暑假基本上也没做什么事情,就和小伙伴一起参加了Kaggle SIIM-ACR Pneumothorax Segmentation Challenge 比赛。最终名次34th,top3%,银牌。第一次真正的参加Kaggle比赛,取得这个成绩感觉还可以。特来进行一番总结,毕竟学到了很多东西。不总结的话就忘了。
另外,这次比赛的源代码已经释放出来了,具体点这里。
任务介绍
这次比赛的主要任务是从胸部X光图片中判断图片是否含有气胸,如果含有的话分割出气胸。
比赛分为两个阶段,第一个阶段测试集数据有1372张,每天有5次提交机会,比赛时间较长,你可以根据第一阶段的测试集调整优化你的模型。在第一阶段结束之前,需要提交所用的代码,代码中包含两个模型(可以集成,这里两个模型的意思应该是产生两个submission)。注意提交完模型后,在第二阶段你不能再更改超参数以及阈值(自动化的阈值选取方法是允许的),但是可以更改路径以及重新训练。
比赛第二阶段测试集为3205张,并放出了第一阶段测试集对应的掩模,你可以使用这些掩模以及第一阶段的训练集用你所提交的代码重新训练。这时Public Leaderboard只采用了其中的1%的数据打分并排名,最终的Private Leaderboard采用了最后99%的数据打分并排名。所以第二阶段Public Leaderboard和Private Leaderboard最终差别很大,你不能根据第二阶段Public Leaderboard的得分来调整优化自己的模型(毕竟这也是比赛规则所不允许的)。
难点
- 图像尺寸较大
- 无气胸的样本较多
数据集
这次比赛所采用的数据集为胸部X光图片,训练集数目为10675张,第一个阶段测试集数据有1372张。
数据集以dicom的格式给出,该格式包含了病人的姓名、id、年龄、性别、Modality、BodyPartExamined、ViewPosition以及X光数据信息,我们需要使用代码将其中的X光数据提取出来,并保存成jpg(有损压缩,可能会丢失部分信息)或者png格式。
掩模数据以CSV格式的文件给出,每行数据以ImageId,EncodedPixels给出,我们需要使用代码将EncodedPixels转化为图片形式,其中像素点为0的地方表示没有气胸,像素点为255的地方表示有气胸,若一张图片像素点全部为0,则表示该图片没有气胸。
值得注意的是,并不是所有的图片都对应一个掩模,因为有些病人是没有气胸的,所以相应的也就没有掩模了。因此,这次比赛要判断是否含有气胸,如果含有的话分割出气胸。
数据分析
深度学习模型结合特定数据集才有意义,尤其是对于Kaggle比赛,模型基本大家用的一致,谁对数据分析的彻底,更有机会获得更好的名次。这个Kernel有别人分析的结果,感觉分析的挺好的。先直接拿来用以下,下面是该数据集中数据以及掩模的两个实例:


下面是我们自己的一些分析。
训练集10675张图片中,有气胸和无气胸的比例为$2379:8296=1:3.48$;所有掩模中有气胸的像素点之和与无气胸的像素点之和比例为$1:327$;只取所有含气胸的掩模,其中有气胸的像素点之和与无气胸的像素点之和比例为$1:72$,从中可以看出这是一个类别不平衡问题。
对所有有气胸的掩模的分布进行统计,可以得到下图。下图中的第一张图横坐标为掩模中气胸像素点个数,纵坐标为掩模个数。例如,蓝色箭头显示为min:55, number:1表示所有有气胸的掩模中,最小的气胸像素点个数为55,数量为1张。下面第二张图为第一张图的累加图。从这两张图中可以看出大部分掩模的气胸像素点个数都分布在$0:40000$之间。
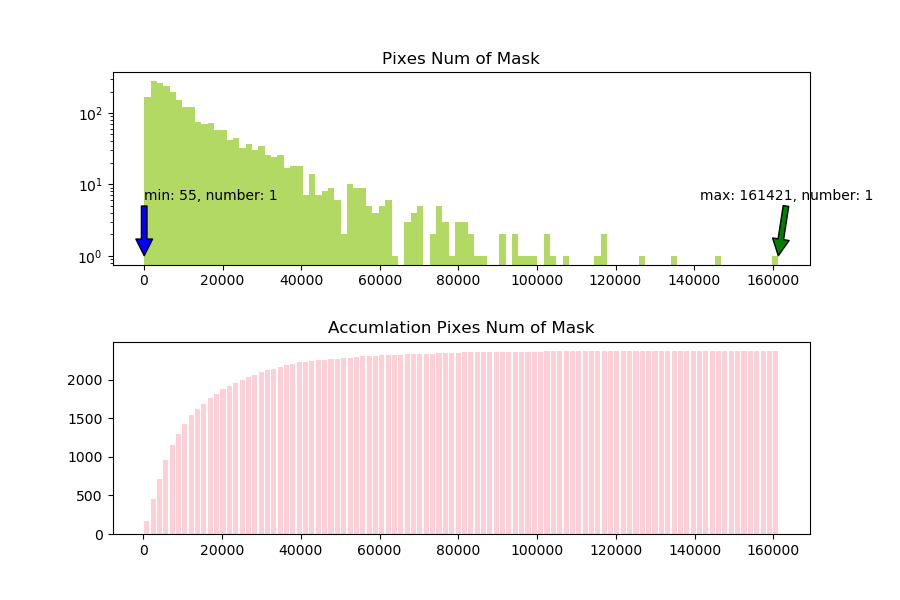
分析完数据之后,我们如下几个结论,可以在下面中使用到:
- 这是一个类别不平衡问题,有气胸和无气胸的比例为$2379:8296=1: 3.48$;
- 对于有气胸的掩模,其气胸像素总数分布也是不平衡的,从0到160000不等,但是绝大多数都落在$0:40000$之间;其中落在$0:2048$之间的为248张。
数据预处理
在论文U-Net: Convolutional Networks for Biomedical Image Segmentation中,强调了数据预处理的重要性。深度学习模型是由数据驱动的,好的数据预处理能够让模型学习到更好的分布,进而增强模型的泛化能力。参加Kaggle之后才发现有一个特别厉害的数据增强库,使用起来简直不要太爽。另外,我们在之前的数字图像处理基础文章中已经介绍了数字信号处理的一些基本概念和知识,这里不再赘述。
数据增强
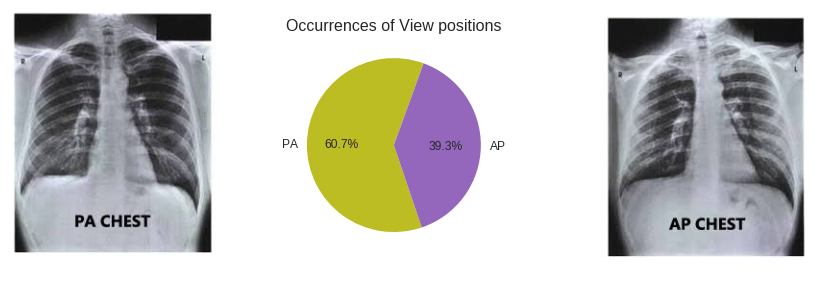
在该数据集中,有两种拍摄视图:
- PA: passes from posterior of the body to anterior —> getting better anterior shadings
- AP: passes from anterior of the body to posterior —> getting better posterior shaginds
两者的示意图及其比例如下所示,可以看到两者比例基本为$PA:AP=6:4$。因此我们使用了随机水平翻转,概率为0.4。
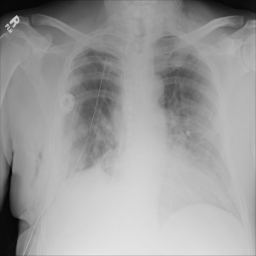
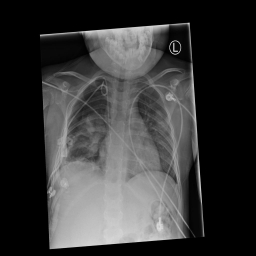
同时观察上面的数据集,相比与第一张图片,第二张图片是有一些倾斜的,但倾斜的角度不是很大。观察整个数据集后我们得到结论,数据集中存在着部分倾斜的图片,数量不是很多,同时角度基本都在15°之内,因此我们使用了随机旋转操作,旋转角度在0到15°之间,概率为0.4。
如下面第一张图所示,可以看到相比于上面两幅图像,该图像对比度有点低,可能不利用网络找到有用的信息,我们使用了随机gamma变换,概率为0.1,随机亮度对比度变化,概率为0.1以及限制对比度的自适应直方图均衡(CLAHE),概率为0.4;如下面第二张图,该图并不像所有的图占满了整张图,所以我们使用了先随机裁剪,在resize会之前尺寸的变换,概率为0.4。
最后,为了防止模型过拟合,我们以较小的概率对数据增加噪声。
除了这种在线数据增强的方法外,我们还尝试了离线数据增强,也就是数据扩充。这样样本规模扩大了若干倍,在训练集上的表现确实更好了,但是在验证集和测试集表现都很差,也就是出现了过拟合问题。不管我们怎么添加正则化,或者说只在前几个epoch做数据扩充,后面的都不做数据扩充,然而还是不work。所以最终放弃了数据扩充这种策略。实际上,这种策略确实不提倡,因为很容易过拟合。
标准化
数据增强之后,理所当然的需要对数据进行标准化处理,因为我们采用了imagenet的预训练权重,所以使用了imagenet的均值和方差。Kaggle上一名大佬说虽然这个数据集的分布与imagenet数据集的分布差别较大,但是有很多的卷积核尤其是浅层的卷积核提取的是与类别无关的特征,例如边缘、纹理信息等。经过实际测试,使用imagenet的均值和方差确实比使用自身的均值、方差效果好。
数据划分
基础知识
Kaggle比赛都是只给训练集以及测试集的,需要自己去划分验证集。在参加Kaggle比赛之前,我觉得验证集只是能让我们评估模型的泛化能力,进而调节超参数。但是参加完这个比赛,我意识到验证集其实用处很大。比如:
- 选阈值:对于图像二分类问题,最后一层通常使用sigmoid函数将输出限制到
[0, 1]。我们需要有一个阈值来划分是否为正样本,若没有验证集我们只能取一个经验值例如0.5。但是有了验证集之后,我们可以采取线性搜索的方法搜索出来在验证集上表现最好的阈值。这个阈值通常比经验阈值要好。 - 评估模型泛化能力:训练阶段,可以观察在训练集、验证集上的loss、acc曲线(在本次任务中为dice曲线),分析我们模型表现情况,判断我们模型的泛化能力,是过拟合了还是欠拟合了,进而调节网络学习率、权重衰减等超参数。
- 保留最优权重:在训练阶段,可以保留在验证集上表现最好的权重,在测试集上预测的时候使用最优权重。
划分验证集的方法也有好几种方法:
- 留出法:直接将整个数据集D划分为三个互斥的集合作为训练集、验证集、测试集。在数据集很大的时候可以直接采取这种方法。对于我们这个任务,直接采用留出法会造成大量数据浪费。导致模型并没有看到所有的数据分布,进而影响模型的泛化能力。
- 交叉验证:数据集D划分为$k$个大小相似的互斥子集。每个子集都尽可能保持数据分布的一致性,例如可以从D中通过分层采样得到。每次用$k-1$个子集的并集作为训练集,剩下的那一个子集用作测试集;这样可以获得$k$组划分,进行$k$次训练和测试,最后返回$k$个评估结果的均值。因此k的取值很重要,所以通常将交叉验证法称为$k$折交叉验证(k-fold cross validation)。
- 留出法+交叉验证:将整个数据划分为训练集、验证集两个部分,在训练集上进行$K$折交叉验证。交叉验证得到的$K$个模型可以在留出的验证集上验证模型,有了一个统一的数据集衡量性能,其次我们可以根据不同折在留出验证集上的表现进行评分,做集成的时候进行加权。
对数据集的采样方法也分为两种算法:
- 随机采样:例如有100张图片,采用留出法按照8:2的比例划分训练集、验证集的时候。随机选出20张图片分配到验证集,剩余的分到训练集。
- 分层采样:对于类别不均衡问题,采用随机采样的方法会导致各个折的类别与整体类别比例不一致,这样的数据划分过程引入额外的偏差。为了尽可能保持数据分布的一致性,可以采用分层采样的方法。例如100张图片中有20张为正样本,80张为负样本。采用留出法按照8:2的比例划分训练集、验证集的时候。随机选出4张正样本和16张负样本作为验证集,剩余样本作为训练集。当然,若正样本之间、负样本之间差别也比较大,可以分更多层。
我们的方案
该数据集的训练集规模并不是很大,只有10675张,并且数据分布差异较大,直接采用留出法的方法不合理,而且采用留出法一个模型只能训练出一个权重,是无法做集成的。所以我们这里采用了交叉验证的方案,折数较多的时候验证集规模较小,不利于评估模型泛化能力,也不利于选阈值,同时训练成本很高。交叉验证折数较少的时候,数据利用率不够。最终我们选了一个折中点:五折交叉验证。
至于为什么不适用留出法+交叉验证,是因为我们知道这种方法的用途较晚,并且这种方法做集成效果较好。但是我们做集成的时间较晚,导致最终我们没有对这种划分方法进行尝试。
该数据集中有气胸和无气胸的比例大概为$1: 3.48$。若是直接使用普通的交叉验证方法将数据集划分为五折,各个折之间的数据差别比较大,最后会造成不同折之间模型性能差别较大。为了解决这个问题,我们采用了分层采样的方式,使得各个折中训练集以及验证集中气胸和无气胸的比例也大概为$1: 3.48$。
因为有气胸图片中气胸像素总数分布也不均衡,我们也尝试过更多层的采样方式,使得各个数据集子集有气胸图片的气胸像素总数也分布一致,但是效果不好。原因有可能是一:该数据集有气胸图片中气胸像素总数分布极其不均衡,导致分层难度较大,我们分的不是很好,二:比赛方在划分测试集、训练集的时候,只是按照是否有气胸进行划分,所以训练集的气胸像素总数分布并不和测试集的一致。
Model
对于图像分割任务,有很多特别好的模型,可以在这里看到不同模型在PASCAL VOC 2012数据集上的表现对比。目前表现最好的是DeepLabV3+。医疗图像与普通的图像有很大的区别,目前大家都是采用UNet网络作为基准,在上面进行改进。
我们采用的模型来自于segmentation_models.pytorch。这是一个大牛写的支持UNet、LinkNet、PSPNet以及FPN模型的仓库,其中backbone可以选择很多预训练模型,例如Resnet、VGG等。
Unet网络在被提出后,就大范围地用于医学图像的分割,成为大多做医疗影像语义分割任务的baseline。我们是第一次做医疗图像分割,理所当然的选择了Unet。从理论上分析,Unet之所以在医学图像上有很大影响力。必然有其成功的一面。
以VGG11作为encoder部分,Unet结构如下所示(原始Unet结构输入和输出图像大小不同,而现在大多数Unet基本都采用的是下面输入和输出图像大小一致的结构)。Unet有两个最大的特点:U型结构和skip-connection。
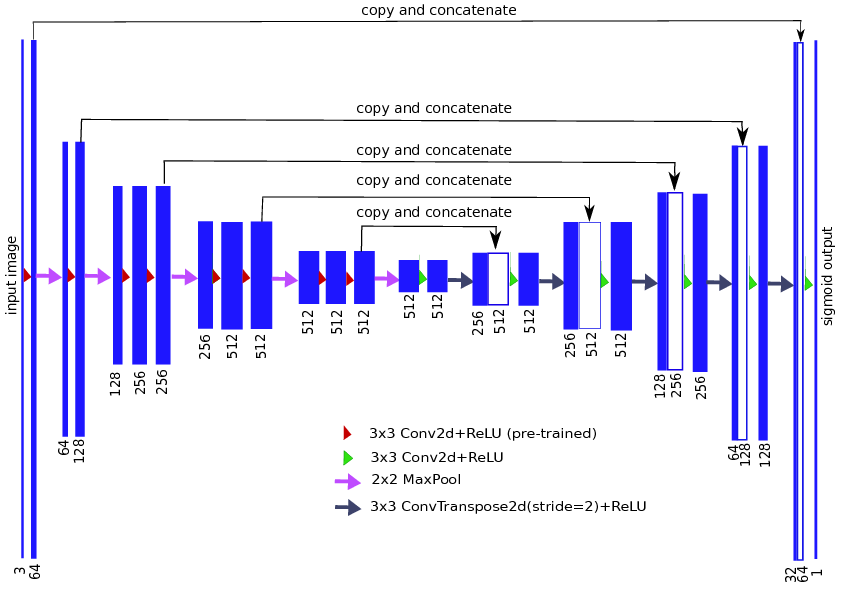
所谓的U结构,个人觉得就是encoder-decoder结构。在该UNet中,encoder部分下采样5次,共下采样32倍,该部分的作用为提取图像的高层语义特征;对称地,其decoder也相应上采样5次,将encoder得到的高级语义特征图进行恢复,得到原图片的分辨率。总结来说,这种U结构有如下几个优点:
- encoder部分负责提取图像的高层语义特征,有助于对图像精准分割
- decoder部分复杂将提取出的高层语义特征还原,得到原图片的分辨率
- 这种encoder-decoder结构被广泛应用于图像分割任务,这是因为在该任务中最后输出的尺寸和输入大多数情况下要一致。若每一层的维度都和输入图像维度相同,模型复杂度太高。采用encoder这种结构,逐步减少特征分辨率,并逐步增加特征通道数,一方面可以减少模型参数量,二来可以增大卷积核的感受视野,提取更加复杂的结构特征。另外,decoder结构逐渐的从较小分辨率的特征图中恢复信息,相比于直接从较小分辨率还原到输入尺寸,可以还原更加精细的特征。
相比于Segnet等encoder-decoder结构,Unet在同一个stage使用了skip connection,而不是直接在高级语义特征上利用loss反传监督训练,这样做的好处为:
- 最后恢复出来的high-level特征图中融合了更多的low-level的feature,high-level可以从low-level中补充底层细节信息
- 使得不同scale的feature得到了的融合,从而可以进行多尺度预测
- skip connection形成了多通路模型,使得信息流从输入到输出畅通无阻,梯度信息也就可以直接从loss function直接反馈回网络的各个节点,这也可以称为一种广义上的DeepSupervision。如上图第一层使用skip connection连接到最后一层,反向传播过程中该层的loss来自两个通道,一个是loss经过所有层,层层传播回来的loss,另一个是输出层通过skip connection传过来的loss。论文The Importance of Skip Connections in Biomedical Image Segmentation提到这虽然不能减轻梯度爆炸或梯度消失,但是可以使得收敛速度更快,并且允许训练更深层的网络
其次,医疗影像有什么样的特点呢(尤其是相对于自然影像而言)?
- 图像语义较为简单、结构较为固定。我们做脑的,就用脑CT和脑MRI,做胸片的只用胸片CT,做眼底的只用眼底OCT,都是一个固定的器官的成像,而不是全身的。由于器官本身结构固定和语义信息没有特别丰富,所以低阶信息很重要,它能够提供物体类别识别依据;另外一方面医学图像边界模糊、梯度复杂,需要较多的高分辨率信息,能用于精准分割。所以高级语义信息和低级特征都显得很重要(UNet的skip connection和U型结构就派上了用场)。
- 数据量少。医学影像的数据获取相对难一些,所以我们设计的模型不宜多大,参数过多,很容易导致过拟合。 原始UNet的参数量在28M左右(上采样带转置卷积的UNet参数量在31M左右),而如果把channel数成倍缩小,模型可以更小。缩小两倍后,UNet参数量在7.75M。缩小四倍,可以把模型参数量缩小至2M以内,非常轻量。个人尝试过使用Deeplab v3+等自然图像语义分割的SOTA网络用在该数据集上,发现效果和UNet相差甚远,并且参数量会大很多。
encoder
模型encoder部分,选取Resnet34作为backbone,采用ImageNet的预训练权重。
之所以选择Resnet,是因为该模型相比VGG等模型,性能好且参数量少。而选择Resnet34,是因为这个数据集的图片尺寸为1024x1024,若采用更复杂一点的模型如Resnet50,受限于显存大小会导致batchsize很小,模型中batchnorm层无法起到应有的作用;若采用Resnet18,模型参数量虽然很小,batchsize也随着增大了,但是模型性能不足。平衡batchsize大小以及模型的能力,我们选择了Resnet34作为backbone。
最近看前面获得金牌的大牛分享的经验,他们大多采用了resnext50_32x4d、resnet50等更加复杂的backbone,并没有使用resnet34这样的简单backbone。为了解决batchsize过小,BN层不work的问题,他们大多采用了group norm。
decoder
模型decoder部分并没有采用反卷积,而是采用了上采样插值的算法。
该部分常用的有三种算法,UnPooling、UnSampling以及DeConvolution。这三种算法的具体区别如下图所示:
图(a)为UnPooling算法,是在CNN中常用的来表示max pooling的逆操作。这是从2013年纽约大学Matthew D. Zeiler和Rob Fergus发表的《Visualizing and Understanding Convolutional Networks》中产生的idea:
鉴于max pooling不可逆,因此使用近似的方式来反转得到max pooling操作之前的原始情况
简单来说,记住做max pooling的时候的最大item的位置,比如一个3x3的矩阵,max pooling的size为2x2,stride为1;UnPooling时将每个值还原到其最大item的位置,其余位置为0就行,如下图所示:
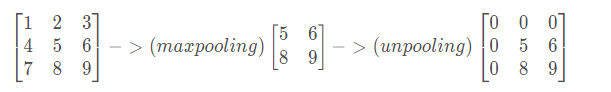
从这种操作来看,不需要引入额外的训练参数。但是因为涉及到补零操作,所以会导致其细节信息还原不足,分割结果细节信息不足。
图(b)为UnSampling(上采样)算法,简单来说:上采样指的是任何可以让你的图像变成更高分辨率的技术。
最简单的方式是图中所示的重采样。它没有使用MaxPooling时的位置信息,而是直接将内容复制来扩充Feature Map。这种方式会导致图像过于锐化,图像平滑性不好。
现在常用的方法为插值:将输入图片进行rescale到一个想要的尺寸,而且计算每个点的像素点,使用如双线性插值等插值方法对其余点进行插值来完成上采样过程。
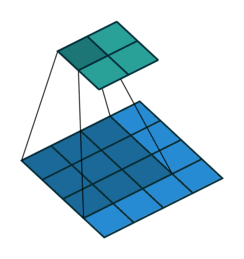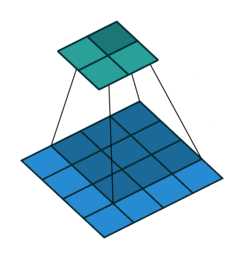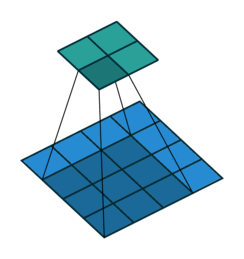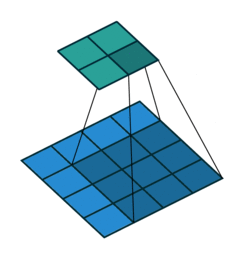
图(c)为Deconvolution,与上面两种方式不同,使用反卷积来对图像进行还原是可以训练出来的。通常用来对卷积层的结果进行Deconvolution,使其回到原始图片的分辨率。从conv_arithmetic可以观察到卷积和反卷积的区别。
如下图所示,第一张图为卷积操作,下面是蓝色的是输入,上面绿色的是输出;第二张图为Deconvolution,下面蓝色的为输入,而上面绿色的为输出。可以看到Deconvolution也算一种卷积的操作,只不过进行了padding操作,所以反卷积核的训练方式和卷积核训练方式一致。当然,可以选择更大的dilation(等价于小于1的stride)来增强上采样的效果,可以理解成分数步长卷积,如下面第三张图所示,$stride=1/2$的示意图。
![]()
![]()
值得注意的是,分数步长卷积和Dilated convolution是不一样的,后者是对卷积核进行补零,只是为了增加卷积核的感受视野,并不能起到上采样的效果。如下图所示:
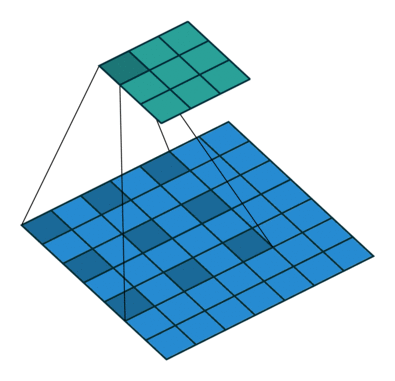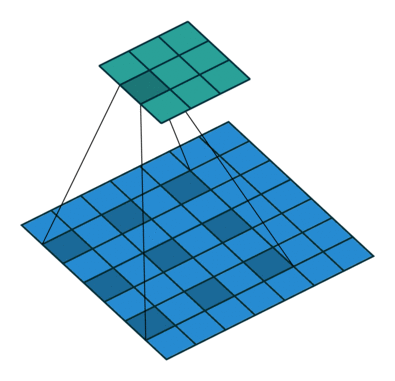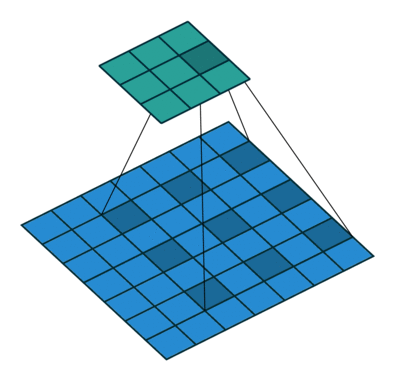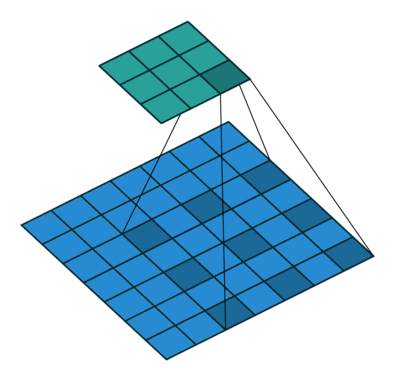
至于采用插值的UnSampling(上采样)算法,还是采用Deconvolution算法。要视具体情况而定,前者没有可训练的参数,无论是前向传播还是反向传播速度都会很快;后者理论上通过引入可训练的参数让神经网络自己学习到适合本身的”上采样“方法,但是若是训练不好,会起到反方面作用。
而在我们这次比赛中,对于两个算法均实验了,发现差别不是很大,所以决定采用参数更少的基于插值的UnSampling(上采样)算法。
除此之外,我的小伙伴(github地址)也试验了octave convolution,效果也不好。至于什么是octave convolution,我并没有了解,所以这里不叙述了。
How to Train Model
该数据集的图像尺寸为1024x1024,对于图像分割任务属于比较大的尺寸。对于该模型的训练策略我们分为三个阶段。
因为该比赛也分为两个阶段,为了防止名称混淆。我们称这里为模型的三个阶段。
模型的第一阶段,在768x768的图像分辨率进行训练较多的epoch,让Unet模型初步学习该数据集的分布。并且在图像分辨率较小的时候,卷积核的感受视野相对来说变大了,更容易提取图像像素之间的结构信息。
模型的第二阶段,在1024x1024的图像分辨率上进行fine-tuning,训练较少的epoch,该阶段使用较高的分辨率使Unet网络学习到更多的图像分布细节信息。
比赛的前期我们模型由这两个阶段组成,模型在1024x1024的分辨率上训练完之后,进行阈值选取(至于怎么选取阈值,在下文有详细介绍),最后在测试集上进行测试。但是经过对模型在验证集上的表现进行可视化,发现对于不含气胸的数据,预测结果也没有气胸;而有气胸的图片不一定能检测出有气胸,并且就算检测出有气胸了,细节信息也不好。因此我们想能不能接着第二阶段的权重只对有气胸的数据进行fine-tuning,无气胸的数据舍弃掉。这样我们就可以拿前两个阶段作为分类模型,第三阶段作为分割模型,使得分割出的结果细节更加完善。所以才有了下面第三阶段。
模型的第三阶段,在1024x1024的图像分辨率上只对有气胸的数据集进行fine-tuning,训练较少的epoch,该阶段让模型学习如何更好的分割出气胸部分。
这里有一个重要的点,在上述模型的第二和第三阶段开始前,要把优化器重新初始化。这是因为若不初始化,优化器中包含了一些中间变量,例如冲量等。不同阶段的数据集已经改变了,之前优化器的中间变量可能已经不适合新的数据集分布了。
在这里提一个小建议,要及时的对模型的训练结果进行可视化,并且不要在训练集,要在验证集上进行可视化,对比其真实标签与预测标签之间的区别。我们正是因为对结果可视化部分做的不好,所以第三阶段的提出时间较晚,错过了很多机会。
除了这些,我们也尝试了以下几种训练方案:
- 第一阶段在512x512的分辨率上进行训练,第二阶段不变,无第三阶段,在测试集上的分数只有0.85左右。而若第一阶段在768x768的分辨率上进行训练,第二阶段不变,无第三阶段,在测试集上的分数能够达到0.8691。这是因为768x768的分辨率蕴含着更多的细节信息,同时batch size不会太小,导致batchnorm层不Work。所以得到结论,大的分辨率matters a lot。
- 只在768x768的分辨率上进行训练,即没有第二阶段和第三阶段,发现网络分割细节特别不好。猜测是输入图像从1024x1024 resize 到768x768的时候,损失了一部分有用的信息。
- 只在1024x1024的分辨率上进行训练,发现效果也不好。猜测原因是,一方面:当图像分辨率较大时,同样的卷积核感受视野相对变小,网络无法提取到较好的结构信息;另一方面,当图像分辨率较大时,Batchnorm层无法起到应有的作用。
- 模型的第一阶段及第二阶段不变,改变模型的第三阶段。具体策略为:不从上面的第二阶段开始fine-tuning,而是将上面的第一阶段和第二阶段的训练集改为有气胸的数据集,无气胸的样本去掉,然后第三阶段再fine-tuning,但是结果也不好。猜测是因为有气胸数据的分布和无气胸的分布是很接近的,而这三个阶段训练数据集都过少,模型无法很好的学习到数据的分布。而上面的第二阶段可以从大量的数据集中学习到了数据的分布,第三阶段只需要fine-tuing微调即可。
- 模型第一阶段前三个epoch,冻结模型的encoder部分。效果不好,猜测是因为我们数据集的分布和Imagenet数据集的分布相差较大缘故。
- 模型encoder部分和decoder部分采用不同的学习率。效果不好,猜测也是因为我们数据集的分布和Imagenet数据集的分布相差较大缘故。
- 模型第二阶段最后几个epoch进行梯度累加,发现没有效果。Kaggle Discussion中有一位大佬说是因为梯度累加无法解决batchsize过小的问题,因为均值和方差均在前向传播的过程中计算,而只有可训练的两个参数是在梯度累加之后反向传播更新的。另外一位Kaggle大佬也说道,梯度累加能帮你得到更好的梯度,允许你使用更高的学习率,但是无法解决batch size过小的问题。
损失函数
在我们之前的图像分割损失函数部分,已经详细的介绍了图像分割中常用的损失函数,具体原理这里就不再赘述。我们这里模型的三个阶段均采用的是Bce+Dice损失函数组合的形式。具体而言:
- Bce采用的是Weighted Binary cross entropy,正样本的加权系数为0.75,负样本的加权系数为1。
- Dice采用的SoftDICELoss,正样本的加权系数为0.75,负样本的加权系数为0.25。
- Bce损失直接与Dice损失相加 ,并没有加权。
注意,这里所谓的正负样本即对于每一张图像,气胸部分对应的像素点即为正样本,非气胸部分对应的像素点即为负样本。
在比赛的初期,我们采用的是Pure Bce损失函数,其实它对于网络是work的,但是当看到some workable loss function这个帖子的时候,就像去实验一下,发现采用大佬的默认系数效果相比与Pure Bce提升了很多。
顿时感觉不可思议,因为根据前面的数据分析,所有掩模中有气胸的像素点之和与无气胸的像素点之和比例为$1:327$,按照Pytorch bcewithlogitsloss 官方文档,此时正样本的系数应该是327,最起码要大于1,但是这里为0.75。但是当我把Weighted Binary cross entropy中正样本的系数改为327或者50时,效果都很差。分析可能有以下几个原因:
- 在Pytorch bcewithlogitsloss 官方文档中说当正样本系数小于1的时候,可以增加准确率;当正样本系数大于1的时候,可以增加召回率。而当召回率高的时候,必然伴随着准确率的降低。无论是召回率还是准确率均会影响到最后的dice,我们就是要调节bcewithlogitsloss的正样本系数,使得dice最高,而对于我们模型而言,恰好在正样本系数为0.75的时候,dice取得最大值。若继续减少正样本的系数至0.6或者0.7,效果并不如系数为0.75的时候。当训练完我们的模型的时候,发现模型就是倾向于少预测并且预测结果基本都对,也就是召回率较低而准确率较高。
- Pytorch bcewithlogitsloss 官方文档解决的是一般的样本不均衡问题——在训练阶段各类样本数目不均衡,但是测试阶段各类样本出现的概率基本一致。但是我们这里不仅训练阶段样本不均衡,且测试阶段样本也是不均衡的,若正样本的权重系数过大,则会出现过度矫正的问题。
另外,我们还尝试了一些别的loss,例如:
- 只使用Weighted Binary cross entropy,去掉SoftDICELoss,效果会下降,甚至不如Pure BCE。
- 考虑到数据集类别不平衡,采用facal loss,效果不好。
- 在Kaggle上,有大佬说 lovasz loss 适合做fine-tuning,我们在模型的第二阶段采用该损失函数,发现其在验证集的表现确实更好了,但是在测试集上的表现反而有所下降。
超参数
超参数也就是我们可以人工调节的参数,例如Batch size,epoch,优化器,学习率,权重衰减系数等。在参加Kaggle之前,我并没有意识到超参数的重要性,一般情况也不会观察训练曲线,进而调节超参数。当实验结果不行的时候,总是想着更改损失函数或者更改网络模型。
在之前的Kaggle比赛经验文章中的训练/验证曲线小节已经分析了如何使用训练集、测试集曲线去指导网络的超参数选取,这里就不再赘述。最终我们模型三个阶段均选取Adam优化器、不加任何权重衰减,不同点在于:
- 模型的第一阶段batch size为12,epoch为40,初始学习率为
2e-4,采用余弦退火衰减(设定在第40+10个epoch学习率到0) - 模型的第二阶段batch size为6,epoch为15,初始学习率为
5e-6,采用余弦退火衰减(设定在第15+5个epoch学习率到0) - 模型的第三阶段batch size为6,epoch为10,初始学习率为
1e-7,采用余弦退火衰减(设定在第10+5个epoch学习率到0)
选取Adam优化器,个人觉得这是经验吧,一写深度学习代码,一般都会采取Adam。正如有一个大牛说:“如果你不知道选什么优化器,那么就用Adam吧,效果不会很差。”我们后期也实验了最近发表的 RAdam 算法,但是效果并没有改善。
权重衰减主要是为了防止过拟合,我们每次在验证集上的dice都不高于提交的结果。所以不存在模型过拟合问题,因此也就没有加权重衰减。
各个阶段的batch size当然越大越好,毕竟其中包含batch norm层。(虽然batch size过大会导致模型过拟合,但是这里图像尺寸较大,所以不需要考虑这个问题)。
这样设置学习率的策略主要有以下几个支撑点:
- 因为模型后面两个阶段都是对前面阶段的fine-tuning,所以学习率应满足第一阶段 > 第二阶段 > 第三阶段。
- 模型的前期阶段学习率应该较大,一方面可以让模型不会陷入局部最优,另一方面也可以加快模型收敛速度。而模型后期要学习率不宜多大,较小的学习率一方面可以避免跳过最优解导致loss震荡,另一方面可以慢慢寻找到最优解。所以这里可以采取余弦退货衰减策略。但是学习率不宜衰减到0,所以我们让学习率在
epoch+N次迭代衰减到0。实验结果也证明,余弦退火策略对模型性能的有较大改善。 - 要多加实验,重点分析训练集以及验证集的loss、acc曲线,进而调大或者调小学习率。
至于为什么没有采取学习率重启策略,在各个阶段学习率都一直衰减,这个也是实验出来的。个人觉得没有什么理论支撑,视具体模型以及具体数据集而定。
epoch的选取主要参考了kaggle大佬的分享。初期我们觉得模型第一阶段可能epoch太少,因此我们设置了60个epoch,结果并不好还加长了训练时间。个人感觉如果模型第一阶段若epoch过多,可能会导致模型的可塑性差,之后进行fine-tuning效果不好。
阈值选取
因为这次比赛本质是一个二分类问题,二分类问题最后一层通常要经过sigmoid函数,将其归一化到[0,1],若是直接用0.5作为正负样本的分割点,效果可能不会很好。如何选取阈值也是这次比赛的一个重中之重。
阈值用途
在这次比赛中,我们主要有三个阈值。分别为:
- 模型第二阶段的正类和负类的分界点threshold_cla。高于阈值threshold_cla的为正样本,即该像素为气胸,低于阈值threshold_cla的为负样本,即该像素无气胸。
- 模型第二阶段的min_pneumothoraxr_sum。通过上面的阈值threshold_cla,我们可以判断出该图片中是否含有气胸。考虑到气胸通常是成块的,所以我们需要用一个阈值min_pneumothoraxr_sum,当预测出的掩模中气胸像素总数小于这个值的时候,认为我们模型误判了,则将该预测出的掩模所有像素值置为0,也就是置为无气胸;当预测出的掩模中气胸像素总数大于这个值的时候,认为我们模型判断对了,保持不变。
- 模型第三阶段正类和负类的分界点threshold_seg。高于阈值threshold_seg的为正样本,即该像素为气胸,低于阈值threshold_seg的为负样本,即该像素无气胸。
至于这三个阈值怎么用,也就是得到模型三个阶段的训练权重后,如何对图片进行测试。
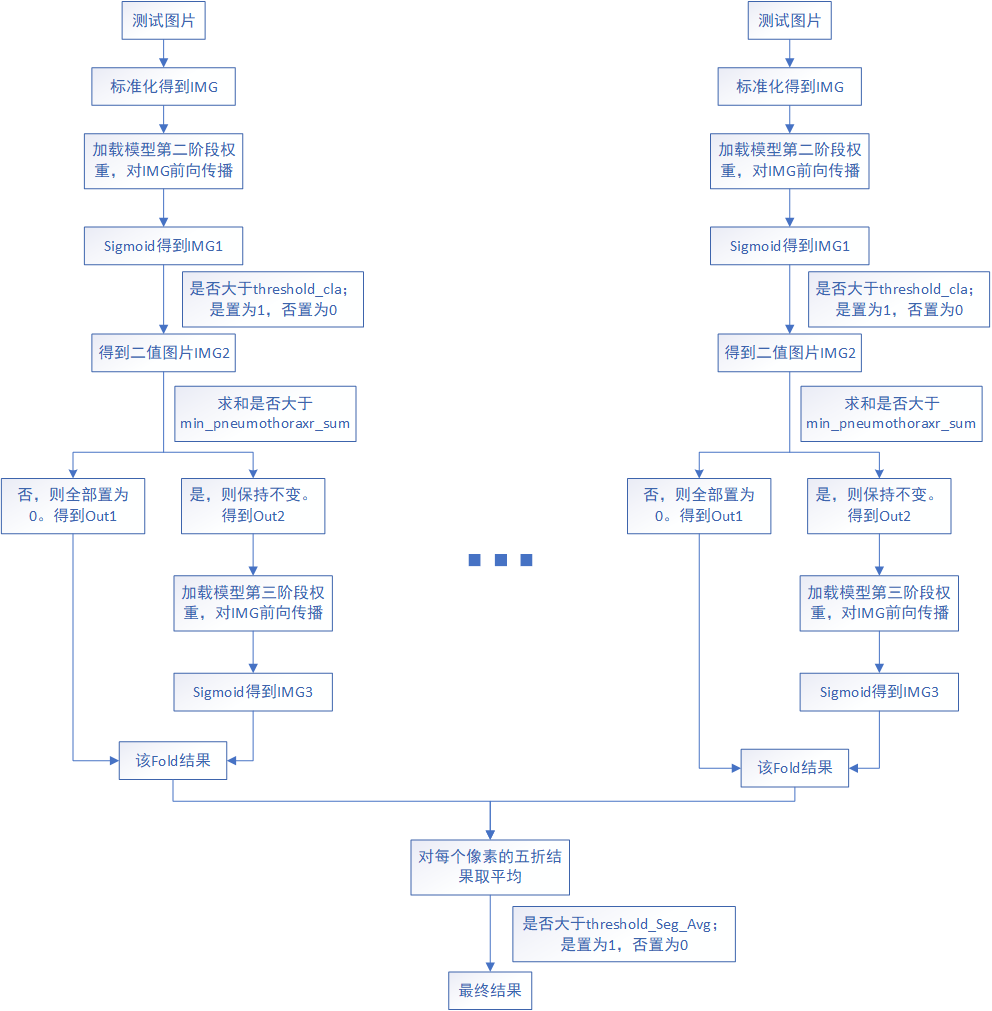
整体流程如下图所示。对于一张测试图片,首先将其标准化得到IMG,加载模型第二阶段权重,对IMG进行前向传播并经过Sigmoid函数得到IMG1,对IMG1中的每个像素点进行判断其是否大于threshold_cla,是置为1,否置为0得到二值图片IMG2,对IMG2求和,判断其是否大于min_pneumothoraxr_sum,若大于则保持不变得到Out2,若小于则认为我们模型误判了,则将该预测出的掩模所有像素值置为0,也就是置为无气胸,得到Out1。
若模型只有两个阶段的话,此时Out1+Out2就是最终的全部测试结果。但是因为我们通过对模型在验证集上的表现进行可视化,发现对于不含气胸的数据,预测结果也没有气胸;而有气胸的图片不一定能检测出有气胸,并且就算检测出有气胸了,细节信息也不好。因此第三阶段我们只对有气胸的数据进行fine-tuning,无气胸的数据舍弃掉。这样我们就可以拿前两个阶段作为分类模型,第三阶段作为分割模型。
若经过模型第二阶段的threshold_cla和min_pneumothoraxr_sum后,该图片还是为气胸图片的话,则加载模型第三阶段权重,对IMG前向传播并经过Sigmoid函数得到IMG3,对IMG3中的每个像素点进行判断其是否大于threshold_seg,是置为1,否置为0得到二值图片Out3作为最终的分割结果。此时Out1+Out3就是最终的全部测试结果。
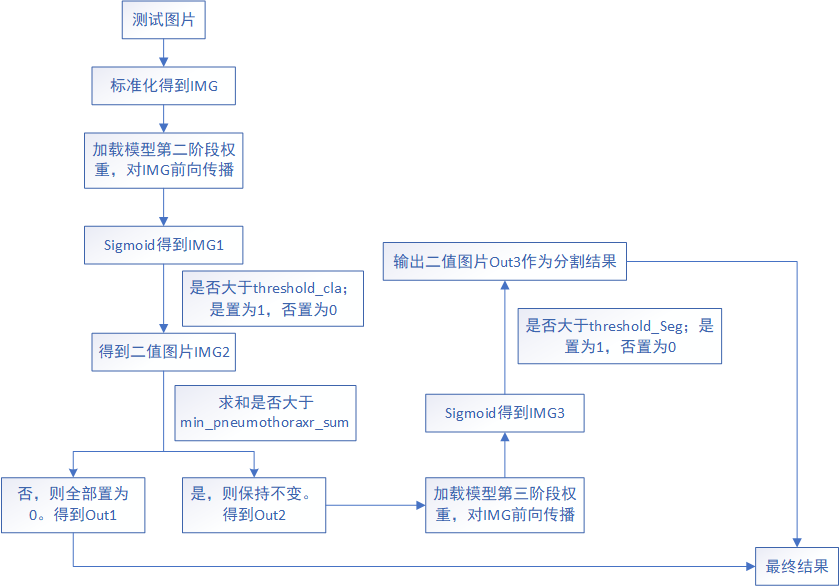
阈值评价标准
挑选阈值的标准为——相比其他阈值,验证集在取最优阈值时表现最好。至于如何衡量验证集的表现,我们这里有两个评价指标:
- Dice系数:也就是$\frac{2 * \mid X \cap Y \mid}{\mid X \mid + \mid Y \mid}$,$X$为预测出的像素集合,$Y$为真实标签。值得注意的是,当$X$和$Y$均为空的时候,Dice系数被定义为1。
- 分类准确率:当该图片为气胸图片,并且预测也为气胸图片的时候,即未分类正确,否则分类错误。
考虑到模型第一阶段和第二阶段主要起到分类器的作用,所以评价指标似乎是分类准确率更加合理;模型的第三阶段为分割模型,所以评价指标似乎是Dice系数更加合理。但是经过我们的实验和分析,若模型第二阶段使用分类准确率作为评价指标,预测出有气胸图像的图片数目偏多,但是我们的分割模型不一定能够对所有图片都准确分割,所以最终准确率反而有所下降(因为比赛方所使用的评价指标也是Dice)。因此我们最终决定模型第二阶段和第三阶段均选取Dice作为评价指标。
挑选阈值方法
因为模型的第二阶段存在threshold_cla以及min_pneumothoraxr_sum两个阈值,这是一个组合优化问题。对于该问题,有两个解决方案:
- 方案一:采用网格搜索的方法,依次遍历这两个阈值的候选解组合,挑选出使验证集Dice最高的组合。得到该组合后,缩小两个阈值的搜索区间,减小步长为之前的$1/2$做精细搜索,得到最终的最优组合。
- 方案二:采用线性搜索的方法,首先遍历threshold_cla的候选解,挑选出使验证集上的Dice系数最高的阈值,然后缩小threshold_cla的搜索区间,减小步长为之前的$1/2$做精细搜索,得到最终的最优threshold_cla。然后采用该最优threshold_cla依次与min_pneumothoraxr_sum的候选解组合,挑选出使验证集Dice最高的组合,即为最终的最优组合。
而模型的第三阶段只存在threshold_seg一个阈值,所以采用线性搜索的方法,首先遍历threshold_seg的候选解,挑选出使验证集上的Dice系数最高的阈值,然后缩小threshold_seg的搜索区间,减小步长为之前的$1/2$做精细搜索,得到最终的最优threshold_seg。
模型第二阶段threshold_cla、min_pneumothoraxr_sum以及模型第三阶段threshold_seg的候选解设置如下:
- 模型第二阶段threshold_cla的候选解,我们设置为
np.arange(0.60, 0.81, 0.015),这是因为根据之前的观察,模型的阈值通常不会高于0.81,不会低于0.60;相比于np.arange(0.10, 1.0, 0.015),可以成倍加快搜索速率。 - 模型第二阶段min_pneumothoraxr_sum的候选解,我们设置为
np.arange(768, 2305, 256),这是因为根据之前的观察,min_pneumothoraxr_sum不会低于768,而根据前面数据分析小节可以看到气胸像素总数小于2048的也有248张,占有气胸图片的大概10%。若高于2305,可能会过滤到一些预测正确的气胸样本。 - 模型第三阶段threshold_seg的候选解,我们设置为
np.arange(0.1, 1, 0.1),这是因为第三阶段对于最终的Dice指标影响很大,所以向尽可能的扩大阈值搜索范围。而因为第三阶段的验证集较小,且使用的是线性搜索,所以不需要考虑搜索速率的问题。
Ensemble
在之前Kaggle比赛经验文章中,提到从理论上讲,Ensemble的作用要同时降低最终模型的 Bias 和 Variance。Ensemble 要成功,有两个要素:
- Base Model 之间的相关性要尽可能的小。这就是为什么非 Tree-based Model 往往表现不是最好但还是要将它们包括在 Ensemble 里面的原因。Ensemble 的 Diversity 越大,最终 Model 的 Bias 就越低。
- Base Model 之间的性能表现不能差距太大。这其实是一个 Trade-off,在实际中很有可能表现相近的 Model 只有寥寥几个而且它们之间相关性还不低。但是实践告诉我们即使在这种情况下 Ensemble 还是能大幅提高成绩。
因为本次比赛我们只训练了一个模型,并且做集成的时间太晚(因为我们理所当然的觉得集成的效果肯定要好于单折的,毕竟见到了更多的数据),所以我们只尝试了投票以及平均两种集成策略。
如下图为投票策略示意图,输入测试图片,得到五折的预测二值图,对二值图的每一个像素值进行投票,若五折中有大于等于三折认为是正样本,则该像素为正样本,否则为负样本。需要注意的是,下面各折中的模型第二阶段threshold_cla、min_pneumothoraxr_sum以及模型第三阶段threshold_seg均为各折自己的最优值,并不是平均值。
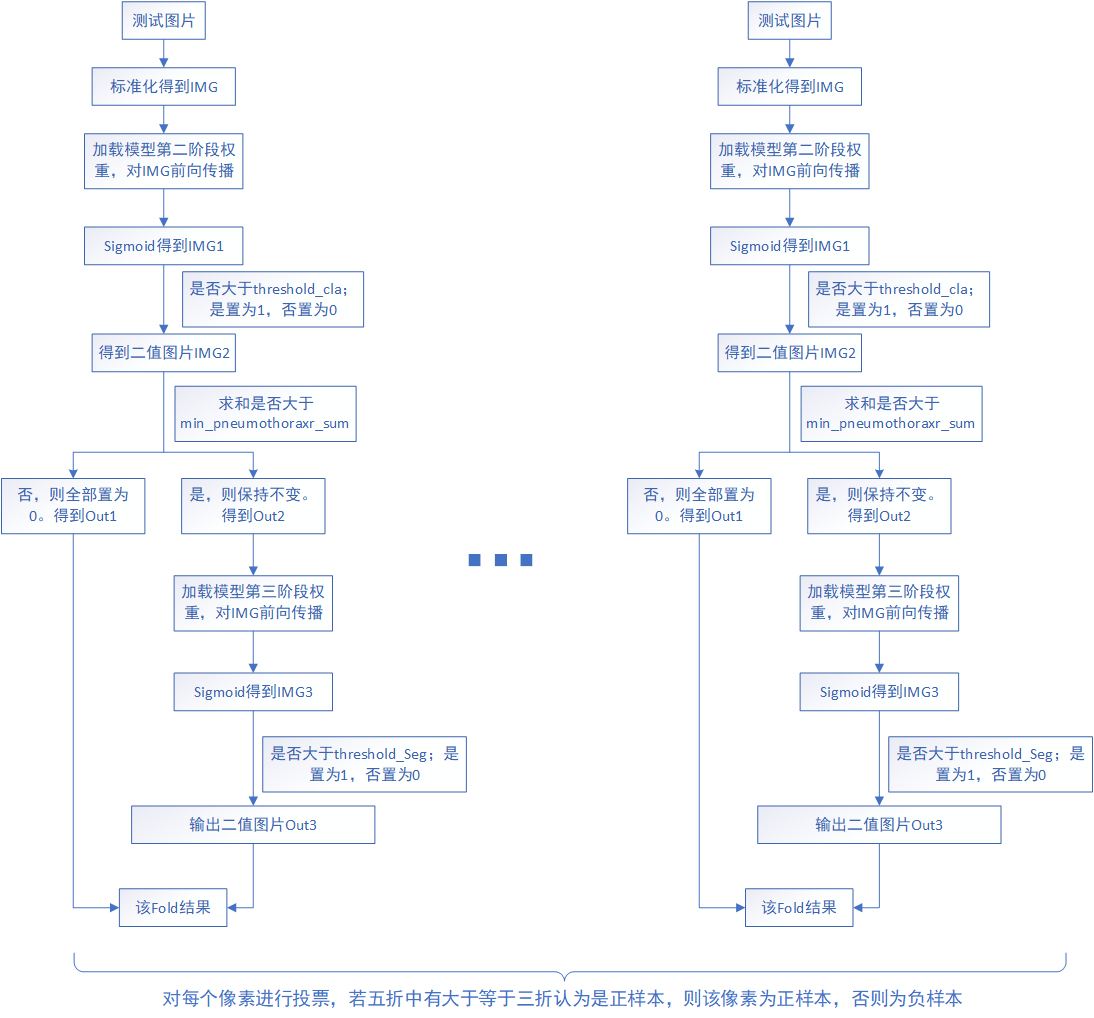
如下图为平均策略示意图,输入测试图片,得到五折的预测图(没有经过模型第三阶段threshold_seg,所以不是二值图,各个像素取值在[0,1]之间),对预测图的五折结果取平均,若大于threshold_Seg_Avg(对各折的第三阶段threshold_seg取平均得到)则置为1,否则置为0。需要注意的是,下面各折中的模型第二阶段threshold_cla、min_pneumothoraxr_sum为各折自己的最优值,而模型第三阶段threshold_seg_Avg为平均值。
最终比赛方让提交两个模型,我们就在纠结下面几个结果:
- 结果1:在比赛stage1训练样本集的fold0上训练出来的模型,该模型在比赛stage1的时候达到了Public leaderboard的最高名次。直接使用该模型产生最后结果。
- 结果2:比赛stage2的时候释放了stage1测试集样本的类标,我们将其划分为五折,将其fold0与比赛stage1训练集的fold0放到一起训练了一个模型,在该模型上选阈值差生最后结果。
- 结果3:将比赛stage1的训练集和stage1的测试集放到一起,重新划分五折,训练出5个模型,采用投票法产生结果。
- 结果4:将比赛stage1的训练集和stage1的测试集放到一起,重新划分五折,训练出5个模型,采用平均法产生结果。
我们日常测试的时候,单折的效果始终好于集成的效果的,但是我和我的小伙伴认为:
- 结果2中的模型已经包含了结果1模型的信息了,选两个模型会导致重复。
- 集成会见到更多的数据集,我们也不知道stage2的测试数据集分布是否和之前相差很大。
- 选上结果1和结果2会比较保险,而选一个集成一个单折的可以冲击较高名次。
- 各折之间的模型第三阶段threshold_seg差别还是挺大的,如果采用平均法,要对这几折的threshold_seg进行平均,不是很严谨。而用上各折模型第三阶段各自的threshold_seg可能效果更好。所以投票法结果应该好于平均法。
经过分析,我们决定提交结果2和结果3的模型。事实证明我们的分析是对的,在stage2的测试集上集成效果为0.8531确实好于单折的0.8491。我们还是挺幸运的,选上了我们最优模型,而有些人就不这么幸运了。所以之后让提交结果的时候,尽可能的相信见过更多数据集的模型,即使它在平时表现不好,谁也不知道在private leaderboard会发生什么。
经验
- 尽早做集成,因为集成效果不一定好。即使你将同一个模型五折的结果集成到一起,效果也不一定比单折好。
- backbone部分加载预训练权重特别重要,自己初始化的效果可能很差。
- 借助Tensorboard等工具分析训练集以及验证集的loss、dice曲线,进而调节学习率、权重衰减等超参数。
- 可视化模型预测结果,分析自己效果为什么会差,是分类效果差还是分割效果差。
- 经常看Kaggle比赛的Discussion,会有很多大佬分享自己的经验,对于我们这种小白或者计算性能有限的人来说特别重要。
- 要记录自己的实验结果,分为数据预处理、数据划分、模型、损失函数、超参数、验证集表现、阈值、测试集表现等部分。对于出现了好的结果,要及时做记录,改了什么,为什么会work。出现了较差的结果或者不work的结果,也要及时记录,改了什么,为什么不work。
- 对于要提交代码的比赛,要一直有一份目前最优结果的代码备份,不要临阵磨枪。
Code
- 变量命名,好的函数命名好处太多了。我现在遇到的问题是,词穷,有的时候就不知道该如何命名了。对于这个问题,暂时没有好的解决方案。
- 函数功能分清,尽量做到代码的高内聚低耦合,尽量减少代码的重复。
- 函数参数尽可能少,尤其不要使用两个参数组合控制一个功能,自己传参和后期更改代码都不好。
- 因为代码中通常包含着很多随机函数,每次随机种子可以不同,但是可以把随机种子保存下来,方便之后还原最优结果。
与金牌差距分析
金奖分享的solution如下:
1st place solution by Aimoldin Anuar [dsmlkz] (GitHub)
2nd place solution by yelan(Github)
3rd place solution by bestfitting(Github)
4th place solution by Miras Amir(Github)
5th place solution by earhian (GitHub)
6th place solution by WispZero(Github)
7th place solution by Eduardo Rocha de Andrade (GitHub 1, GitHub 2)
8th place solution by Ian Pan (GitHub)
9th place solution by Scizzzo(Github)
10th place solution by Yury Dzerin(Github)
11th place solution by n01z3 (GitHub)
12th place solution by fam_taro
Kaggle上的12th solution作者放出了Winners的模型对比。如下图所示:

从模型分析,前12名中有9个均是采用的Unet模型。且除了第3名、第4名和第9外,其余都用了多模型集成的策略。另外,只有第4名的backbone跟我们一致,其余的都比较复杂。因此从模型上来看,我们有以下两个方面做的没有Winners好:
- 没有多模型集成
- 使用的resnet34较为简单,没有采用更加强大的backbone
另外,因为该数据集图像尺寸比较大,导致batch size不能很大,batchnorm层可能不是很work,所以Kaggle Winner有人采用Group Norm的方式代替batchnorm。假设特征图的维度为[10, 256, 256],batch size的大小为32,则tensor的维度为[32, 10, 256, 256]。两者的区别在于:
- batchnorm:取32个特征图的第$i$个通道求一个均值和方差,这32个特征图第$i$个通道均使用该均值和方差做处理。所以最终得到的均值和方差数量为[10]
- groupnorm:取第$i$个特征图的若干个通道求一个均值和方差,这若干个通道使用该均值和方差做处理。若一个特征图可以划分为$n$个组合,则最终得到的均值和方差数量为[32, n]
附件
参考
理解图像中基本概念:色调、色相、饱和度、对比度、亮度
限制对比度自适应直方图均衡化算法原理、实现及效果
机器学习中常见的数据集划分方法总结
反卷积(Deconvolution)、上采样(UNSampling)与上池化(UnPooling)
CNN概念之上采样,反卷积,Unpooling概念解释
U-Net: Convolutional Networks for Biomedical Image Segmentation
Unet神经网络为什么会在医学图像分割表现好? - 王沈(Shawn)的回答 - 知乎
TernausNet
图像分割的U-Net系列方法
研习U-Net
论文阅读:《Deeply-Supervised Nets》
深度卷积神经网络的发展:从AlexNet到DenseNet
The Importance of Skip Connections in Biomedical Image Segmentation
torch.nn.ConvTranspose2d vs torch.nn.Upsample
Single model performance benchmark
Pytorch bcewithlogitsloss 官方文档
some workable loss function
Winners Base Models

