错误使用及结果 笔者最先使用时只是了解到了在tensorflow中tf.layers.batch_normalization这个函数,就在函数中直接将其使用,该函数中有一个参数为training,在训练阶段赋值True,在测试阶段赋值False。但是在训练完成后,出现了奇怪的现象时,在training赋值为True时,测试的正确率正常,但是training赋值为False时,测试正确率就很低。上述错误使用过程可以精简为下列代码段
1 2 3 4 5 6 7 8 9 is_traing = tf.placeholder(dtype=tf.bool) input = tf.ones([1 , 2 , 2 , 3 ]) output = tf.layers.batch_normalization(input, training=is_traing) loss = ... train_op = optimizer.minimize(loss) with tf.Session() as sess: sess.run(tf.global_variables_initializer()) sess.run(train_op)
batch_normalization 下面首先粗略的介绍一下batch_normalization,这种归一化方法的示意图和算法如下图,
总的来说就是对于同一batch的input,假设输入大小为[batch_num, height, width, channel],逐channel地计算同一batch中所有数据的mean和variance,再对input使用mean和variance进行归一化,最后的输出再进行线性平移,得到batch_norm的最终结果 。伪代码如下:
1 2 3 4 5 6 7 for i in range(channel): x = input[:,:,:,i] mean = mean(x) variance = variance(x) x = (x - mean) / sqrt(variance) x = scale * x + offset input[:,:,:,i] = x
在实现的时候,会在训练阶段记录下训练数据中平均mean和variance,记为moving_mean和moving_variance,并在测试阶段使用训练时的moving_mean和moving_variance进行计算,这也就是参数training的作用。另外,在实现时一般使用一个decay系数来逐步更新moving_mean和moving_variance,moving_mean = moving_mean decay + new_batch_mean (1 - decay)
tensorflow中的三种实现 tf.nn.batch_normalization(最底层的实现) 1 2 3 4 5 6 7 8 9 tf.nn.batch_normalization( x, mean, variance, offset, scale, variance_epsilon, name=None )
该函数是一种最底层的实现方法,在使用时mean、variance、scale、offset等参数需要自己传递并更新,因此实际使用时还需自己对该函数进行封装,一般不建议使用,但是对了解batch_norm的原理很有帮助。
封装使用的实例如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 import tensorflow as tfdef batch_norm (x, name_scope, training, epsilon=1e-3 , decay=0.99 ) : """ Assume nd [batch, N1, N2, ..., Nm, Channel] tensor""" with tf.variable_scope(name_scope): size = x.get_shape().as_list()[-1 ] scale = tf.get_variable('scale' , [size], initializer=tf.constant_initializer(0.1 )) offset = tf.get_variable('offset' , [size]) pop_mean = tf.get_variable('pop_mean' , [size], initializer=tf.zeros_initializer(), trainable=False ) pop_var = tf.get_variable('pop_var' , [size], initializer=tf.ones_initializer(), trainable=False ) batch_mean, batch_var = tf.nn.moments(x, list(range(len(x.get_shape())-1 ))) train_mean_op = tf.assign(pop_mean, pop_mean * decay + batch_mean * (1 - decay)) train_var_op = tf.assign(pop_var, pop_var * decay + batch_var * (1 - decay)) def batch_statistics () : with tf.control_dependencies([train_mean_op, train_var_op]): return tf.nn.batch_normalization(x, batch_mean, batch_var, offset, scale, epsilon) def population_statistics () : return tf.nn.batch_normalization(x, pop_mean, pop_var, offset, scale, epsilon) return tf.cond(training, batch_statistics, population_statistics) is_traing = tf.placeholder(dtype=tf.bool) input = tf.ones([1 , 2 , 2 , 3 ]) output = batch_norm(input, name_scope='batch_norm_nn' , training=is_traing) with tf.Session() as sess: sess.run(tf.global_variables_initializer()) saver = tf.train.Saver() saver.save(sess, "batch_norm_nn/Model" )
在batch_norm中,首先先计算了x的逐通道的mean和var,然后将pop_mean和pop_var进行更新,并根据是在训练阶段还是测试阶段选择将当批次计算的mean和var或者训练阶段保存的mean和var与新定义的变量scale和offset一起传递给tf.nn.batch_normalization
tf.layers.batch_normalization 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 tf.layers.batch_normalization( inputs, axis=-1 , momentum=0.99 , epsilon=0.001 , center=True , scale=True , beta_initializer=tf.zeros_initializer(), gamma_initializer=tf.ones_initializer(), moving_mean_initializer=tf.zeros_initializer(), moving_variance_initializer=tf.ones_initializer(), beta_regularizer=None , gamma_regularizer=None , beta_constraint=None , gamma_constraint=None , training=False , trainable=True , name=None , reuse=None , renorm=False , renorm_clipping=None , renorm_momentum=0.99 , fused=None , virtual_batch_size=None , adjustment=None )
该函数也就是笔者之前使用的函数,在官方文档中写道
Note: when training, the moving_mean and moving_variance need to be updated. By default the update ops are placed in tf.GraphKeys.UPDATE_OPS, so they need to be added as a dependency to the train_op. Also, be sure to add any batch_normalization ops before getting the update_ops collection. Otherwise, update_ops will be empty, and training/inference will not work properly. For example:
1 2 3 4 5 6 7 x_norm = tf.layers.batch_normalization(x, training=training) update_ops = tf.get_collection(tf.GraphKeys.UPDATE_OPS) with tf.control_dependencies(update_ops): train_op = optimizer.minimize(loss)
可以看到,与笔者之前的错误实现方法的差异主要在
1 2 update_ops = tf.get_collection(tf.GraphKeys.UPDATE_OPS) with tf.control_dependencies(update_ops):
这两句话,同时可以看到在第一种方法tf.nn.batch_normalization的封装过程中也用到了类似的处理方法,具体会在下一段进行说明。
tf.contrib.layers.batch_norm(slim) 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 tf.contrib.layers.batch_norm( inputs, decay=0.999 , center=True , scale=False , epsilon=0.001 , activation_fn=None , param_initializers=None , param_regularizers=None , updates_collections=tf.GraphKeys.UPDATE_OPS, is_training=True , reuse=None , variables_collections=None , outputs_collections=None , trainable=True , batch_weights=None , fused=None , data_format=DATA_FORMAT_NHWC, zero_debias_moving_mean=False , scope=None , renorm=False , renorm_clipping=None , renorm_decay=0.99 , adjustment=None )
这种方法与tf.layers.batch_normalization的使用方法差不多,两者最主要的差别在参数scale和centre的默认值上,这两个参数即是我们之前介绍原理时所说明的对input进行mean和variance的归一化之后采用的线性平移中的scale和offset,可以看到offset的默认值两者都是True,但是scale的默认值前者为True后者为False,也就是说明在tf.contrib.layers.batch_norm中,默认不对处理后的input进行线性缩放,只是加一个偏移。
关于tf.GraphKeys.UPDATA_OPS 首先我们先介绍tf.control_dependencies,该函数保证其辖域中的操作必须要在该函数所传递的参数中的操作完成后再进行。请看下面一个例子。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 import tensorflow as tfa_1 = tf.Variable(1 ) b_1 = tf.Variable(2 ) update_op = tf.assign(a_1, 10 ) add = tf.add(a_1, b_1) a_2 = tf.Variable(1 ) b_2 = tf.Variable(2 ) update_op = tf.assign(a_2, 10 ) with tf.control_dependencies([update_op]): add_with_dependencies = tf.add(a_2, b_2) with tf.Session() as sess: sess.run(tf.global_variables_initializer()) ans_1, ans_2 = sess.run([add, add_with_dependencies]) print("Add: " , ans_1) print("Add_with_dependency: " , ans_2) 输出: Add: 3 Add_with_dependency: 12
可以看到两组加法进行的对比,正常的计算图在计算add时是不会经过update_op操作的,因此在加法时a的值为1,但是采用tf.control_dependencies函数,可以控制在进行add前先完成update_op的操作,因此在加法时a的值为10,因此最后两种加法的结果不同。
tf.GraphKeys.UPDATE_OPS 关于tf.GraphKeys.UPDATE_OPS,这是一个tensorflow的计算图中内置的一个集合,其中会保存一些需要在训练操作之前完成的操作,并配合tf.control_dependencies函数使用。
关于在batch_norm中,即为更新mean和variance的操作。通过下面一个例子可以看到tf.layers.batch_normalization中是如何实现的。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 import tensorflow as tfis_traing = tf.placeholder(dtype=tf.bool) input = tf.ones([1 , 2 , 2 , 3 ]) output = tf.layers.batch_normalization(input, training=is_traing) update_ops = tf.get_collection(tf.GraphKeys.UPDATE_OPS) print(update_ops) with tf.Session() as sess: sess.run(tf.global_variables_initializer()) saver = tf.train.Saver() saver.save(sess, "batch_norm_layer/Model" ) 输出: [<tf.Tensor 'batch_normalization/AssignMovingAvg:0' shape=(3 ,) dtype=float32_ref>, <tf.Tensor 'batch_normalization/AssignMovingAvg_1:0' shape=(3 ,) dtype=float32_ref>]
可以看到输出的即为两个batch_normalization中更新mean和variance的操作,需要保证它们在train_op前完成。
这两个操作是在tensorflow的内部实现中自动被加入tf.GraphKeys.UPDATE_OPS这个集合的,在tf.contrib.layers.batch_norm的参数中可以看到有一项updates_collections的默认值即为tf.GraphKeys.UPDATE_OPS,而在tf.layers.batch_normalization中则是直接将两个更新操作放入了上述集合。
关于最初的错误使用的思考 最后我对于一开始的使用方法为什么会导致错误进行了思考,tensorflow中具体实现batch_normalization的代码在tensorflow\python\layers\normalization.py中,下面展示一些关键代码。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 if self.scale: self.gamma = self.add_variable( name='gamma' , shape=param_shape, dtype=param_dtype, initializer=self.gamma_initializer, regularizer=self.gamma_regularizer, constraint=self.gamma_constraint, trainable=True ) else : self.gamma = None if self.center: self.beta = self.add_variable( name='beta' , shape=param_shape, dtype=param_dtype, initializer=self.beta_initializer, regularizer=self.beta_regularizer, constraint=self.beta_constraint, trainable=True ) else : self.beta = None scale, offset = _broadcast(self.gamma), _broadcast(self.beta) self.moving_mean = self._add_tower_local_variable( name='moving_mean' , shape=param_shape, dtype=param_dtype, initializer=self.moving_mean_initializer, trainable=False ) self.moving_variance = self._add_tower_local_variable( name='moving_variance' , shape=param_shape, dtype=param_dtype, initializer=self.moving_variance_initializer, trainable=False ) def _assign_moving_average (self, variable, value, momentum) : with ops.name_scope(None , 'AssignMovingAvg' , [variable, value, momentum]) as scope: decay = ops.convert_to_tensor(1.0 - momentum, name='decay' ) if decay.dtype != variable.dtype.base_dtype: decay = math_ops.cast(decay, variable.dtype.base_dtype) update_delta = (variable - value) * decay return state_ops.assign_sub(variable, update_delta, name=scope) def _do_update (var, value) : return self._assign_moving_average(var, value, self.momentum) training_value = utils.constant_value(training) if training_value is not False : mean, variance = nn.moments(inputs, reduction_axes, keep_dims=keep_dims) moving_mean = self.moving_mean moving_variance = self.moving_variance mean = utils.smart_cond(training, lambda : mean, lambda : moving_mean) variance = utils.smart_cond(training, lambda : variance, lambda : moving_variance) else : new_mean, new_variance = mean, variance mean_update = utils.smart_cond( training, lambda : _do_update(self.moving_mean, new_mean), lambda : self.moving_mean) variance_update = utils.smart_cond( training, lambda : _do_update(self.moving_variance, new_variance), lambda : self.moving_variance) if not context.executing_eagerly(): self.add_update(mean_update, inputs=inputs) self.add_update(variance_update, inputs=inputs) outputs = nn.batch_normalization(inputs, _broadcast(mean), _broadcast(variance), offset, scale, self.epsilon)
可以看到其内部逻辑和我在介绍tf.nn.batch_normalization一节中展示的封装时所使用的方法类似。
如果不在使用时添加tf.control_dependencies函数,即在训练时(training=True)每批次时只会计算当批次的mean和var,并传递给tf.nn.batch_normalization进行归一化,由于mean_update和variance_update在计算图中并不在上述操作的依赖路径上,因为并不会主动完成,也就是说,在训练时mean_update和variance_update并不会被使用到,其值一直是初始值。因此在测试阶段(training=False)使用这两个作为mean和variance并进行归一化操作,这样就会出现错误。而如果使用tf.control_dependencies函数,会在训练阶段每次训练操作执行前被动地去执行mean_update和variance_update,因此moving_mean和moving_variance会被不断更新,在测试时使用该参数也就不会出现错误。
从checkpoint文件恢复权重预测 第一种 关于这个例子可以参考https://github.com/tensorflow/models/tree/master/research/slim/nets/mobilenet
预测时比较特别,因为这一步一般都是从checkpoint文件中读取模型参数,然后做预测。一般来说,保存checkpoint的时候,不会把所有模型参数都保存下来,因为一些无关数据会增大模型的尺寸,常见的方法是只保存那些训练时更新的参数(可训练参数),如下:
1 2 var_list = tf.trainable_variables() saver = tf.train.Saver(var_list=var_list, max_to_keep=5 )
但使用了batch_normalization,γ和β是可训练参数没错,μ和σ不是,它们仅仅是通过滑动平均计算出的,如果按照上面的方法保存模型,在读取模型预测时,会报错找不到μ和σ。更诡异的是,利用tf.moving_average_variables()也没法获取bn层中的μ和σ(也可能是我用法不对),不过好在所有的参数都在tf.global_variables()中,因此可以这么写:
1 2 3 4 5 6 var_list = tf.trainable_variables() g_list = tf.global_variables() bn_moving_vars = [g for g in g_list if 'moving_mean' in g.name] bn_moving_vars += [g for g in g_list if 'moving_variance' in g.name] var_list += bn_moving_vars saver = tf.train.Saver(var_list=var_list, max_to_keep=5 )
按照上述写法,即可把μ和σ保存下来,读取模型预测时也不会报错,当然输入参数training=False还是要的。
注意上面有个不严谨的地方,因为我的网络结构中只有bn层包含moving_mean和moving_variance,因此只根据这两个字符串做了过滤,如果你的网络结构中其他层也有这两个参数,但你不需要保存,建议使用诸如bn/moving_mean的字符串进行过滤。
建议: 保存权重的时候保存模型的全部参数。
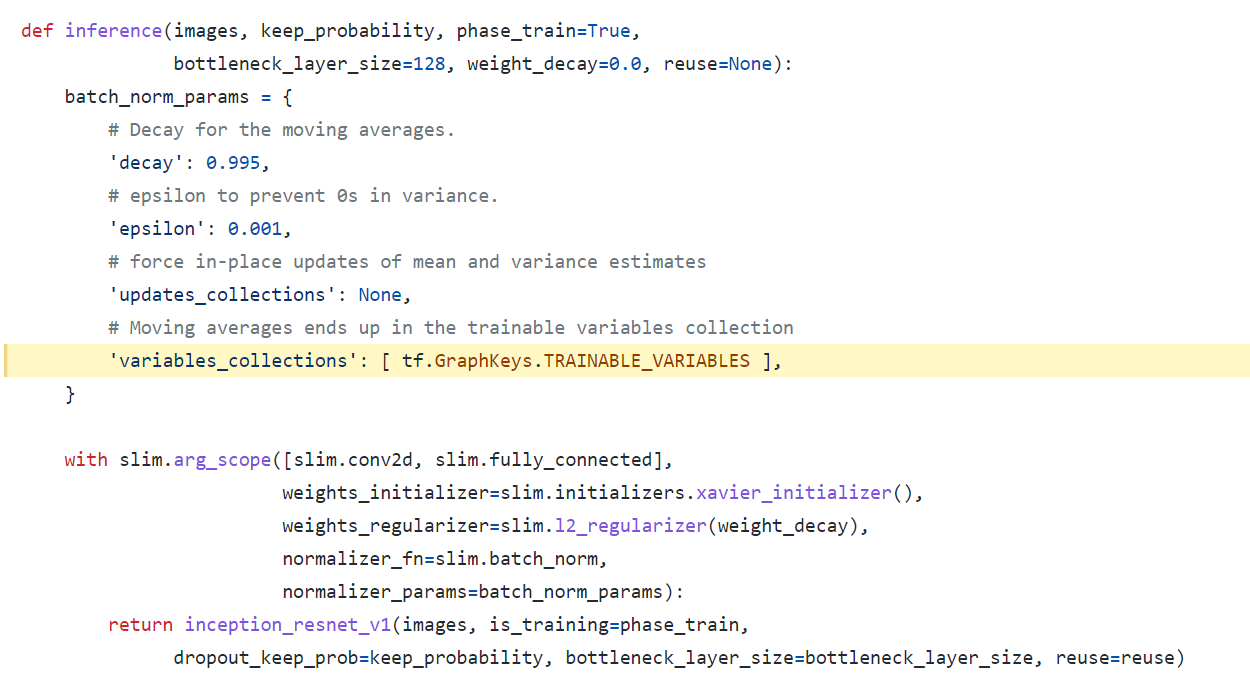
第二种 最近关于tf.train.Saver能不能只保存tf.trainable_variables()进行了研究,TensorFlow版本是1.15.5,仓库是https://github.com/davidsandberg/facenet,加载模型之后
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 ori_model_path = 'checkpoints/20180408-102900/model-20180408-102900' config = tf.ConfigProto(gpu_options=tf.GPUOptions(allow_growth=True )) with tf.Session(config=config) as sess: saver_ori = tf.train.import_meta_graph(ori_model_path+'.meta' ) saver_ori.restore(sess, ori_model_path+'.ckpt-90' ) graph = sess.graph aa = [g for g in tf.global_variables() if 'BatchNorm' in g.name] bb = [g for g in tf.trainable_variables() if 'BatchNorm' in g.name] ori_train_vars = tf.trainable_variables() for x in aa: if x not in bb: print(x) for x in aa: if x not in bb and 'ExponentialMovingAverage' not in x.name and 'Adam' not in x.name: print(x)
结果显示aa的长度为896,而bb的长度336。第一个print的输出结果都含有ExponentialMovingAverage和Adam字样,第二个print没有输出了。
查看bb变量,发现beta、moving_mean和moving_variance都在这里面了,也就是这些变量都在tf.trainable_variables(),与上一小节的结果有点相反。查看该仓库的源代码,可以发现这里 。有如下代码,应该是把这些参数填充进去了。normalizer_fn=slim.batch_norm会填充到slim.conv2d中,也就是slim.conv2d会包含了BN层。
再添加保存代码:
1 2 3 4 5 6 saver_final = tf.train.Saver() saver_final.save(sess, 'checkpoints/facenet_merge_model/merge_model' ) saver_final = tf.train.Saver(ori_train_vars) saver_final.save(sess, 'checkpoints/facenet_merge_model/merge_model' )
总而言之,关于BN层的处理还是要谨慎点。
参考 tensorflow中的batch_norm以及tf.control_dependencies和tf.GraphKeys.UPDATE_OPS的探究 tensorflow中tf.layers.batch_normalization()的坑及注意事项