练集和验证集进行Demo,查看所有分错的样本,看是否为标注错误。对于标错样本的样本,直接删除。
关于这方面内容,有两个主要问题,这两个问题我们并没有解决的很好,希望有相关经验的大佬可以指教指教:
(1)扩充多少样本比较合适?
这个问题没有一个统一的定论,我们一开始扩充了大概两倍,训练出来结果还可以,但是扩充五倍后,正确率反而下降了。个人感觉可能是数据集扩充更多之后,类别更加不均衡了,使得模型在某一类上过拟合,而有些类别欠拟合。这就引出了第二个问题
(2)每一类该如何扩充?
这个问题,我们目前也没有好的主意,已经测试过的方案有:
- 将所有类别统一补充到相同的数量,这种方案没有什么起色。个人感觉这种方案不太好的原因是:有些类别本来已经分的很好的,又添加了一些多余的样本;而有些样本分的不是很好,添加的样本反而不足。
- 根据验证集各个类别的得分补充数据集,得分高的多补充,而得分低的少补充。这样方案可以使得验证集上的得分提升很大(从0.9675提升到0.9821),但是预测数据集得分反而从0.958掉到了0.957。猜测是因为这样我们就偷窥了验证集的分布,导致在验证集上表现很好,而验证集分布和测试集分布相差较大。因此,这种方法适合验证集和测试集分布相差不大的数据集
- 将清洗完的数据全部补充进去,我们一直采用的是这种方案。
数据划分
关于扩充数据集的使用,有两种方案:
- 方案一:在全部数据集上统一划分五折,因为这是一个类别不均衡问题,所以要采用了分层交叉验证的方法。支持这一种方案的理由是,官方数据集本身就不是很多,若采用第二种方案,官方数据集并没有完全利用起来。
- 方案二:在官方数据集上划分一部分作为验证集,自己扩充数据集全部用于训练集。支持这一种方案的理由是,官方数据集比较有权威性并且数据分布很可能和官方一致。
这两种方案,我们均尝试过,均出现了验证集上的分数很高,甚至可以达到0.99,但是官方测试数据集表现最好的只为0.979。也就是这两种方案的验证集分布与官方测试数据集的分布均有一定的差异。
但是个人感觉以后采用方案二比较靠谱一点,因为官方数据集还是比较有权威的,而自己标记的数据集不一定完全正确。
模型
理论
机器学习中有一个理论:使用较大的模型去训练较少的数据,很容易导致过拟合。
但是知乎上有一个问题:为什么小模型已经可以很好地拟合数据集了,换大模型效果却要比小模型好?。下面有一位大佬是这样回答的:一个neural network在刚初始化时候是很随机和“健康”的,这里随机很好理解,“健康”是指如果我们看每个layer等价的weight matrix,那它里边特征值都是绝对值不大的非0值,没有特别不自然的结构,主要是指包含少数很大的或者含很多为0的特征值。这些特征值的存在,会导致NN在某些输入时,输出衰退为0或者特别大的值。这种初始状态我把它叫做“野蛮健康”状态。
如果一个NN的capacity很大,那它train的时候,只需要偏离这个野蛮健康状态一点点就可以fit了。这样,在test data上也不会有什么奇怪的behavior。
相反,如果NN的capacity比较小,它train的时候,为了fit数据里比较杂乱的长尾部分,就需要使劲拉伸,远离野蛮健康状态,结果是虽然fit了training data,但weight matrix已经有些不健康和overfit的结构了,所以在test data上表现更差。这种情况,可以通过加强regularization来减轻,比如增大weight decay或者用dropout。当然可能用了之后仍然比大的NN效果差些。
打个比方,比如让成年人和小朋友去搬5kg的箱子。成年人的身体只需要稍微变形就可以拿着箱子走很长距离。但小朋友就需要使出吃奶的力气,身体变形的厉害,搬的时候容易失去平衡,也不能走很远。
这是两个截然相反的答案,我个人觉得要是实践中去验证,不一定谁是对的:
- 如果模型在验证集上的loss出现了先下降后上升的趋势,则是过拟合了(模型拟合训练样本太好了,导致在验证集上loss出现了上升)
- 若验证集上的loss一直没有出现上升的趋势,但是一直处于较高的值不动,则是欠拟合状态。另外,需要注意的是,此时即使模型在训练集上准确率达到了百分之百,也是欠拟合状态。比如说猫狗羊三分类任务,某一个样本的真实类标为猫,较小的模型预测出该样本属于猫的概率为0.5,而较大的模型预测出该样本属于猫的概率为0.9,所以虽然小模型和大模型的准确率一致,但是显然大模型预测的更准确、更可信一点。
模型选择
在选取模型的时候,要采取的方案是:关闭所有的数据增强,关闭所有的trick,在相同的数据集上跑所有的基础模型,挑一个在测试集上最好的模型。
首先,对所有网络均进行最基本的修改:将最后一层全连接层去掉,并改为输出尺寸为54的全连接层(官方数据集一共54类);在所有特征层后面加上一层全局平均池化层,以适应不同网络大小的输出。
接着经过我们的测试,各个主要模型的性能如下:
- densenet201:0.959
- se_renext101_32x4d:0.968
- efficientnet-b5:0.959
- resnext101_32x16d_wsl:0.965
显然易见,se_renext101_32x4d效果是最好的,所以我们选择了该模型作为baseline,在这个模型的基础上加Trick。
efficientnet-b5我们也尝试过将所有bn层替换为gn层以解决batch size过小的问题(batch size为16),但是并没有什么用,本地验证集分数从0.987降低到0.983。
训练方法
确定好模型之后,我们采取了好几种训练策略,具体如下:
策略一:华为比赛出现的主要问题是美食大类区分的不是很明显,设计了新的分类架构,具体而言,包含如下几个步骤:
- 网络的输入类标维度为5(5个大类)+54(54个小类),将54个小类按照所属5个大类划分为5个大块,每一块的值均从0开始编码
- 网络的输出维度为5(5个大类)+54(54个小类)
- 计算损失时,将网络输出维度中的前5个和正确大类类标求交叉熵损失,作为损失的第一部分(要求其一定要分对)。根据正确大类类标找到对应小块的输出与对应的真实小块输出求交叉熵类别平滑损失,作为损失的第二部分(加强网络的鲁棒性)。将这两部分损失加到一块作为最终总损失。
- 前向推理时,采用p(小类)=p(小类|大类) * p(大类)的方式进行计算,也就是如果大类分错了,那么整体就会预测错了。如果大类预测对了,小类的预测结果才起作用。
这样的结果也不是很好,考虑可能是这样的原因:
- 对于大类的分类精度要求很高
- 现在模型并不是将一个大类的数据预测成另外一个大类,而是小类之间预测不是很准。而这种方法针对经常将一个大类预测成另外一个大类的情况比较有效,对于小类之前的区分并没有帮助
策略二:单尺度单阶段加大image size训练,一开始我们使用的image size为256x256,后来将image size提升到320x320的时候,测试集最高分数可以从0.967提升到0.978。但是这种方法存在的问题在于网络性能不稳定,在测试集上分数波动比较大。
策略三:多尺度多阶段加大image size训练,具体方案为:在256x256的image size上进行预训练,然后提升image size到416x416进行微调,这种方法也能将测试集的分数提升到0.978,但是问题在于不好训练,微调多少epoch,微调时学习率为多少合适都是需要去不断尝试的。
策略四:多尺度单阶段训练,这个思想主要来自Yolo-v2的论文,具体策略如下:

考虑到batch size对于BN层的重要性,较大的image size无法使用很大的batch size,所以我们多尺度的image size设置为[256, 256], [288, 288], [320, 320], [352, 352], [384, 384], [416, 416],每间隔10个iterations就从中挑选一个image size接着训练。而在验证集以及测试集的image size我们选择了416。
这种策略训练出的网络鲁棒性较强,在测试集上的分数也比较稳定,所以我们主要采用了这种训练策略。
策略五:这个策略是总结这篇文章时看到的,感觉应该效果不错,之后做比赛的时候可以参考使用:使用训练好的模型去检测没有训练的部分,挑选出分类失败的图片并加入之前的训练集再次进行训练。
另外,因为我们验证集并没有什么代表性,具体体现在本地验证集准确率最高可以达到0.99,但是在官方测试数据集上正确率只有0.972。为了解决这个问题,我们尝试了如下方案:输入不同image size的验证集,对其准确率进行打分并平均,保存在验证集上最优模型。经过该方案后,本地验证集正确率为0.981时,官方测试集的准确率为0.978,但是因为最后时间原因,我们该方案并没经过详细调参。
超参数
超参数主要包含batch size、epoch、lr(学习率)、权重衰减和dropout、学习率衰减策略、优化器等,下面对这些参数的选取一一进行说明:
batch size:较大的batch size对于BN层参数学习有很大的作用,而很大的batch size比较容易导致过拟合,经过我们的测试,最终选择batch size为48(当batch size=24,效果不是很好;当batch size=72,在测试集的分数反而下降了)。
epoch:建议epoch的值偏大一点,例如80或者100,使模型经过充分训练;我们一开始就只训练了30个epoch,在测试集的分数不稳定,大多数分数都在0.972左右,而设置epoch=100时,分数均在0.977左右。
lr:通常来说SGD的学习率要比Adam的学习率大,关于这个的选取可以参考我的另外一篇博客——如何挑选合适学习率,也可以参考经验值:Adam初始学习率选择3e-4,而SGD初始学习率选择1e-2。
另外,还有一个小trick,当比赛数据集分布和ImageNet数据集分布很接近时,特征提取部分的学习率可以设置为分类器部分的十分之一,可以极大的加快收敛速度。但是对于比赛数据集分布和ImageNet数据集分布相差很大时,这个trick就不一定work了。
权重衰减和dropout:参加这几次比赛均觉得权重衰减和dropout没有什么用,个人感觉解决过拟合的手段最有效的是数据增强。建议一开始训练时将这两个参数关闭,观察验证集损失曲线,看是否过拟合了。如果过拟合了再考虑开启这两个参数。
学习率衰减策略:我这里选择的Pytorch中的
ReduceLROnPlateau,参数如下:1
lr_scheduler.ReduceLROnPlateau(optimizer, mode='max', factor=0.7, patience=3, verbose=True)
这种学习率衰减方式就是监控验证集的准确率,当3个epoch准确率均不上升时,学习率就乘上0.7。个人感觉这种学习率衰减方式比较合理并且比较好用。
我的小伙伴也使用了余弦衰减的方式,也挺好用的,之前几个比赛我们都是用的这种学习率衰减策略。
而对于WarmUp类型的学习率衰减方式,一直不是很好用;关于论文中常用的Step类型的学习率衰减方式,也挺好用的,但是在哪个epoch衰减不太好调节。
优化器:常用的优化器基本就是Adam和SGD with monmentum 。一般来说Adam的性能更加稳定,而SGD with monmentum调节较好的话,性能会更好。因为比赛时间较短的原因,我们这里选择了Adam优化器。
损失函数
我们尝试过的损失函数主要包含了
CrossEntropy
SmoothCrossEntropy
- FocalLoss
- Class-balanced Sigmoid
- Class-balanced Focal
- Class-balanced Softmax
- Class-balanced SmoothCrossEntropy
其中,关于SmoothCrossEntropy机制的分析,可以看这篇Paper——《When Does Label Smoothing Help?》,而关于四个Class-balanced的损失,可以看这篇Paper——《Class-balanced loss based on effective number of samples》。具体原理我这里就不赘述了。
当时,最有效果的损失函数为SmoothCrossEntropy。四个Class-balanced的损失不是很好,可能是跟我们的数据类别数量分布不满足长尾分布,而这些损失都是针对满足长尾分布的数据集而言的。FocalLoss损失我参加的几次比赛效果都不是很好,具体原因还有待分析。
失败原因分析
本次比赛最终以32名(Top4%)的成绩结束了,不是很理想,离晋级决赛差了0.003的分数(晋级需要0.982而我们最高分为0.979),测试集一共有1000张样本,也就是就差了3张图片。分析这次比赛的失败原因,主要有以下几个方面:
- 没有整体的规划,没有对比赛的整体流程进行规划,每天都在瞎调参,这其实是一个比较有具体技巧的过程。
- 对验证集的划分没有很深刻的理解,导致本地验证集不具有代表性。
- 分析结果的能力不足,即使在验证集进行了Demo,保存了所有分错的样本,但是对于为什么会分错,如何避免分错,并不能道出所以然。
- 分析数据的能力不足,无法针对特定数据集的分布设计特定的网络以及训练策略。
经验
相比于之前参加比赛,本次的主要收获如下:
- 学会了如何扩充数据集并对数据集进行清洗
- 如何判断学习率过大还是多小,模型是过拟合了还是欠拟合了。关于这部分的讨论可以在这里找到。
总结这次比赛的失败教训,日后参加比赛时应该规范化流程,具体如下:
- 对数据集进行分析,划分验证集与训练集;如果类别严重不均衡,则采用分层交叉验证的方法。
- 在没有任何数据增强,没有任何trick的情况下,测试所有的基础模型,找到表现最好的模型作为之后的baseline
- 在该模型上调节最优参数:学习率、学习率衰减方式等,并观察是否出现过拟合现象。根据实际数据分布看需要添加什么样的数据增强方式
- 根据具体任务逐个添加trick,不好一次添加过多的trick,没有控制变量。
- 分析在验证集的表现,调整训练方案等
今天还跟另外一位0.981分数的大佬请教了一下他是怎么做的,他主要说了三点:
- 数据扩充,通过旋转、翻转、颜色变换等常见的方式将数据集扩充五到六倍
- 使用efficientnet-b7网络,即使batch size过小,但是仍然work
- 在训练集上训练后,冻结特征提取层,只训练全连接层,通过这个可以提升0.003。
对比他的方案,我感觉最主要的点在于efficientnet-b7网络性能更好,我们只试了efficientnet-b5,因为感觉batch size过小的话,BN层就不再work了。另外,关于他的数据扩充方式,之前我们参加另外一个图像分割比赛时也尝试了,效果不好,所以这次比赛也没有尝试。所以感觉自己已经陷入了思维定式,并没有发散思维,可能在别的任务不好的trick换个任务就work了。
最后:革命尚未成功,同志仍需努力~~~

