之前没有接触过NLP,所以不太理解里面的基本名词。所以这里学习一些NLP的基本概念。事先声明,以下大部分内容来源于第1章-自然语言处理基础概念和easyai的《非技术也能看懂的NLP入门科普》。不理解的地方我会加上自己的批注。
自然语言
自然语言是指汉语、英语、法语等人们日常使用的语言,是自然而然的随着人类社会发展演变而来的语言,区别于如程序设计的语言的人工语言。
语音和文字是构成语言的两个基本属性,语音是语言的物质外壳,文字则是记录语言的书写符号系统。
自然语言与编程语言的对比
词汇量
自然语言的词汇量的丰富程度远远超过编程语言 。例如,C 语言共有 32 个关键字,Java 有 52 个;而中文目前大约有五万多个词条,并且仍在不断增加。
结构化
自然语言是非结构化 的,而编程语言是结构化的 。结构化指的是信息具有明确的结构关系,可以通过明确的机制来读写 。例如,Python 用 apple.funder='乔布斯' 可以明确读取苹果公司的创始人,而中文我们可以说 苹果公司的创世人是乔布斯,可以说 乔布斯是苹果公司的创始人,还可以说 只有乔布斯才可以称得上苹果公司的创始人…
编程语言通过极少的词汇量 + 极强的结构化实现了各式各样的程序代码。 自然语言通过极多的词汇量 + 极弱的结构化实现了五花八门的表达方式。
歧义性
自然语言中可能存在大量的歧义,而这些歧义在不同的语境下可能表现为不同的意思 ,举一个经典的笑话:
他说:“她这个人真有意思(funy)。”她说:“他这个人怪有意思的(funy)。”于是人们以为他们有了意思(wish),并让他向她意思意思(express)。他火了:“我根本没有那个意思(thought)!”她也生气了:“你们这么说是什么意思(Intention)?”事后有人说:“真有意思(funny)。”也有人说:“真没意思(nonsense)。”
而机器所处理的编程语言则不能具有任何歧义 ,有一点歧义就会导致代码的运行错误、编译错误。
容错性
自然语言在使用中可能会出现很多错误 ,例如拼写错误、语法错误、顺序错误、发音错误等,而我们人类基本都可以理解这些有一些小错误的文本。但计算机对于编程语言的要求则是绝对正确 。

易变性
任何语言都不是一成不变的,例如,汉语每年会产生大量的新词汇,而编程语言 C++ 几乎每隔很多年才会修订一次。
简略性
人类语言往往简洁、干练 。我们经常省略大量背景知识或常识,比如我们会对朋友说“老地方见” ,而不必指出“ 老地方” 在哪里。对于机构名称,我们经常使用简称,比如“工行” “地税局” ,假定对方熟悉该简称。
总结
首先记住一条原则:计算机对编程语言要求绝对精准无误,而自然语言非常灵活随意 。自然语言处理工作重点就是解决这个矛盾。
| 自然语言 | 编程语言 | |
|---|---|---|
| 词汇量 | 极多 | 极少 |
| 结构化 | 极弱 | 极强 |
| 歧义性 | 极强 | 极弱 |
| 容错性 | 极强 | 极弱 |
| 易变性 | 极强 | 极弱 |
| 简略性 | 极强 | 极弱 |
自然语言处理
自然语言处理(Natural Language Processing : NLP) ,就是利用计算机为工具对人类特有的书面形式和口头形式的自然语言的信息进行各种类型处理和加工的技术。——冯志伟《自然语言的计算机处理》 1996
自然语言处理(NLP)分为自然语言理解(NLU)和自然语言生成(NLG)。翻译任务属于NLG。

自然语言理解(NLU)就是希望机器像人一样,具备正常人的语言理解能力,由于自然语言在理解上有很多难点(下面详细说明),所以NLU是至今还远不如人类的表现。
自然语言理解的5个难点:
- 语言的多样性
- 语言的歧义性
- 语言的鲁棒性
- 语言的知识依赖
- 语言的上下文
自然语言生成(NLG)是为了跨越人类和机器之间的沟通鸿沟,将非语言格式的数据转换成人类可以理解的语言格式,如文章、报告等。
自然语言处理任务流程
按照处理对象的颗粒度,自然语言处理的任务大致可以分为图所示的几个层次:
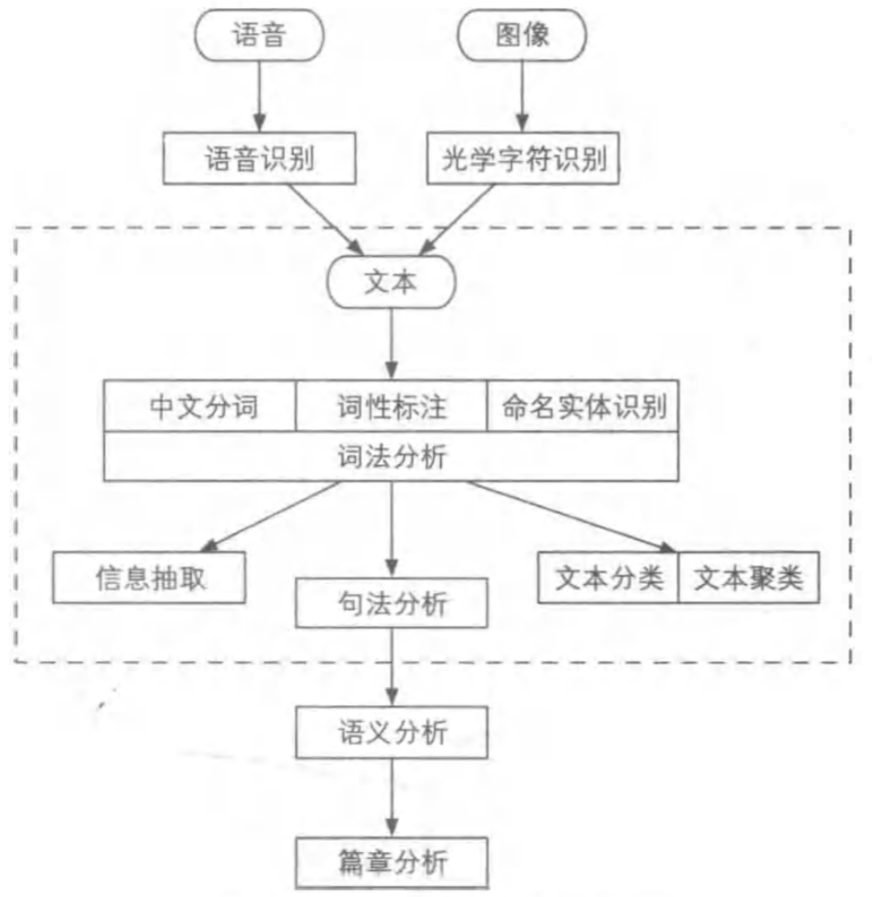
自然语言处理的数据类型
自然语言处理系统的输入源一共有 3 个 ,即语音、图像与文本 。其中文本处理是重中之重 ,其他两种数据最后也一般先要转化为文本才能进行后续的处理任务 ,对应的处理分别为语音识别(Speech Recognition)和光学字符识别(Optical Character Recognition,OCR)。
英文 NLP 语料预处理的6个步骤

- 分词-Tokenization
- 词干提取-Stemming
- 词形还原-Lemmatization
- 词性标注-Parts of Speech
- 命名实体识别-NER
- 分块-Chunking
分词-Tokenization
分词是NLP的基础任务,将句子,段落分解为字词单位,方便后续的处理的分析。
接下来我们将介绍分词的原因,中英文分词的3个区别,中文分词的3大难点,分词的3种典型方法。最后将介绍中文分词和英文分词常用的工具。
什么是分词
分词是NLP的重要步骤。分词就是将句子、段落、文章这种长文本,分解为以字词为单位的数据结构,方便后续的处理分析工作。

为什么要分词
- 将复杂问题转化为数学问题:机器学习之所以可以解决很多复杂的问题,是因为它把这些问题都转化为了数学问题。而NLP也是相同的思路,文本都是一些「非结构化数据」,我们需要先将这些数据转化为「结构化数据」,结构化数据就可以转化为数学问题了,而分词就是转化的第一步。

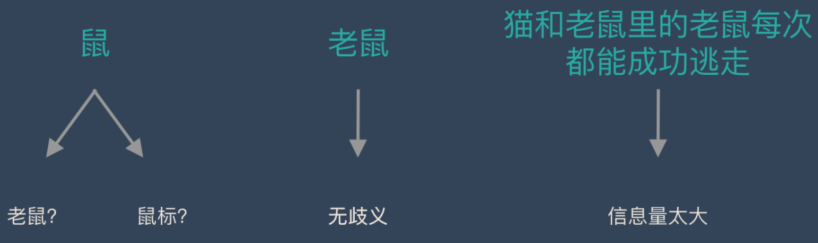
词是一个比较合适的粒度词是表达完整含义的最小单位。
字的粒度太小,无法表达完整含义,比如”鼠“可以是”老鼠”,也可以是”鼠标”。而句子的粒度太大,承载的信息量多,很难复用。比如”传统方法要分词,一个重要原因是传统方法对远距离依赖的建模能力较弱。
而在深度学习时代,虽然数据量和算力大幅度增长,但是大部分还是需要分词的。对于不分词的例子可以看文章 《Is Word Segmentation Necessary for Deep Learning of Chinese Representations?》。
中英文分词的3个典型区别

区别1:分词方式不同,中文更难。英文有天然的空格作为分隔符,但是中文没有。所以如何切分是一个难点,再加上中文里一词多意的情况非常多,导致很容易出现歧义。下文中难点部分会详细说明。
区别2:英文单词有多种形态。英文单词存在丰富的变形变换。为了应对这些复杂的变换,英文NLP相比中文存在一些独特的处理步骤,我们称为词形还原(Lemmatization)和词干提取(Stemming) 。中文则不需要。
词性还原:does,done,doing,did需要通过词性还原恢复成do。
词干提取:cities,children,teeth这些词,需要转换为city,child,tooth这些基本形态。
区别3:中文分词需要考虑粒度问题例如「中国科学技术大学」就有很多种分法:
- 中国科学技术大学
- 中国、科学技术、大学
- 中国、科学、技术、大学
粒度越大,表达的意思就越准确,但是也会导致召回比较少。所以中文需要不同的场景和要求选择不同的粒度。这个在英文中是没有的。
中文分词的三大难点

难点1:没有统一的标准目前中文分词没有统一的标准,也没有公认的规范。不同的公司和组织各有各的方法和规则。
难点2:歧义词如何切分例如「兵乓球拍卖完了」就有2种分词方式表达了2种不同的含义:
- 乒兵球\拍卖\完了
- 乒兵\球拍\卖完了
难点3:新词的识别信息爆炸的时代,三天两头就会冒出来一堆新词。如何快速的识别出这些新词是一大难点。比如当年「蓝瘦香菇」大火,就需要快速识别。
三种典型的分词方法
分词的方法大致分为3类:
- 基于词典匹配
- 基于统计
- 基于深度学习
基于词典匹配的分词方式
优点:速度快、成本低
缺点:适应性不强,不同领域效果差异大
基本思想是基于词典匹配,将待分词的中文文本根据一定规则切分和调整,然后跟词典中的词语进行匹配,匹配成功则按照词典的词分词,匹配失败通过调整或者重新选择,如此反复循环即可。代表方法有基于正向最大匹配和基于逆向最大匹配及双向匹配法。
基于统计的分词方法
优点:适应性较强
缺点:成本较高,速度较慢
这类目前常用的是算法是HMM、CRF、SVM、深度学习等算法,比如stanford、Hanlp分词工具是基于CRF算法。以CRF为例,基本思路是对汉字进行标注训练,不仅考虑了词语出现的频率,还考虑上下文,具备较好的学习能力,因此其对歧义词和未登录词的识别都具有良好的效果。
基于深度学习
优点:准确率高、适应性强
缺点:成本高,速度慢
例如有人员尝试使用双向LSTM+CRF实现分词器,其本质上是序列标注,所以有通用性,命名实体识别等都可以使用该模型,据报道其分词器字符准确率可高达97.5%。
常见的分词器都是使用机器学习算法和词典相结合,一方面能够提高分词准确率,另一方面能够改善领域适应性。
中文分词工具
下面排名根据GitHub上的star数排名:
- Hanlp
- Stanford 分词
- ansj 分词器
- 哈工大LTP
- KCWS分词器
- jieba
- IK
- 清华大学THULAC
- ICTCLAS
英文分词工具
- Spacy
- Gensim
- NLTK
- Moses
这里重点介绍一下Moses,因为它在fairseq库的翻译任务中有使用。Moses它是一个统计机器翻译模型,我们主要使用里面的perl脚本进行数据预处理。所以确保电脑上已经安装配置好了perl(ubuntu自带)。
Moses可以做很多预处理,比如说Normalize punctuation、Tokenizer、Clean corpus、Truecase,这里只介绍Tokenizer:
1 | # 对校验集和测试集做同样的操作 |
词干提取(Stemming) 和词形还原(Lemmatization)
词干提取和词形还原是英文语料预处理中的重要环节。虽然他们的目的一致,但是两者还是存在一些差异。
接下来将介绍他们的概念、异同、实现算法等。
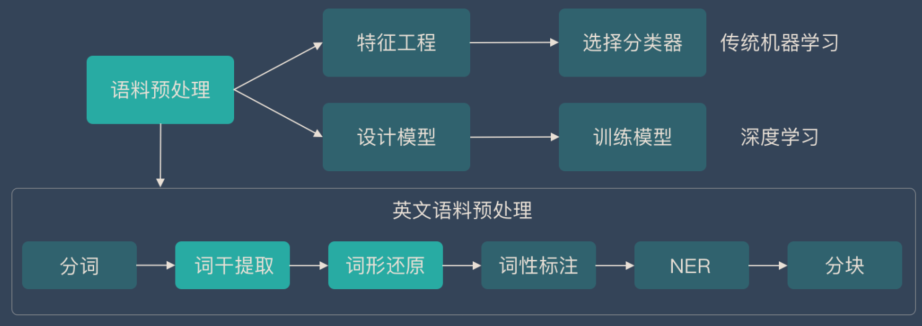
词干提取和词形还原在NLP中在什么位置?
词干提取是英文语料预处理的一个步骤(中文并不需要),而语料预处理是NLP的第一步,下面这张图将让大家知道词干提取和词形还原在这个知识结构中的位置。
词干提取-Stemming
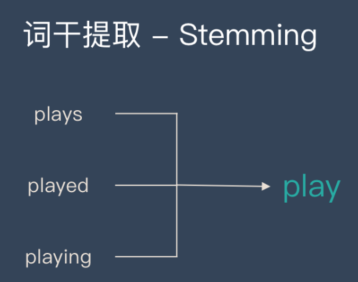
词干提取是去除单词的前后缀得到词根的过程大家常见的前后词缀有「名词的复数」、「进行式」、「过去分词」。
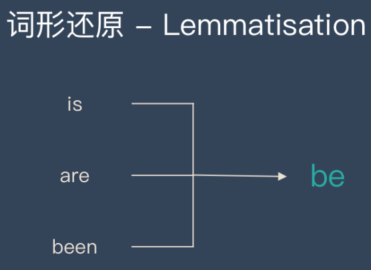
词形还原-Lemmatisation
词形还原是基于词典,将单词的复杂形态转变成最基础的形态。
词形还原不是简单地将前后缀去掉,而是会根据词典将单词进行转换。比如「drove」会转换为「drive」。
为什么要做词干提取和词形还原?
比如当我搜索「play basketball」时,Bob is playing basketball也符合我的要求,但是play和playing对于计算机来说是2种完全不同的东西,所以我们需要将playing转换成play。
词干提取和词形还原的目的就是将长相不同、但是含义相同的词统一起来,这样方便后续的处理和分析。
词干提取和词形还原的4个相似点
- 目标一致。词干提取和词形还原的目标均为将词的屈折形态或派生形态简化或归并为词干(stem)或原形的基础形式,都是一种对词的不同形态的统一归并的过程。
- 结果部分交叉。词干取和词形还原不是互斥关系,其结果是有部分交叉的。一部分词利用这两类方法都能达到相同的词形转换效果。如”dogs”的词干为“dog”,其原形也为”dog”。
- 主流实现方法类似。目前实现词干提取和词形还原的主流实现方法均是利用语言中存在的规则或利用词典映射提取词干或获得词的原形。
- 应用领域相似。主要应用于信息检索和文本、自然语言处理等方面,二者均是这些应用的基本步骤。
词干提取和词形还原的5个不同点
- 在原理上,词干提取主要是采用“缩减“的方法,将词转换为词干,如将“cas“处理为”cat”,将”effective”处理为”effect”。而词形还原主要采用“转变“的方法,将词转变为其原形,如将“drove”处理为”drive”,将”driving”处理为”drive“。
- 在复杂性上,词干提取方法相对简单,词形还原则需要返回词的原形,需要对词形进行分析,不仅要进行词缀的转化,还要进行词性识别,区分相同词形但原形不同的词的差别。词性标注的准确率也直接影响词形还原的准确率,因此,词形还原更为复杂。
- 在实现方法上,虽然词干提取和词形还原实现的主流方法类似,但二者在具体实现上各有侧重。词干提取的实现方法主要利用规则变化进行词缀的去除和缩减,从而达到词的简化效果。词形还原则相对较复杂,有复杂的形态变化,单纯依据规则无法很好地完成。其更依赖于词典,进行词形变化和原形的映射,生成词典中的有效词。
- 在结果上,词干提取和词形还原也有部分区别。词干提取的结果可能并不是完整的、具有意义的词,而只是词的一部分,如“reviva”词干提取的结果为”reviv“,“ailiner“词干提取的结果为“airlin”。而经词形还原处理后获得的结果是具有一定意义的、完整的词,一般为词典中的有效词。
- 在应用领域上,同样各有侧重。虽然二者均被应用于信息检索和文本处理中,但侧重不同。词干提取更多被应用于信息检索领域,如Solr、Lucene等,用于扩展检索,粒度较粗。词形还原更主要被应用于文本挖掘、自然语言处理,用于更细粒度、更为准确的文本分析和表达。
3种主流的词干提取算法
Porter、Snowball(推荐)、lancaster
词形还原的实践方法
词形还原是基于词典的,每种语言都需要经过语义分析、词性标注来建立完整的词库,目前英文词库是很完善的。
Python中的NLTK库包含英语单词的词汇数据库。这些单词基于它们的语义关系链接在一起。链接取决于单词的含义。特别是,我们可以利用WordNet。
1 | import nltk |
词性标注(Part of Speech,POS-Tagging)
什么是词性标注

维基百科上对词性的定义为: In traditional grammar, a part of speech (abbreviated form: PoS or POS) is a category of words (or, more generally, of lexical items) which have similar grammatical properties.
词性指以词的特点作为划分词类的根据。词类是一个语言学术语,是一种语言中词的语法分类,是以语法特征(包括句法功能和形态变化)为主要依据、兼顾词汇意义对词进行划分的结果。
从组合和聚合关系来说,一个词类是指:在一个语言中,众多具有相同句法功能、能在同样的组合位置中出现的词,聚合在一起形成的范畴。词类是最普遍的语法的聚合。词类划分具有层次性。如汉语中,词可以分成实词和虚词,实词中又包括体词、谓词等,体词中又可以分出名词和代词等。
词性标注就是在给定句子中判定每个词的语法范畴,确定其词性并加以标注的过程,这也是自然语言处理中一项非常重要的基础性工作,所有对于词性标注的研究已经有较长的时间,在研究者长期的研究总结中,发现汉语词性标注中面临了许多棘手的问题。
中文词性标注的难点
汉语是一种缺乏词形态变化的语言,词的类别不能像印欧语那样,直接从词的形态变化上来判别。
常用词兼类现象严重。《现代汉语八百词》收取的常用词中,兼类词所占的比例高达22.5%,而且发现越是常用的词,不同的用法越多。由于兼类使用程度高,兼类现象涉及汉语中大部分词类,因而造成在汉语文本中词类歧义排除的任务量巨大。
研究者主观原因造成的困难。语言学界在词性划分的目的、标准等问题上还存在分歧。目前还没有一个统的被广泛认可汉语词类划分标准,词类划分的粒度和标记符号都不统一。
词类划分标准和标记符号集的差异,以及分词规范的含混性,给中文信息处理带来了极大的困难。
词性标注4种常见方法
关于词性标注的研究比较多,这里介绍一波常见的几类方法,包括基于规则的词性标注方法、基于统计模型的词性标注方法、基于统计方法与规则方法相结合的词性标注方法、基于深度学习的词性标注方法等。
基于规则的词性标注方法
基于规则的词性标注方法是人们提出较早的一种词性标注方法,其基本思想是按兼类词搭配关系和上下文语境建造词类消歧规则。早期的词类标注规则一般由人工构建。
随着标注语料库规模的增大,可利用的资源也变得越来越多,这时候以人工提取规则的方法显然变得不现实,于是乎,人们提出了基于机器学习的规则自动提出方法。
基于统计模型的词性标注方法
统计方法将词性标注看作是一个序列标注问题。其基本思想是:给定带有各自标注的词的序列,我们可以确定下一个词最可能的词性。
现在已经有隐马尔可夫模型(HMM)、条件随机域(CRF)等统计模型了,这些模型可以使用有标记数据的大型语料库进行训练,而有标记的数据则是指其中每一个词都分配了正确的词性标注的文本。
基于统计方法与规则方法相结合的词性标注方法
理性主义方法与经验主义相结合的处理策略一直是自然语言处理领域的专家们不断研究和探索的问题,对于词性标注问题当然也不例外。
这类方法的主要特点在于对统计标注结果的筛选,只对那些被认为可疑的标注结果,才采用规则方法进行歧义消解,而不是对所有情况都既使用统计方法又使用规则方法。
基于深度学习的词性标注方法
可以当作序列标注的任务来做,目前深度学习解决序列标注任务常用方法包括LSTM+CRF、BiLSTM+CRF等。
值得一提的是,这一类方法近年来文章非常多,想深入了解这一块的朋友们可以看这里:NLP-progress-GitHub
最后再放一个词性标注任务数据集-人民日报1998词性标注数据集
词性标注工具推荐
Jieba
“结巴“中文分词:做最好的Python中文分词组件,可以进行词性标注。Github地址
SnowNLP
SnowNLP是一个Python写的类库,可以方便的处理中文文本内容。Github地址
THULAC
THULAC(THU Lexical Analyzer for Chinese)由清华大学自然语言处理与社会人文计算实验室研制推出的一套中文词法分析工具包,具有中文分词和词性标注功能。Github地址
StanfordCoreNLP
斯坦福NLP组的开源,支持oython接口。Github地址
HanLP
HaLP是一系列模型与算法组成的NLP工具包,由大快搜索主导并完全开源,目标是普及自然语言处理在生产环境中的应用。Github地址
NLTK
NLTK是一个高效的Python构建的平台,用来处理人类自然语言数据。Github地址
SpaCy
工业级的自然语言处理工具,遗憾的是不支持中文。Github地址
实战
来源于NLP中的 POS Tagging 和Chunking
词性标注是一种监督学习解决方案,它使用前一个单词,下一个单词,首字母大写等功能。NLTK具有获取词性标注的功能,并且在断句分词(Tokenization)过程之后开始处理单词词性。
1 | import nltk |
结果:
1 | ['My', 'name', 'is', 'Jocelyn'] |
1 | ------------------------华丽分割线-------------------- |
结果:
1 | [('My', 'PRP$'), ('name', 'NN'), ('is', 'VBZ'), ('Jocelyn', 'NNP')] |
1 | ------------------------华丽分割线-------------------- |
1 | PRP$: pronoun, possessive |
1 | ------------------------华丽分割线-------------------- |
1 | NN: noun, common, singular or mass |
最流行的标签集是Penn Treebank标签集。大多数已经训练过的英语标签都是在这个标签上训练的。要查看完整列表,请使用此链接。
命名实体识别(NER)
什么是命名实体识别
命名实体识别(Named Entity Recognition,简称NER),又称作”专名识别”,是指识别文本中具有特定意义的实体、主要包括人名、地名、机构名、专有名词等。简单的讲,就是识别自然文本中的实体指称的边界和类别。
命名实体识别的发展历史
NER一直是NLP领域中的研究热点,从早期基于词典和规则的方法,到传统机器学习的方法,到近年来基于深度学习的方法,NER研究进展的大概趋势大致如下图所示。

相关工具推荐

分块(组块分析,Chunking)
来源于NLP中的 POS Tagging 和Chunking
什么是分块
组块分析是从非结构化文本中提取短语的过程。相对于词性标注POS-Tagging来说,POS-Tagging返回了解析树的最底层,就是一个个单词。但是有时候你需要的是几个单词构成的名词短语,而非个个单词,在这种情况下,您可以使用chunker获取您需要的信息,而不是浪费时间为句子生成完整的解析树。举个例子(中文):与其要单个字,不如要一个词,例如,将“南非”之类的短语作为一个单独的词,而不是分别拆成“南”和“非”去理解。
分块与词性标注的关系
组块分析是可以接着POS-Tagging工作继续完成,它使用词性标注作为输入,并提供分析好的组块做为输出。与词性标注的标签类似,它也有一组标准的组块标签,如名词短语(np)、动词短语(vp)等,当你想从诸如位置,人名等文本中提取信息时,分块是非常重要的。在NLP中,称为命名实体识别,举个例子‘李雷的杯子’是分块分出的一个短语,而抽取’李雷’这个人名,就是命名体识别。所以,组块分析也是命名体识别的基础。
实战
有很多库提供现成的短语,如spacy或textblob。NLTK只是提供了一种使用正则表达式生成块的机制。为了创建NP块(名词模式),我们将使用一个正则表达式规则来定义分块的语法。通常我们认为,一个名词词组由一个可选的限定词(dt),后跟任意数量的形容词(jj),然后是一个名词(nn),那么它就应该是名词短语NP(Noun Phrase)区块。
1 | # Example of a simple regular expression based NP chunker. |
结果
1 | [('the', 'DT'), |
1 | ------------------------华丽分割线-------------------- |
结果
1 | (S |
1 | ------------------------华丽分割线-------------------- |
结果
中文 NLP 语料预处理的4个步骤
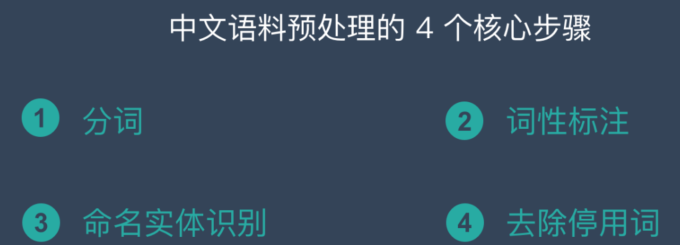
- 中文分词- Chinese Word Segmentation
- 词性标注- Part of Speech
- 命名实体识别-NER
- 去除停用词
词法分析(中文分词、词性标注和命名实体识别)
中文分词、词性标注和命名实体识别都是围绕词语进行分析,统称词法分析 。词法分析的主要任务是将文本分隔为有意义的词语 (中文分词) ,确定每个词语的类别和浅层的歧义消除(词性标注),并且识别出一些较长的专有名词 ( 命名实体识别) 。
对中文而言,词法分析常常是后续高级任务的基础。在流水线式的系统中,如果词法分析出错,则会波及后续任务。
词法分析可以说是自然语言处理的基础任务,目前中文词法分析已经非常成熟。
去掉停用词
对于一个由中文句子组成的列表,现在需要去除一切标点符号、空格、及数字等,仅保留中文并将句子输出为列表。
1 | sentence |
1 | 0 巴林新增3例新冠肺炎确诊病例 累计确诊50例 |
首先加载re和jieba包。
1 | import re |
接下来使用以下代码构造分词去停用词函数,其中chineseStopWords.txt为停用词库。这里的处理逻辑是:先导入停用词库形成列表,接下来对一个单独句子处理,先通过re.findall提取出句子中的每一个单独汉字,再用join函数把汉字连接成没有空格和符号的句子,再用jieba.lcut将句子分词形成列表,这里使用的是精准切割(cut_all = False),最后通过for循环,倒序检查列表的每一个元素,如果这个元素出现在停用词列表中,者将其删除,最后返回这个列表。
1 | stopwords = [i.strip() for i in open('chineseStopWords.txt').readlines()] |
接下来通过apply函数对列表批量分词。
1 | list(map(lambda x: pretty_cut(x), sentence)) |
1 | [['巴林', '新增', '例新冠', '肺炎', '确诊', '病例', '累计', '确诊', '例'], |
信息抽取
词法分析之后,文本已经呈现出部分结构化的趋势 。至少,计算机看到的不再是一个超长的字符串,而是有意义的单词列表(分词结果),并且每个单词还附有自己的词性(词性标注结果)以及一些标签(命名实体识别)。
根据这些分词后的单词与标签,通过信息抽取我们可以抽取出一部分有用的信息。例如通过高频词抽取出关键词;根据词语之间的统计学信息抽取出关键短语乃至句子。
文本分类与文本聚类
将文本拆分为一系列词语之后,我们还可以在文章级别做一系列分析。
把许多文档分类进行整理称作文本分类,例如判断一段话是褒义还是贬义的,判断一封邮件是否是垃圾邮件。
把相似的文本归档到一起,或者排除重复的文档,而不关心具体类别,此时进行的任务称作文本聚类。
句法分析
词法分析只能得到零散的词汇信息,通过句法分析可以得到句子之间的语法关系 。
例如,在一些问答系统中,比如我们问智能语音助手“查询刘医生主治的内科病人”,用户真正想要查询的不是“刘医生” ,也不是“内科” ,而是“病人” 。但这三个词语都是名词,只有通过句法分析清楚他们之间的语法关系才能理清。

语义分析
相较于句法分析,语义分析侧重语义而非语法 。 它包括词义消歧(确定一个词在语境中的含义,而不是简单的词性)、 语义角色标注(标注句子中的谓语与其他成分的关系) 乃至语义依存分析(分析句子中词语之间的语义关系 )。
篇章分析
篇章分析可以自动分析自然语言语篇或者话语的组成结构、句际关系、语句衔接、语义连贯以及交际功能并得到相应内部表示的过程、技术和方法。
简单来说就是从更为广的视角—篇章角度进行分析,自然最为复杂也最为困难,目前很不成熟。
指代消解
指代消解指在文本中确定代词指向哪个名词短语的问题,举个例子:
今天晚上 10 点有国足 的比赛,他们 的对手是泰国队 。在过去几年跟泰国队 的较量中他们 处于领先,只有一场惨败 1-5。
指代消解要做的就是分辨文本中的 他们 指的到底是 国足 还是 泰国队。
其他 NLP 任务
上述的这些任务是 NLP 中最为基础也最为重要的基本任务,除此之外还有一些更加偏向应用、与终端产品联系更为紧密的任务:
- 自动问答,例如 Siri。
- 自动摘要,为一篇长文档生成简短的摘要。
- 自动翻译,例如中文自动翻译英文。
- ⚠️ 信息检索,一般认为信息检索(Information Retrieve, IR)是区别于自然语言处理的独立学科。虽然两者具有密切的联系,但 IR 的目标是查询信息,而 NLP 的目标是理解语言。
语料库
语料库(Corpus,复数为Corpora或Corpuses)定义为:为语言研究和应用而收集的,在计算机中存储的语言材料,由自然出现的书面语或口语的样本汇集而成,用来代表特定的语言或语言变体。
语料库具有以下三个基本特征:样本代表性;规模有限性;机读形式化。‘
中文分词语料库
中文分词语料库指的是由人工正确切分后的句子集合 。最为著名的语料库如《人民日报》语料库。
词性标注语料库
指的是切分并为每个词语指定一个词性的语料 ,每个单词后面用斜杠隔开的就是词性标签。例如:
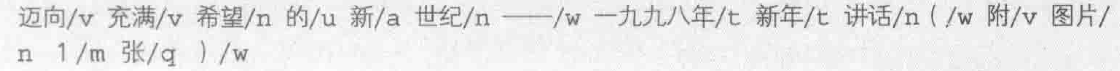
命名实体识别语料库
这种语料库人工标注了一些实体名词以及实体类别。比如《 人民日报》语料库中一共含有人名、 地名和机构名 3 种命名实体:

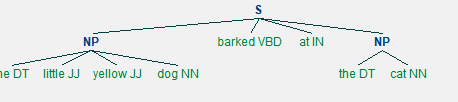
句法分析语料库
这种语料库每个句子都经过了分词、 词性标注和句法标注 ,即标注了单词之间的联系和关系。 例如一个句子可视化后如图所示。
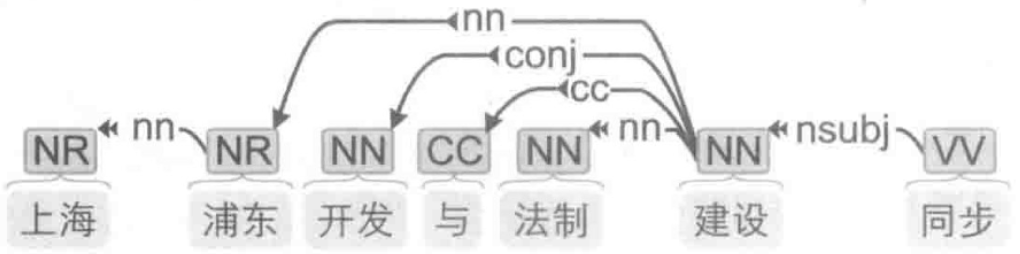
文本分类语料库
指的是人工标注了所属分类的文章构成的语料库,这种语料库标注最为简单,数据量也非常大。
NLP 开源工具
针对前面提到的NLP 的任务的各个流程,网上已经有了很多的开源工具可以直接使用,下边介绍最为主流的几种
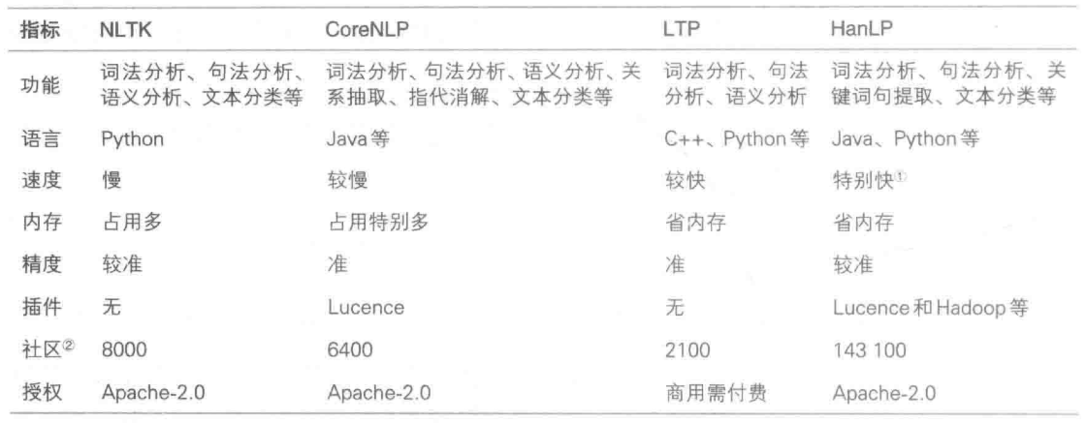
参考
自然语言处理的21个基本概念
NLP(一)基本概念和基础知识
第1章-自然语言处理基础概念
NLP中的 POS Tagging 和Chunking
Python-中文分词并去除停用词仅保留汉字
使用Moses脚本进行数据预处理
moses(mosesdecoder)数据预处理&BPE分词&moses用法总结

