大概一个月前,老师给我分的方向是图神经网络。研一已经快过完了,我自己还没有确定好自己的研究方向。只知道自己想做技术,但是具体什么技术并没有想法,既然老师给分了这个方向,再加上自身也觉得图神经网络在推荐系统、半监督学习等领域有很大的发展前景,所以扎深这个领域也没什么。个人感觉研究生不像博士,没有那么专一,可以接触的范围广点,关键在于构建起自己的知识体系吧和思考吧。
看图神经网络已经一个星期了,还处于不知道所以云的地步,但是俗话说:“无用之用。”在研究图神经网络路上,本身对傅里叶分析、数字信号处理、卷积操作有了更加深刻的理解。
不说那么多了,边总结(复制)边学习图神经网络吧。下面的主要内容均来自网上,加上自身的一些思考。
CNN中的卷积
了解GCN之前必须对离散卷积(或者说CNN中的卷积)有一个明确的认识:
在之前我们讨论过:离散卷积的运算本质为加权求和;从频域来看,实质为是提取图像不同『频段』的特征。
那么卷积核的系数如何确定的呢?是随机化初值,然后根据误差函数通过反向传播梯度下降进行迭代优化。这是一个关键点,卷积核的参数通过优化求出才能实现特征提取的作用,GCN的理论很大一部分工作就是为了引入可以优化的卷积参数。
为什么要研究GCN
CNN是Computer Vision里的大法宝,效果为什么好呢?原因为CNN可以很有效地提取空间特征。但是有一点需要注意:CNN处理的图像或者视频数据中像素点(pixel)是排列成成很整齐的矩阵(如下图所示,也就是很多论文中所提到的Euclidean Structure)。
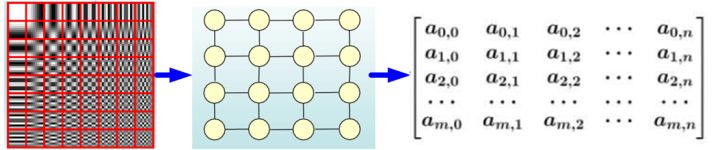
与之相对应,科学研究中还有很多Non Euclidean Structure的数据,如下图所示。社交网络、信息网络中有很多类似的结构。

实际上,这样的网络结构(Non Euclidean Structure)就是图论中抽象意义上的拓扑图。
所以,Graph Convolutional Network中的Graph是指数学(图论)中的用顶点和边建立相应关系的拓扑图。
那么为什么要研究GCN?原因有三:
(1)CNN无法处理Non Euclidean Structure的数据,学术上的表达是传统的离散卷积(如问题1中所述)在Non Euclidean Structure的数据上无法保持平移不变性。通俗理解就是在拓扑图中每个顶点的相邻顶点数目都可能不同,那么当然无法用一个同样尺寸的卷积核来进行卷积运算。
(2)由于CNN无法处理Non Euclidean Structure的数据,又希望在这样的数据结构(拓扑图)上有效地提取空间特征来进行机器学习,所以GCN成为了研究的重点。
(3)读到这里大家可能会想,自己的研究问题中没有拓扑结构的网络,那是不是根本就不会用到GCN呢?其实不然,广义上来讲任何数据在赋范空间内都可以建立拓扑关联,谱聚类就是应用了这样的思想(谱聚类(spectral clustering)原理总结)。所以说拓扑连接是一种广义的数据结构,GCN有很大的应用空间。
综上所述,GCN是要为除CV、NLP之外的任务提供一种处理、研究的模型。
提取拓扑图空间特征的两种方式
GCN的本质目的就是用来寻找适用于图的可学习卷积核提取拓扑图的空间特征,那么实现这个目标只有graph convolution这一种途径吗?当然不是,在vertex domain(spatial domain,空域)和spectral domain(频域)实现目标是两种最主流的方式。通俗点解释,空域可以类比到直接在图片的像素点上进行卷积,而频域可以类比到对图片进行傅里叶变换后,再进行卷积。
基于空域卷积的方法直接将卷积操作定义在每个结点的连接关系上,它跟传统的卷积神经网络中的卷积更相似一些。在这个类别中比较有代表性的方法有 Message Passing Neural Networks(MPNN), GraphSage, Diffusion Convolution Neural Networks(DCNN), PATCHY-SAN[4]等。
基于频域卷积的方法则从图信号处理起家,包括 Spectral CNN, Cheybyshev Spectral CNN(ChebNet), 和 First order of ChebNet(1stChebNet)等。
vertex domain(spatial domain,空域)
vertex domain(spatial domain,空域)是非常直观的一种方式。从设计理念上看,空域卷积与深度学习中的卷积的应用方式类似,其核心在于聚合邻居结点的信息。
顾名思义:提取拓扑图上的空间特征,那么就把每个顶点相邻的neighbors找出来。这里面蕴含的科学问题有二:
- 按照什么条件去找中心vertex的neighbors,也就是如何确定receptive field?
- 确定receptive field,按照什么方式处理包含不同数目neighbors的特征?
根据这两个问题设计算法,就可以实现目标了。推荐阅读这篇文章Learning Convolutional Neural Networks for Graphs(下面是其中一张图片,可以看出大致的思路)。

这种方法主要的缺点如下:
- 每个顶点提取出来的neighbors不同,使得计算处理必须针对每个顶点
- 提取特征的效果可能没有卷积好
再比如说,一种最简单的无参卷积方式可以是:将所有直连邻居结点的隐藏状态加和,来更新当前结点的隐藏状态。
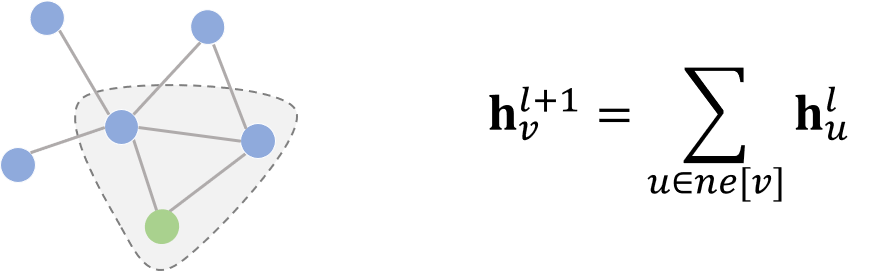
这里非参式的卷积只是为了举一个简单易懂的例子,实际上图卷积在建模时需要的都是带参数、可学习的卷积核。
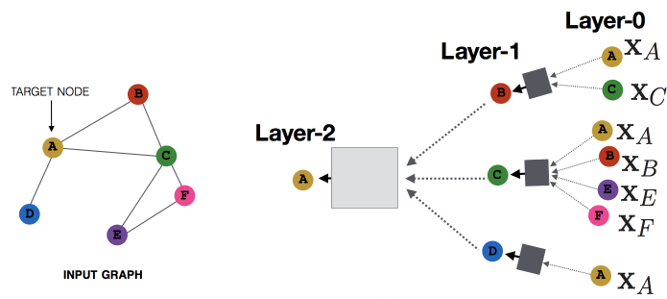
消息传递网络(Message Passing Neural Network)
严格意义上讲,MPNN不是一种具体的模型,而是一种空域卷积的形式化框架。它将空域卷积分解为两个过程:消息传递与状态更新操作,分别由$M_{l}(\cdot)$和$U_{l}(\cdot)$函数完成。将结点$v$的特征$\mathbf{x}_v$作为其隐藏状态的初始态$\mathbf{h}_{v}^0$后,空域卷积对隐藏状态的更新由如下公式表示:
其中$l$代表图卷积的第$l$层,上式的物理意义是:收到来自每个邻居的的消息$M_{l+1}$后,每个结点如何更新自己的状态。
你可能会觉得这个公式与GGNN的公式很像。实际上,它们是截然不同的两种方式:GCN中通过级联的层捕捉邻居的消息,GNN通过级联的时间来捕捉邻居的消息;前者层与层之间的参数不同,后者可以视作层与层之间共享参数。MPNN的示意图如下:
图采样与聚合(Graph Sample and Aggregate)
MPNN很好地概括了空域卷积的过程,但定义在这个框架下的所有模型都有一个共同的缺陷:卷积操作针对的对象是整张图,也就意味着要将所有结点放入内存/显存中,才能进行卷积操作。但对实际场景中的大规模图而言,整个图上的卷积操作并不现实。GraphSage提出的动机之一就是解决这个问题。从该方法的名字我们也能看出,区别于传统的全图卷积,GraphSage利用采样(Sample)部分结点的方式进行学习。当然,即使不需要整张图同时卷积,GraphSage仍然需要聚合邻居结点的信息,即论文中定义的aggregate的操作。这种操作类似于MPNN中的消息传递过程。
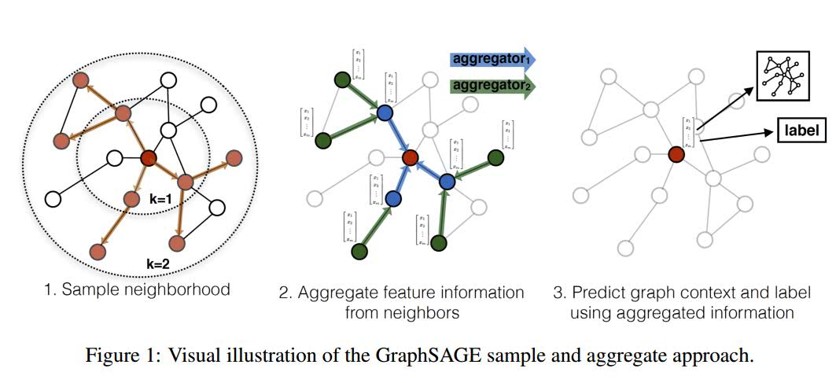
具体地,GraphSage中的采样过程分为三步:
- 在图中随机采样若干个结点,结点数为传统任务中的
batch_size。对于每个结点,随机选择固定数目的邻居结点(这里邻居不一定是一阶邻居,也可以是二阶邻居)构成进行卷积操作的图。 - 将邻居结点的信息通过$aggregate$函数聚合起来更新刚才采样的结点。
- 计算采样结点处的损失。如果是无监督任务,我们希望图上邻居结点的编码相似;如果是监督任务,即可根据具体结点的任务标签计算损失。
最终,GraphSage的状态更新公式如下:
GraphSage的设计重点就放在了$aggregate$函数的设计上。它可以是不带参数的$max$, $mean$, 也可以是带参数的如$LSTM$等神经网络。核心的原则仍然是,它需要可以处理变长的数据。卷积神经网络中针对图任务的ReadOut操作,$aggregate$函数的设计与其有异曲同工之妙,此处就不展开叙述了。
图结构序列化(PATCHY-SAN)
之前曾提到卷积神经网络不能应用在图结构上是因为图是非欧式空间,所以大部分算法都沿着找到适用于图的卷积核这个思路来走。而 PATCHY-SAN 算法另辟蹊径,它将图结构转换成了序列结构,然后直接利用卷积神经网络在转化成的序列结构上做卷积。由于 PATCHY-SAN在其论文中主要用于图的分类任务,下面的计算过程也主要针对图分类问题(例如,判断某个社群的职业)。
那么,图结构转换成序列结构最主要的挑战在何处呢,如果简单的话,为什么以前的工作没有尝试把图转成序列结构呢?就笔者个人的观点来看,这种序列转换要保持图结构的两个特点:1. 同构的性质。 2. 邻居结点的连接关系。对于前者而言,意味着当我们把图上结点的标号随机打乱,得到的仍应是一样的序列。简单来说就是,同构图产生的序列应当相似,甚至一样;对于后者,则意味着我们要保持邻居结点与目标结点的距离关系,如在图中的三阶邻居在序列中不应该成为一阶邻居等。
PATCHY-SAN 通过以下三个步骤来解决这两个问题:
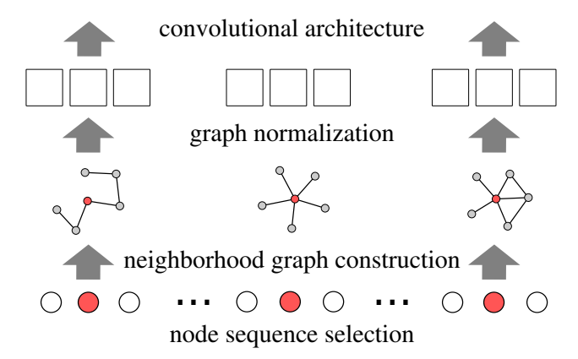
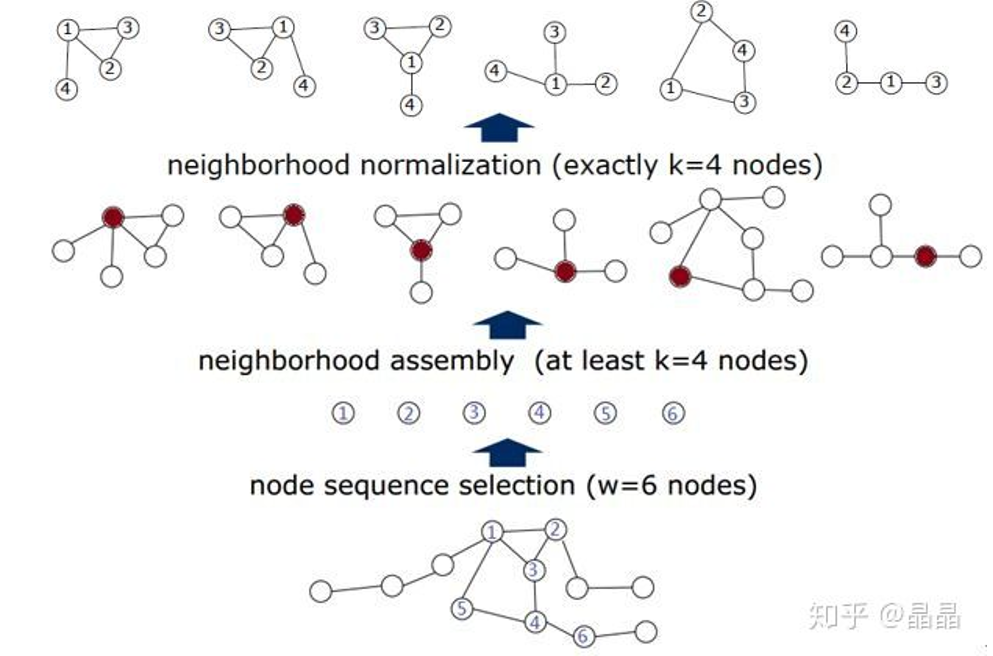
- 结点选择(Node Squenece Selection)。该过程旨在与通过一些人为定义的规则(如度大的结点分数很高,邻居的度大时分数较高等)为每个结点指定一个在图中的排序。在完成排序后,取出前 $\omega$ 个结点作为整个图的代表。
- 邻居结点构造(Neighborhood graph construction)。在完成结点排序后,以第1步选择的结点为中心,得到它们的邻居(这里的邻居可以是第一阶邻居,也可以是二阶邻居)结点,就构成了 $\omega$ 个团。根据第1步得到的结点排序对每个团中的邻居结点进行排序,再取前 $k$ 个邻居结点按照顺序排列,即组成 $\omega$ 个有序的团。
- 图规范化(Graph Noermalization)。按照每个团中的结点顺序可将所有团转换成固定长度的序列($k+1$),再将它们按照中心结点的排序从前到后依次拼接,即可得到一个长度为 ${\omega}*(k+1)$ 的代表整张图的序列。这样,我们就可以直接使用带1D的卷积神经网络对该序列建模,比如图分类(可类比文本序列分类)。值得注意的一点是,在第1步和第2步中,如果取不到 $\omega$ 或 $k$ 个结点时,要使用空结点作填充(padding)。
一个形象的流程图如下所示:
下图可能可以帮助读者更好地理解这种算法。
spectral domain
空域卷积非常直观地借鉴了图像里的卷积操作,但它缺乏一定的理论基础。而频域卷积则不同,相比于空域卷积而言,它主要利用的是图傅里叶变换(Graph Fourier Transform)实现卷积。简单来讲,它利用图的拉普拉斯矩阵(Laplacian matrix)导出其频域上的的拉普拉斯算子,再类比频域上的欧式空间中的卷积,导出图卷积的公式。虽然公式的形式与空域卷积非常相似,但频域卷积的推导过程却有些艰深晦涩。
spectral domain就是GCN的理论基础了。这种思路就是希望借助图谱的理论来实现拓扑图上的卷积操作。从整个研究的时间进程来看:首先研究GSP(graph signal processing)的学者定义了graph上的Fourier Transformation,进而定义了graph上的convolution,最后与深度学习结合提出了Graph Convolutional Network。
认真读到这里,脑海中应该会浮现出一系列问题:
Q1 什么是spectral(谱)
个人理解谱就是拉普拉斯矩阵的特征值。在数值分析中也学到过,矩阵$A_{n \times n}$的特征值为$\lambda_i(i=1,2,…,n)$,称$\rho (A)=max_{1 \leq i \leq n }\mid \lambda_i \mid$为$A$的谱半径,即$A$的谱半径为其最大特征值。
Q2 什么是spectral domain?
个人理解spectral domain为拉普拉斯矩阵$n$个线性无关的特征向量组成的空间。
Q2 什么是Spectral graph theory?
Spectral graph theory请参考这个,简单的概括就是借助于图的拉普拉斯矩阵的特征值和特征向量来研究图的性质。个人理解为将拓扑图空间域(spatial domain)映射到谱域,类似于傅里叶变换将时域映射到频域一样。实质方法为基变换(分解)。
Q3 GCN为什么要利用Spectral graph theory?
这应该是看论文过程中读不懂的核心问题了,要理解这个问题需要大量的数学定义及推导,没有一定的数学功底难以驾驭(我也才疏学浅,很难回答好这个问题)。
所以,先绕过这个问题,来看Spectral graph实现了什么,再进行探究为什么?
拉普拉斯矩阵
Graph Fourier Transformation及Graph Convolution的定义都用到图的拉普拉斯矩阵,那么首先来介绍一下拉普拉斯矩阵。
定义
对于一个图$G$,我们一般用点的集合$V$和边的集合$E$来描述。即为$G(V,E)$。其中$V$即为我们数据集里面所有的点$(v_1,v_2,…v_n)$。对于$V$中的任意两个点,可以有边连接,也可以没有边连接。我们定义权重$A_{ij}$为点$v_i$和点$v_j$之间的权重。若为无向图,则$A_{ij}=A_{ji}$。 对于有边连接的两个点$v_i$和$v_j$,$A_{ij} > 0$,对于没有边连接的两个点$v_i$和$v_j$,$A_{ij} =0$。对于图中的任意一个点$v_i$,它的度$d_i$定义为和它相连的所有边的权重之和,即
利用每个点度的定义,我们可以得到一个$n \times n$的度矩阵$D$,它是一个对角矩阵,只有主对角线有值,对应第$i$行的第$i$个点的度数,定义如下:
利用所有点之间的权重值,我们可以得到图的邻接矩阵$A$,它也是一个$n \times n$的矩阵,第$i$行的第$j$个值对应我们的权重$A_{ij}$。
图$G$的Laplacian 矩阵的定义为$L=D-A$,其中 $L$ 是Laplacian 矩阵,$D$ 是顶点的度矩阵(对角矩阵),对角线上元素依次为各个顶点的度, $A$ 是图的邻接矩阵。看下图的示例,就能很快知道Laplacian 矩阵的计算方法。
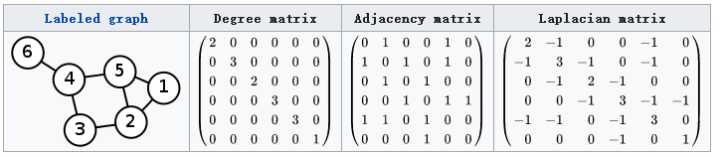
这里要说明的是:常用的拉普拉斯矩阵实际有三种:
No.1 $L=D-A$定义的Laplacian 矩阵更专业的名称叫Combinatorial Laplacian。该矩阵是对称矩阵。
No.2 $L^{sys}=D^{-1/2}LD^{-1/2}=I-D^{-1/2}AD^{-1/2}$ 定义的叫Symmetric normalized Laplacian,很多GCN的论文中应用的是这种拉普拉斯矩阵。也就是说该拉普拉斯矩阵是对称矩阵,其中的元素可以由下面公式计算可得:
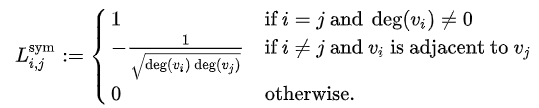
No.3 $L^{rw}=D^{-1}L$定义的叫Random walk normalized Laplacian,有读者的留言说看到了Graph Convolution与Diffusion相似之处,当然从Random walk normalized Laplacian就能看出了两者确有相似之处(其实两者只差一个相似矩阵的变换,可以参考Diffusion-Convolutional Neural Networks,以及下图)。也就是说该拉普拉斯矩阵不是对称矩阵,其中的元素可以由下面公式计算可得:
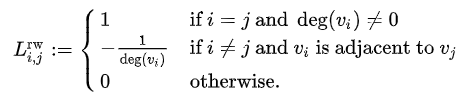
不需要相关内容的读者可以略过此部分

其实维基本科对Laplacian matrix的定义上写得很清楚,国内的一些介绍中只有第一种定义。这让我在最初看文献的过程中感到一些的困惑,特意写下来,帮助大家避免再遇到类似的问题。
为什么要使用拉普拉斯矩阵
以下均是我的或者网上一些理解,当然严格意义上,拉普拉斯矩阵应用于GCN有严谨的数学推导与证明。
物理含义角度
要探究拉普拉斯矩阵的物理含义,需要从他的方程式入手,以$L=D-A$为例,解释为何拉普拉斯矩阵为何要这么定义。
拉普拉斯算子数学定义是这样的:
其含义很明确,是非混合二阶偏导数的和!
混合偏导:如二元函数,则先对第一个变量求导,其结果再对第二个变量求导,就可以得到混合偏导数。而非混合偏导:如二元函数,只针对某个变量求二次偏导。
要明白这个是其严谨的数学定义,所有的其他拉普拉斯算子都是其一个特例,或是某种情况下的一种近似。
我们首先看看图像上怎么近似的,图像是一种离散数据,那么其拉普拉斯算子必然要进行离散化。
从导数定义说起
那么:
结论1:二阶导数近似等于其二阶差分。
结论2:二阶导数等于其在所有自由度上微扰之后获得的增益。一维函数其自由度可以理解为2,分别是+1和-1两个方向。
对于二维的图像来说,其有两个方向(4个自由度)可以变化,即如果对$(x,y)$处的像素进行扰动,其可以变为四种状态$(x+1,y),(x-1,y),(x,y+1),(x,y-1)$。当然了,如果将对角线方向也认为是一个自由度的话,会再增加几种状态$(x+1,y+1),(x+1,y-1),(x-1,y+1),(x-1,y-1)$,事实上图像处理上正是这种。再当然了,如果你认为对一个像素进行微扰可能变为任何一个像素,那它的自由度就是整个图片的像素数(不过这还叫微扰吗?)。其实结论差不多,就讨论第一种吧。
上式可以理解为,在图像上某一点,其拉普拉斯算子的值,即为对其进行扰动,使其变化到相邻像素后得到的增益。
图像处理中的拉普拉斯算子写成矩阵形式,更加方便理解。
这给我们一种形象的结论:图像处理中的拉普拉斯算子就是某一点在所有自由度上进行微小变化后获得的增益。
讨论过图像上的拉普拉斯算子的物理含义后,我们扩展到graph,探索在graph上拉普拉斯算子的物理含义。
那么推广到Graph,对于有$V$个节点的Graph,就设节点为 $1,…,V$吧,且其邻接矩阵为$A$。
这个Graph的自由度是多少呢?答案是最多为$V$。
因为如果该图是一个完全图,即任意两个节点之间都有一条边,那么对一个节点进行微扰,它可能变成任意一个节点。
那么上面的函数$f$就理所当然是一个$V$维的向量,即:
其中$f_i$即表示函数$f$在节点$i$的值。类比$f(x,y)$即为$f$在$(x,y)$处的值。
对于任意节点$i$进行微扰,它可能变为任意一个与他相邻的节点$j\in\mathcal{N_i}$,其中$\mathcal{N_i}$表示节点i的一阶邻域节点。
我们上面结论说了,拉普拉斯算子就是在所有自由度上进行微小变化后获得的增益。
但是对于Graph,从节点$i$变化到节点$j$增益是多少呢?即$f_j-f_i$是多少呢?最容易想到就是和他们之间的边权相关。那就姑且当成$A_{ij}$吧!
那么,对于节点i来说,其变化的增益就是 $\sum_{j\in\mathcal{N}_i}A_{ij}[f_j-f_i]$
所以,对于Graph来说,其拉普拉斯算子如下:
上式 $j\in\mathcal{N}_i$可以去掉,因为节点$i$和$j$不直接相邻的话,$A_{ij} = 0$;
继续化简一下:
即:
对于任意的$i$成立,那么也就是:
也就是图上的拉普拉斯算子应该定义为$A-D$!
注: 以上没有特别严谨的数学推导,甚至数学表达式都不太严谨,主要源于类比+简单推导,主要想说清楚图上拉普拉斯算子为啥这么定义。另外为何是$A-D$而不是$D-A$,我也不是很明白。
关于Symmetric normalized Laplacian:$L^{sys}=D^{-1/2}LD^{-1/2}=I-D^{-1/2}AD^{-1/2}$。观察Combinatorial Laplacian$L$的形式,可以看出来,每一行$i$之和均为0,且最大元素为$D_i$,所以使用$L$左乘和右乘对角矩阵$D^{-1/2}$相当于对$L$进行归一化。这样做的好处是防止梯度弥散或者梯度爆炸。Random walk normalized Laplacian:$L^{rw}=D^{-1}L$同理。
总结:
- 从拉普拉斯算子的定义形式来看,$D$为拓扑图的度矩阵,而$A$为邻接矩阵,拉普拉斯矩阵$D-L$综合了两个矩阵的信息,更能从空间的表现出拓扑图的结构。
类似于信号与系统中使用$f(t)$表示信号时域特征,我们可以使用拉普拉斯矩阵$L$表征graph的拓扑结构。 - 拉普拉斯矩阵就是某一点在所有自由度上进行微小变化后获得的增益,对于图神经网络而言,最重要的是利用节点之间的关系去相互影响,所以拉普拉斯矩阵也比较适合用来描述图节点之间的相互作用关系。
数学角度
拉普拉斯矩阵有一些很好的性质如下:
- 拉普拉斯矩阵是对称矩阵,这可以由$D$和$A$(无向图)都是对称矩阵而得。对称矩阵一定有$n$个线性无关的特征向量,特征向量相互正交,即所有特征向量构成的矩阵为正交矩阵。因此可以将图的$n$个顶点上的值进行特征分解(谱分解),这就和GCN的spectral domain对应上了。
- 拉普拉斯矩阵只在
中心顶点和一阶相连的顶点上(1-hop neighbor)有非0元素,其余之处均为0 - 由于拉普拉斯矩阵是对称矩阵,则它的所有的特征值都是实数。

- 对于任意的向量$f$,我们有
这个利用拉普拉斯矩阵的定义很容易得到如下:
- 拉普拉斯矩阵是半正定的,且对应的n个实数特征值都大于等于0,即$0 =\lambda_1 \leq \lambda_2 \leq… \leq \lambda_n$, 且最小的特征值为0,这个由性质3很容易得出。
拉普拉斯矩阵的谱分解(特征分解)
GCN的核心基于拉普拉斯矩阵的谱分解,文献中对于这部分内容没有讲解太多,初学者可能会遇到不少误区,所以先了解一下特征分解。
矩阵的谱分解,特征分解,对角化都是同一个概念(特征分解_百度百科)。
不是所有的矩阵都可以特征分解,其充要条件为$n$阶方阵存在$n$个线性无关的特征向量。
但是拉普拉斯矩阵是半正定对称矩阵(半正定矩阵本身就是对称矩阵,半正定矩阵_百度百科,此处这样写为了和下面的性质对应,避免混淆),有如下三个性质:
- 对称矩阵一定n个线性无关的特征向量
- 半正定矩阵的特征值一定非负
- 对阵矩阵的特征向量相互正交,即所有特征向量构成的矩阵为正交矩阵。
由上可以知道拉普拉斯矩阵一定可以谱分解,且分解后有特殊的形式。
对于拉普拉斯矩阵其谱分解为:
其中$U=(\vec{u_1},\vec{u_2},\cdots,\vec{u_n})$,是列向量为单位特征向量的矩阵,也就说$\vec{u_l}$ 是单位列向量。
$\left(\begin{matrix}\lambda_1 & \\&\ddots \\ &&\lambda_n \end{matrix}\right)$ 是$n$个特征值构成的对角阵。
由于$U$正交矩阵,即$UU^{T}=E$
所以特征分解又可以写成:
文献中都是最后导出的这个公式,但大家不要误解,特征分解最右边的是特征矩阵的逆,只是拉普拉斯矩阵的性质才可以写成特征矩阵的转置。
其实从上可以看出:整个推导用到了很多数学的性质,在这里写得详细一些,避免大家形成错误的理解。
推广傅里叶变换、卷积
把传统的傅里叶变换以及卷积迁移到Graph上来,核心工作其实就是把拉普拉斯算子的特征函数$e^{-i\omega t}$ 变为Graph对应的拉普拉斯矩阵的特征向量。
推广傅里叶变换
想亲自躬行的读者可以阅读The Emerging Field of Signal Processing on Graphs: Extending High-Dimensional Data Analysis to Networks and Other Irregular Domains这篇论文,下面是我的理解与提炼:
Graph上的傅里叶变换
传统的傅里叶变换定义为:
信号$f(t)$与基函数$e^{-i\omega t}$的积分,那么为什么要找$e^{-i\omega t}$ 作为基函数呢?从数学上看, $e^{-i\omega t}$ 是拉普拉斯算子$\triangle$的本征函数(满足本征方程), $\omega$ 就和特征值有关。
广义的本征方程定义为:
其中$A$ 是一种线性变换,$V$是本征函数(当$A$为矩阵时,$V$为特征向量),$\lambda$是特征值。
$e^{-i\omega t}$满足:
当然$e^{-i\omega t}$ 就是拉普拉斯变换$\Delta$的特征函数, $\omega$ 和特征值密切相关。
另外,考虑到广义上的内积是一种投影,则式子$({16})$还可以写成下面内积的形式:
这里不给出证明,因为暂时我还不清楚积分区间$[-\infty,\infty]$的函数内积的定义。
那么,可以联想了,处理Graph问题的时候,用到拉普拉斯矩阵(拉普拉斯矩阵就是离散拉普拉斯算子,想了解更多可以参考Discrete Laplace operator),自然就去找拉普拉斯矩阵的特征向量了。
其实,在之前我们对傅里叶变换的深层次思考之后,得到结论所谓傅里叶变换就是将时域信号分解到一组完备正交基上,而式子$({16})$就是分解到完备正交基的系数。所以推广到图领域,Graph上的顶点,类似于我们的时域信号,现在要找到一组完备正交基将其分解,而拉普拉斯矩阵的$n$个特征向量恰好可以组成Graph上$n$维空间的一组完备正交基。将拉普拉斯矩阵分解到谱域之后,可以利用时域卷积等于谱域相乘的性质,首先定义谱域中的相乘,然后使用逆傅里叶变换得到时域的卷积。
$L$是拉普拉斯矩阵, $V$是其特征向量,自然满足下式
离散积分就是一种内积形式,仿上定义Graph上的傅里叶变换:
因为$u_l^*$为单位列向量,所以分母为1,也就可以写成下式。
$f$是Graph上的 $N$维向量,$f(i)$与Graph的顶点一一对应, $u_l(i)$表示第$l$个特征向量的第$i$ 个分量。那么特征值(频率)$\lambda_l$下的,$f$的Graph 傅里叶变换就是与 $\lambda_l$对应的特征向量$u_l$ 进行内积运算。
注:上述的内积运算是在复数空间中定义的,所以采用了$u_l^*(i)$,也就是特征向量$u_l$的共轭。Inner product更多可以参考Inner product space。
利用矩阵乘法将Graph上的傅里叶变换推广到矩阵形式:
即 $f$ 在Graph上傅里叶变换的矩阵形式为:
式中: $U^T$的定义与第五节中的相同,$f$和$\hat f$均为$N \times 1$的列向量。
Graph上的傅里叶逆变换
类似地,传统的傅里叶逆变换是对频率$\omega$求积分:
迁移到Graph上变为对特征值$\lambda_l$求和:
利用矩阵乘法将Graph上的傅里叶逆变换推广到矩阵形式:
即$f$在Graph上傅里叶逆变换的矩阵形式为:
式中: $U$的定义与第五节中的相同,$f$和$\hat f$均为$N \times 1$的列向量。
推广卷积
在上面的基础上,利用卷积定理类比来将卷积运算,推广到Graph上。
卷积定理:函数卷积的傅里叶变换是函数傅立叶变换的乘积,即对于函数 $f(t)$ 与$h(t)$两者的卷积是其函数傅立叶变换乘积的逆变换:
类比到Graph上并把傅里叶变换的定义带入, $f$与卷积核$h$ 在Graph上的卷积可按下列步骤求出:
$f$的傅里叶变换为 $\hat{f}=U^Tf$
卷积核$h$的傅里叶变换写成对角矩阵的形式即为:
其中,$\hat{h}(\lambda_l)=\sum_{i=1}^{N}{h(i) u_l^(i)}$ 是*根据需要设计的卷积核$h$(大小为$N \times 1$)在Graph上的傅里叶变换。这里将$U^Tg$ 整体看作可学习的卷积核。
两者的傅立叶变换乘积即为:$ \left(\begin{matrix}\hat h(\lambda_1) & \\&\ddots \\ &&\hat h(\lambda_n) \end{matrix}\right)U^Tf$
再乘以$U$求两者傅立叶变换乘积的逆变换,则求出卷积:
式中: $U$及$U^{T}$的定义与第五节中的相同
注:很多论文中的Graph卷积公式为:
$\odot$表示hadamard product(哈达马积),对于两个向量,就是进行内积运算;对于维度相同的两个矩阵,就是对应元素的乘积运算。
其实式(31)与式(32)是完全相同的。
因为 $\left(\begin{matrix}\hat h(\lambda_1) & \\&\ddots \\ &&\hat h(\lambda_n) \end{matrix}\right)$与 $U^Th$都是 $h$ 在Graph上的傅里叶变换
而根据矩阵乘法的运算规则:对角矩阵 $\left(\begin{matrix}\hat h(\lambda_1) & \\&\ddots \\ &&\hat h(\lambda_n) \end{matrix}\right)$与 $U^Tf$ 的乘积和$U^Th$ 与 $U^Tf$进行对应元素的乘积运算是完全相同的。
这里主要推$({31})$式是为了和后面的deep learning相结合。
这部分理论感觉缺乏很严谨的证明,大部分都是按照类比的概念推广的。例如拉普拉斯变换(二阶导)和傅里叶变换有什么关联,为啥拉普拉斯变换的特征函数就可以作为傅里叶变换的基?Graph上的傅里叶逆变换和Graph上的卷积定理均缺乏推导。现在只是大概介绍一下思路,具体细节需要日后再做钻研。
为什么拉普拉斯矩阵的特征向量可以作为傅里叶变换的基?特征值表示频率?
为什么拉普拉斯矩阵的特征向量可以作为傅里叶变换的基?
傅里叶变换一个本质理解就是:把任意一个函数表示成了若干个正交函数(由sin,cos 构成)的线性组合。
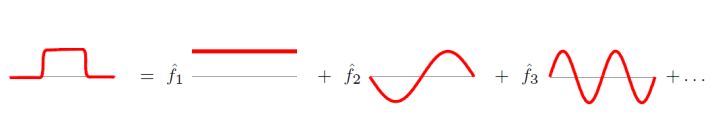
通过第六节中式$({28})$也能看出,graph傅里叶变换也把graph上定义的任意向量$f$,表示成了拉普拉斯矩阵特征向量的线性组合,即:
那么:为什么graph上任意的向量$f$都可以表示成这样的线性组合?
原因在于$(\vec{u_1},\vec{u_2},\cdots,\vec{u_n})$是graph上$n$维空间中的$n$ 个线性无关的正交向量(原因参看第五节中拉普拉斯矩阵的性质),由线性代数的知识可以知道:$n$维空间中$n$个线性无关的向量可以构成空间的一组基,而且拉普拉斯矩阵的特征向量还是一组标准正交基。
怎么理解拉普拉斯矩阵的特征值表示频率
在graph空间上无法可视化展示“频率”这个概念,那么从本征方程上来抽象理解。
将拉普拉斯矩阵$L$ 的$n$个非负实特征值,从小到大排列为$\lambda_1 \le \lambda_2 \le \cdots \le \lambda_n$ ,而且最小的特征值$\lambda_1=0$,因为$n$维的全1向量对应的特征值为0。
虽然矩阵的特征向量不唯一,但是特征值是唯一的。也就是说虽然我们相互正交的特征向量不一定包含全1向量,但是矩阵的特征值一定包含全1向量对应的特征值。
证明:
$L$的定义为$L=D-A$,其中$D$为度矩阵,其每一个元素$d_i =\sum\limits_{j=1}^{n}A_{ij}$。而$A$为邻接矩阵,因为我们这里讨论的是简单图,即没有自身到自身的连接,所以对角线为0。从而可以看出$L$的每一行之和均为0。所以可得:
得证。
从中可以看出,拉普拉斯矩阵特征值$\lambda_1=0$的时候,特征向量的分一个分量均为常数,变化幅度为0;我们不加证明的给出,越大的特征值对应的特征向量各个分量变化范围越大。在一般的信号傅里叶变换中,基为$e^{-jwt}$,其中的$w$可以表示频率,$w$越大,基的变化越快。类比到图傅里叶变换,特征值表示频率,特征值越大,基$u_l$的变化越快。
从本征方程的数学理解来看:
在由Graph确定的$n$维空间中,越小的特征值$\lambda_l$表明:拉普拉斯矩阵$L$其所对应的基$u_l$上的分量、“信息”越少,那么当然就是可以忽略的低频部分了。
其实图像压缩就是这个原理,把像素矩阵特征分解后,把小的特征值(低频部分)全部变成0,PCA降维也是同样的,把协方差矩阵特征分解后,按从大到小取出前K个特征值对应的特征向量作为新的“坐标轴”。
Graph Convolution的理论告一段落了,下面开始Graph Convolution Network
Deep Learning中的Graph Convolution
Deep learning 中的Graph Convolution直接看上去会和第6节推导出的图卷积公式有很大的不同,但是万变不离其宗,$({31})$式是推导的本源。
第1节的内容已经解释得很清楚:Deep learning 中的Convolution就是要设计含有trainable共享参数的kernel,从$({31})$式看很直观:graph convolution中的卷积参数就是 $diag(\hat h(\lambda_l) )$。
第一代GCN
Spectral Networks and Locally Connected Networks on Graphs中简单粗暴地把$diag(\hat h(\lambda_l) )$变成了卷积核$diag(\theta_l )$,也就是:
其中,$g_\theta(\Lambda)=\left(\begin{matrix}\theta_1 &\\&\ddots \\ &&\theta_n \end{matrix}\right)$,$\Lambda$仅仅表示对角矩阵,没有特殊的含义。
式$({36})$就是标准的第一代GCN中的layer了,其中$\sigma(\cdot)$是激活函数,$\Theta=({\theta_1},{\theta_2},\cdots,{\theta_n})$就跟三层神经网络中的weight一样是任意的参数,通过初始化赋值然后利用误差反向传播进行调整,$x$就是graph上对应于每个顶点的feature vector(由特数据集提取特征构成的向量)。
第一代的参数方法存在着一些弊端:主要在于:
(1)每一次前向传播,都要计算 $U$,$diag(\theta_l )$ 及$U^T$三者的矩阵乘积,特别是对于大规模的graph,计算的代价较高,也就是论文中$\mathcal{O}(n^2)$的计算复杂度
(2)卷积核的spatial localization不好(这个在第9节中进一步阐述)
(3)卷积核需要$n$个参数
由于以上的缺点第二代的卷积核设计应运而生。
第二代GCN
(Convolutional Neural Networks on Graphs with Fast Localized Spectral Filtering),把 $\hat h(\lambda_l)$巧妙地设计成了 $\sum_{j=0}^K \alpha_j \lambda^j_l$(原始定义为:$\hat{h}(\lambda_l)=\sum_{i=1}^{N}{h(i) u_l^*(i)}$),也就是:
其中,$ g_\theta(\Lambda)=\left(\begin{matrix}\sum_{j=0}^K \alpha_j \lambda^j_1 &\\&\ddots \\ && \sum_{j=0}^K \alpha_j \lambda^j_n \end{matrix}\right)$,$\Lambda$仅仅表示对角矩阵,没有特殊的含义。$\lambda_l^j$表示特征值$\lambda_l$的$j$次方。
上面的公式仿佛还什么都看不出来,下面利用矩阵乘法进行变换,来一探究竟。
其中,$\Lambda$为对角矩阵,对角线元素分别为$\lambda_1,\lambda_2,…,\lambda_n$,而$\Lambda^j$也为对角矩阵,每一个元素分别为$\lambda_1,\lambda_2,…,\lambda_n$的$j$次方。而前面$\sum_{j=0}^K \alpha_j$为常数,两者相乘的结果为该常数乘以矩阵的每一个值,所以等于左边。
进而可以导出:
上式成立是因为$L^2=U \Lambda U^TU \Lambda U^T=U \Lambda^2 U^T $ 且 $U^T U=E$,由此可以扩展到$L^j$的情况。
各符号的定义都同第五节。
式$({40})$就变成了:
其中$({\alpha_1},{\alpha_2},\cdots,{\alpha_K})$ 是任意的参数,通过初始化赋值然后利用误差反向传播进行调整;$L^j$为矩阵$L$的$j$次方。
式$({40})$所设计的卷积核其优点在于在于:
(1)卷积核只有$K$个参数,一般 $K$远小于 $n$,参数的复杂度被大大降低了。
(2)矩阵变换后,神奇地发现不需要做特征分解了,直接用拉普拉斯矩阵$L$进行变换。然而由于要计算$L^j$,计算复杂度还是$\mathcal{O}(n^2)$
(3)卷积核具有很好的spatial localization,特别地,$K$就是卷积核的receptive field,也就是说每次卷积会将中心顶点K-hop neighbor上的feature进行加权求和,权系数就是$\alpha_k$
更直观地看, _K_=1就是对每个顶点和其一阶neighbor的feature进行加权求和,如下图所示:

说明:因为当$K=1$的时候,卷积部分就相当于$\alpha L x$,而从$L$矩阵的形式,可以看出拉普拉斯矩阵只在中心顶点和一阶相连的顶点上(1-hop neighbor)有非0元素,其余之处均为0。所以就相当于对每个顶点和其一阶neighbor的feature进行加权求和,也就有了局部感知的能力。另外,拉普拉斯矩阵每一行之和均为0,对角线上的元素等于同一行其余元素之和,这可以看出Graph上的卷积本质:某一顶点在所有相邻节点上进行微小变化后获得的增益。因为卷积中有参数$\alpha$是可以通过反向传播计算出来的,所以$L$中的系数并不能说明什么,只是不管乘以什么形式的$\alpha$其0元素的位置始终为0元素。
同理,_K_=2的情形如下图所示:

说明:
所以当$K=2$的时候,卷积部分相当于$\left( \sum_{j=0}^2 \alpha_j L^j x \right)$,从上面的$L+L^2$可以看出,只有其顶点和二阶相连的顶点上(2-hop neighbor)有非0元素,其余之处均为0。所以就相当于对每个顶点和其二阶neighbor的feature进行加权求和,也就有了局部感知的能力。因为卷积中有参数$\alpha$是可以通过反向传播计算出来的,所以$L+L^2$中的系数并不能说明什么,只是不管乘以什么形式的$\alpha$其0元素的位置始终为0元素。
上图只是以一个顶点作为实例,GCN每一次卷积对所有的顶点都完成了图示的操作。spatial convolution, 就是图上node只和邻接点加权,但是这里主要讨论的是spectral convolution,是在无向图的spectral space 做卷积,signal是长度为n的vector, filter也是长度为n的vector。
利用Chebyshev多项式递归计算卷积核
在第二代GCN中, $L$ 是 $n\times n$ 的矩阵,所以$L^j$ 的计算还是 $\mathcal{O}(n^2) $复杂的,Wavelets on graphs via spectral graph theory提出了利用Chebyshev多项式拟合卷积核的方法,来降低计算复杂度。卷积核 $g_\theta(\Lambda)$ 可以利用截断(truncated)的shifted Chebyshev多项式来逼近。(这里本质上应该寻找Minimax Polynomial Approximation,但是作者说直接利用Chebyshev Polynomial的效果也很好)
$\beta\in \mathbb{R}^{K} $表示一个切比雪夫向量,$\beta_k$ 是Chebyshev多项式的系数(标量);$T_k(\tilde{\Lambda})$ 是取 $\tilde{\Lambda}=2\Lambda/\lambda_{max}-I$ 的Chebyshev多项式,进行这个shift变换的原因是Chebyshev多项式的输入要在 $\left[ -1,1\right]$ 之间。
由Chebyshev多项式的性质,可以得到如下的递推公式
其中, $x$ 的定义同上,是$ n$ 维的由每个顶点的特征构成的向量(当然,也可以是$ n*m $的特征矩阵,这时每个顶点都有 $m $个特征,但是$ m $通常远小于$ n$ )。
这个时候不难发现:式$({42})$的运算不再有矩阵乘积了,只需要计算矩阵与向量的乘积即可。计算一次$ T_k (\tilde{\Lambda})x $的复杂度是$ \mathcal{O}(\left| E \right|)$ ,$ E $是图中边的集合,则整个运算的复杂度是$ \mathcal{O}(K\left | E \right|) $。当Graph是稀疏图的时候,计算加速尤为明显,这个时候复杂度远低于$ \mathcal{O}(n^2)$
$T_{k}(\tilde{\Lambda})$是 $\Lambda$的$k$ 阶多项式,且$UU^T=I$,所以有
其中, $\tilde{L}=\frac{2}{\lambda_{max}}L-I$ 。
$k$阶多项式表达式:$f(x, \theta)=\sum_{k=0}^{K} x^{k} \theta_{k}=\phi(x)^{T} \theta$,其中$\phi(x)=\left[1, x, x^{2}, \cdots, x^{K}\right]^{T} \in \mathbb{R}^{K+1}$,$\theta=\left[\theta_{0}, \cdots, \theta_{K}\right]^{T} \in \mathbb{R}^{K+1}$。
可以看出来,对于$k$ 阶多项式$T_{k}(\tilde{\Lambda})$中的第$k$项左乘矩阵$U$右乘矩阵$U^T$都对应$k$ 阶多项式$T_{k}(\tilde{L})$中的第$k$项,所以可以得到Graph卷积式子:
总结
上面的讲述是GCN最基础的思路,均是改变了卷积核的傅里叶变换的形式。很多论文中的GCN结构是在上述思路的基础上进行了一些简单数学变换。理解了上述内容,就可以做到“万变不离其宗”。
GCN中的Local Connectivity和Parameter Sharing
CNN中有两大核心思想:网络局部连接,卷积核参数共享。
那么我们不禁会联想:这两点在GCN中是怎样的呢?以下图的graph结构为例来探究一下
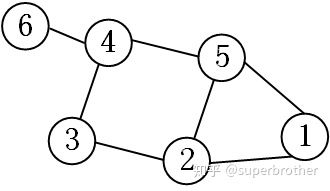
GCN中的Local Connectivity
(a)如果利用第一代GCN,根据式$({36})$卷积核即为

这个时候,可以发现这个卷积核没有local的性质,因为所有位置上都有非0元素。以第一个顶点为例,如果考虑一阶local关系的话,那么卷积核中第一行应该只有$[1,1],[1,2],[1,5]$这三个位置的元素非0。换句话说,这是一个global全连接的卷积核。
如果是第二代GCN,根据式$({40})$当$K=1$积核即为

当 $K=2$卷积核即为
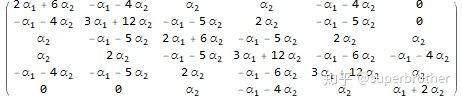
看一下图的邻接结构,卷积核的非0元素都在localize的位置上。
GCN中的Parameter Sharing
总结
和图像中的离散卷积运算本质为加权求和相同,在Graph上的运算本质也为加权求和;而图像中的离散卷积物理含义是提取图像不同『频段』的特征。,而在Graph上的物理含义为某一顶点在所有相邻节点上进行微小变化后获得的增益(从拉普拉斯矩阵$L$的每一行之和均为零和Graph上卷积的表达式可以看出来)。
其他GCN
关于有向图的问题
前面的叙述都是关于无向图的GCN,如果是有向图问题,最大的区别就是邻接矩阵会变成非对称矩阵,这个时候不能直接定义拉普利矩阵及其谱分解(拉普拉斯矩阵本身是定义在无向图上的)。这个时候有两条思路解决问题。
(a)重新定义图的邻接关系,保持对称性
比如MotifNet: a motif-based Graph Convolutional Network for directed graphs 提出利用Graph Motifs定义图的邻接关系。
(b)绕开利用拉普利矩阵计算GCN的方法
关于边特征处理
大多数都是针对node feature进行处理,而如果要处理edge feature,查看THOMAS KIPF的论文
疑惑
- CNN中的平移不变形
- 拉普拉斯变换(二阶导)和傅里叶变换有什么关联,为啥拉普拉斯变换的特征函数就可以作为傅里叶变换的基?
- Graph上的傅里叶逆变换和Graph上的卷积定理均缺乏推导
- Graph上的频率的含义,与特征值之间的关系
- 式子$({36})$中$x$的具体含义
- Graph上卷积的物理含义
- 切比雪夫的递推公式
- 卷积核的傅里叶变换为何是矩阵,不应该是向量么?
参考
图拉普拉斯算子为何定义为D-W
混合偏导数怎么算?
正交矩阵
GRAPH CONVOLUTIONAL NETWORKS
《Semi-Supervised Classification with Graph Convolutional Networks》阅读笔记
(含Python源码)Python实现K阶多项式的5种回归算法(regression)
从图(Graph)到图卷积(Graph Convolution):漫谈图神经网络模型 (一)
从图(Graph)到图卷积(Graph Convolution):漫谈图神经网络模型 (二)
laplacian matrix的几种形式

